
- CPC: Representation Learning with Contrastive Predictive Coding
- https://arxiv.org/abs/1807.03748
参考资料:
- Code (PyTorch): https://github.com/jefflai108/Contrastive-Predictive-Coding-PyTorch
- Papers with Code: https://paperswithcode.com/method/contrastive-predictive-coding
- 相关博客:
- https://anilkeshwani.github.io/CPC
- https://zhuanlan.zhihu.com/p/129076690
- https://zhuanlan.zhihu.com/p/463867673
- http://home.ustc.edu.cn/~xjyuan/blog/2020/10/19/understanding-of-CPC/
- https://sh-tsang.medium.com/review-representation-learning-with-contrastive-predictive-coding-cpc-cpcv1-8ec7c6e91a8e
- https://sh-tsang.medium.com/review-learning-word-embeddings-efficiently-with-noise-contrastive-estimation-nce-dba1c345c153
CPC (对比预测编码,Contrastive Predicting Coding)提出于 2018 年,当时关于无监督预训练的工作还比较少,CPC 是一种基于对比学习思想的无监督预训练方法,是无监督/自监督学习中重要的开创性的工作之一。
CPC 论文提出了一种通用的无监督学习方法,能够从高维数据(语音、图像、文本等)中抽取出有用的表征信息。论文工作最核心的思想是:在神经网络建模出的隐含空间内,使用建模能力较强的自回归模型,以未来的信息作为预测的目标,来指导进行无监督学习。论文使用一种概率的对比损失函数,帮助模型在隐含空间内,捕捉到对于预测未来最重要最有用的信息。论文同时还使用了负采样的方法。CPC 之前的工作基本都是关注于某一模态(语音、图像、文本)进行评测,而 CPC 能够在以上模态都得到很强的结果。
1. 论文介绍
本文的标题强调的是用 CPC 进行表征学习 (Representation Learning),表征学习最大的难点在于:使用数据的高效性、学习到的表征的稳健性和泛化性。
为了达到稳健性和泛化性,表征学习不应该只关注于某一个具体的监督学习任务。基于有监督学习的表征学习往往就具有这个缺陷。比如预训练一个图像分类的模型,学习到的隐层表征在其他的图像分类任务上能够有很好的迁移效果,但是这些表征缺乏用于非分类任务的细节信息(比如颜色等),所以在其他图像任务(比如图像描述)上表现不好。同样的,对于语音的任务,针对语音识别学习到的表征在说话人分类/音乐风格分类等任务上,也不具有很好的迁移效果。因此,无监督学习面向的是更加稳定和泛化性更好的表征学习。
无监督学习最惯常的策略是预测「未来」「缺失」或者「上下文」的信息,最常见的应用是 word2vec 学习词级别表征向量的工作,比如 skip-gram 是给定一个词预测「上下文」,CBOW 是给定上下文,预测「缺失」的词。这类策略能够取得不错效果的原因:使用相关信息预测「未来」「缺失」或者「上下文」的值时,是条件依赖于相同的共享的 high-level 隐含信息的。
CPC 论文的主要工作包括:
- 将高维数据压缩到一个显著更小的隐层向量空间内,能够使得预测任务的建模更容易;
- 在隐含空间内使用更强大的自回归模型,能够进行未来更长时间范围 (step) 的预测任务;
- 将 word embedding 已经使用的 NCE (噪声对比估计,Noise Constrastive Estimation) 方法引入到损失函数中,使得模型能够端到端训练;
- 将提出的 CPC 模型应用于不同的数据模态,包括:图像、语音、自然语言甚至是强化学习领域,都达到了明显优于当时其他方法的效果。
2. 对比预测编码 (CPC)
2.1 CPC 提出的动机
CPC 的主要思想是在不同部分的高维数据中,对底层共享的信息进行编码,同时去除一些局部噪声和低级别的信息。在高维的时间序列建模任务中,预测下一个时间步 (step) 是对局部信息的建模,当预测更远的未来的信息时,共享的信息量会变得更低,模型需要学习到更全局的信息。这些横跨更长时间步的信息通常对应到更明确的物理意义,比如:语音的音素语调、图像的物体、书中的故事线索等。
对于预测未来的高维数据,MSE/交叉熵等损失函数不太有用,需要使用一些条件生成模型来对数据细节进行重建建模,但是这些条件生成模型计算量过大,会过分关注数据内的复杂关系,而忽略了上下文 context。
举例来说:一张图片通常包含成千上万比特的信息,但是 high-level 的表征(比如类别信息)包含很少(1024个类别才10比特)的信息。论文认为,直接基于现有 context = c,通过 p(x|c) 建模未来的目标 x 这个任务,用于抽取 c 和 x 之间的共享信息是非最优的方法。所以论文提出,将 x 和 c 都通过非线性映射到一个更低维的向量表征空间,映射时最大程度保留 c 和 x 之间的互信息:
简而言之,CPC 希望通过最大化映射后的 c 和 x 之间的互信息,以此提取出共享的信息。
2.2 CPC 结构及方法
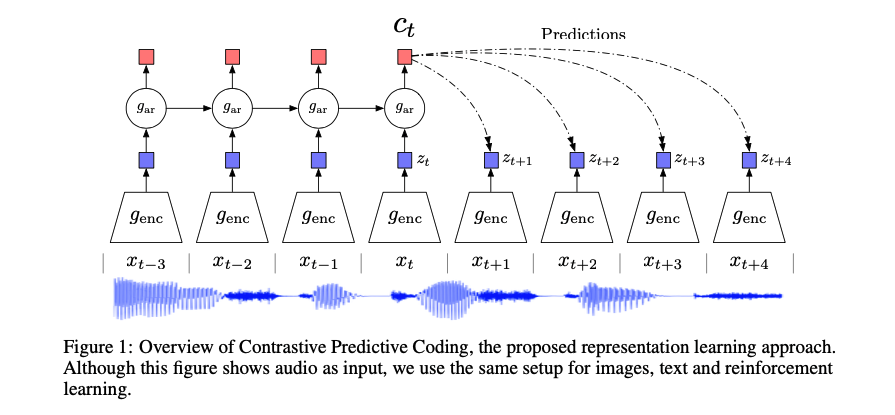
如上图所示,encoder 将每个时刻输入的
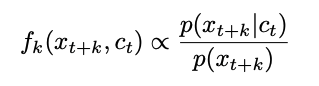
注意:此处的 f 即为密度比,不需要归一化。论文采用的密度比函数是对数双线性的模型,其中
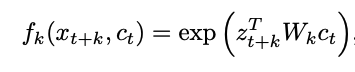
对于 CPC 模型,
- 对于语音识别任务,
的感受野可能不足够捕捉音素层级内容的信息, 包含了历史的 context 的信息,所以常用 作为表征; - 对于其他的序列任务,不需要依赖额外的 context,此时
可能效果更好; - 如果下游任务对于一个序列只需要一个向量表征,比如图像分类,常常将所有位置的
或者 取平均。
论文相当于提出了一个系统的预训练框架,任何 encoder/任何自回归模型都可以引入其中。对于 2018 年发表的本文来说,encoder 选择的是多层 Resnet 卷积构成的网络,自回归模型选择的是 GRU。自回归模型还可以选择带有 mask 的卷积神经网络或者是基于自注意力机制 self-attention 的方法。
2.3 基于 NCE 的损失函数
CPC 的损失函数是基于 NCE (噪声对比估计,Noise Constrastive Estimation) 的,论文称之为 InfoNCE。
给定集合
实际上可以讲这个损失函数视为二分类的交叉熵损失函数,最小化损失函数等价于最大化正样本的概率。
论文在附录中证明了,使用 InfoNCE 作为优化目标,实际上是近似等价于最大化 c 和 x 之间的互信息:
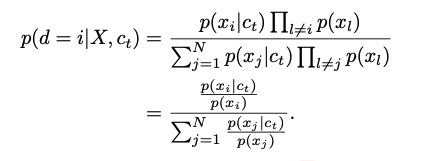

证明的结论是: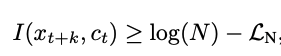 ,最大化互信息,相当于最小化损失函数
,最大化互信息,相当于最小化损失函数
参考的博客原文:https://ankeshanand.com/blog/2020/01/26/contrative-self-supervised-learning.html
在 NCE 的损失函数之下,CPC (Contrastive Predictive Coding) 中的 Contrastive 对比一词,表达的正是正样本和负样本之间的对比。在希望通过 encoder 学习得到的表征空间中,增大某样本与其相近的正样本之间的相似度,降低其与负样本之间的相似度。此处的相似度,在 CPC 的工作中,是通过使用一个双线性的 score 函数来评价。
3. 实验
论文在语音、图像、自然语言处理及强化学习四个方向上都进行了 CPC 的有效性验证。此处主要说明音频领域上的使用方法。
- 数据集:
librispeech 的 100 小时子集。使用 kaldi 获取了音素级别的强制对齐结果;说话人数目:251。
- 模型结构:
encoder 采用的跨步的(strided)卷积网络,输入是 16kHz 的原始波形。卷积的具体参数:5 层,stride 分别为 [5, 4, 2, 2, 2],相当于降采样了 160 倍;卷积核大小分别为 [10,8,4,4,4];隐层结点数均为 512;激活函数使用的是 ReLU。对于 16kHz 的音频,降采样 160 倍后,相当于每秒对应 100 个输入,此时的帧移可以认为是 10ms,和 Kaldi 使用的帧移相同,因此可以和 Kaldi 逐帧的音素对齐结果保持一致。
自回归模型采用的是 GRU,隐层结点数为 256。GRU 在每帧的输入是 encoder 输出的即为前文所述的 context c。基于 context c,训练时需要是未来 k = 12 帧的 z,采用的损失函数为对比损失函数 InfoNCE。
训练时的音频片段长度为 20480 个采样点的窗长;Adam (lr=2e-4) 的优化器;8卡,batch_size=8;一共经过了大约30万次迭代。
实验结果一:分类准确率随 k 的变化
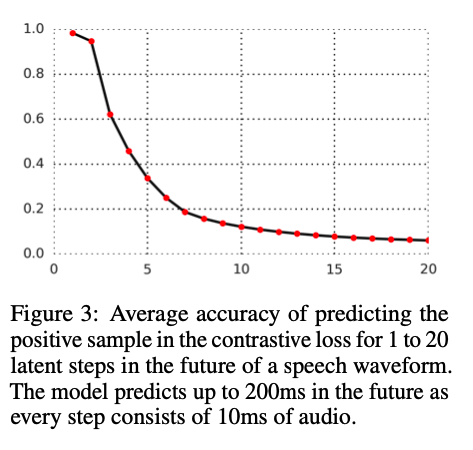
预测未来时不同 k 对应的准确率如上图所示,预测任务随着预测范围更远而变得更难,也与预期的相一致。
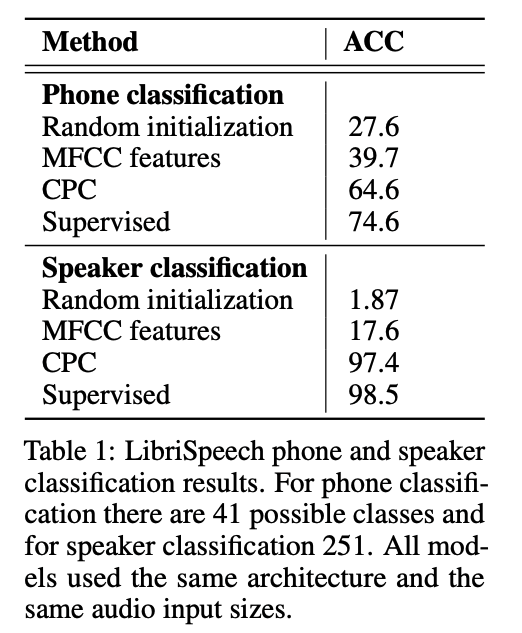
实验结果二:音素分类
对于 CPC 抽取的帧级别的表征,论文使用音素分类任务进行效果的验证。在 CPC 中 GRU 输出的 context c 之上,增加一层线性的分类器,验证抽取的表征的线性可分程度。注意训练线性分类器时,CPC 网络的参数是固定不动的,只相当于一个特征抽取器。线性分类器使用的是多类别的 LR (logistic regression)。
对比实验分别是:baseline 使用 MFCC 特征作为线性分类器输入;天花板,将 CPC 模型和线性分类器的参数进行端到端的联合训练;对比实验,CPC 抽取的特征不是完全线性可分的,所以在线性分类器之前增加了一层隐层,提供非线性变换。
实验结果三:说话人识别
CPC 同样能够达到端到端的有监督学习相近的结果。将 CPC 表征向量进行 tSNE 作图后可以看出,CPC 体现出很好的说话人表征效果。

实验结果四:CPC 表征效果的消融实验
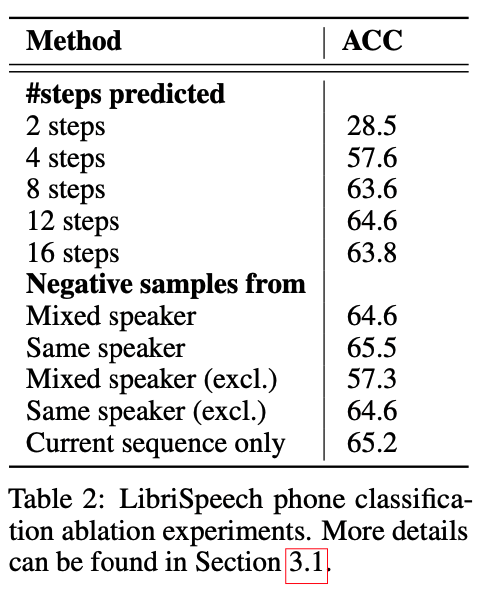
影响因素一:预测的时间范围 k
- 在 k=2 至 12 时,音素分类效果随着 k 的增大而更优,说明了较长的预测范围对于表征的学习有正向作用;但是 k 继续扩大至 16 时,没有进一步的正向作用;
影响因素二:训练时的负样本选择策略
- mixed speaker:负样本来自不同的说话人
- same speaker:负样本来自同一个说话人
- mixed speaker (excl.):负样本来自不同的说话人,但是不包含当前的序列
- same speaker (excl.):负样本来自同一个说话人,但是也不包含当前的序列
- current sequence only:负样本只来自于当前的序列,这个也满足所有的负样本来自同一个说话人
结论:负样本来自同一个说话人 > 负样本仅来自当前的序列 > 负样本来自不同的说话人 = 负样本来自除当前序列外的同一个说话人的音频 > 负样本来自当前序列外的不同的说话人
总结:CPC 将对比预测损失函数和基于自回归的预测编码相结合,基于无监督实现了更优的表征学习方式,后续引申出诸多成功的研究成果。
- 本文标题:语音表征 | CPC:基于对比预训练的语音表征
- 创建时间:2021-03-16
- 本文链接:2021/03/16/2021-02-16_cpc/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!