
- HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis
- https://arxiv.org/abs/2010.05646
Hifi-GAN 的提出在 StyleMelGAN 之前,基于 GAN 的声码器和自回归声码器(如 WaveNet) 或 flow 声码器(WaveGlow) 仍存在一些差距。Hifi-GAN 保持了 GAN 高效/轻量的优点同时,达到了比之前最好的模型 (Wavenet / WaveGlow) 更高的 MOS 指标。
Hifi-GAN 主要关注到音频信号是可以拆分成不同周期的正弦信号的叠加,所以周期性模式的建模对于语音生成(梅尔特征还原成语音信号)的过程是非常重要的。Hifi-GAN 提出了一种判别器组,其中每个小判别器只关注原始波形的一部分周期。同时,Hifi-GAN 在生成器部分设计了另外的模块,采用多个 ResBlock,并行同时关注多个不同长度的信号。具体见下文的细节分析。
Hifi-GAN 的结构
Hifi-GAN 包括一个生成器和两个判别器:多尺度判别器 MSD 和多周期判别器 MPD。
1. Hifi-GAN 的生成器
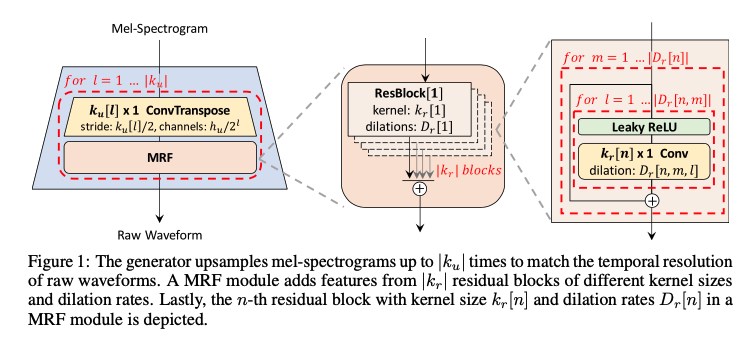
和 MelGAN 系列一样,Hifi-GAN 的生成器也是全卷积结构。输入是梅尔声学特征,经过反卷积操作进行上采样,直到上采样后结果和真实音频的采样点个数在同一数量级。
a) 多感受野融合 MRF
每个反卷积模块后面都跟着一个** Multi-Receptive Field Fusion (MRF) 模块**。
MRF 模块实际上是 Multi-ResBlock,不同 ResBlock 的 kernel size 和 dilation rate 的参数配置不同,相当于空洞卷积的感受野是不同的,故名 multi-receptive fileld,多感受野模块。
每个 ResNBlock 的构成都是:Leaky ReLU + 1d 空洞卷积 + 残差。最终 MRF 模块的输出是全部 ResBlock 输出之和。
2. Hifi-GAN 的判别器
论文认为,语音生成认为的长时依赖非常重要,对于某些音素发音持续时长可能达到 100 ms,对应的 22 k 音频采样点的个数为 2200 个,说明这 2200 个采样点之间是高度相关的,MelGAN 系列的做法是提高生成器的感受野大小。Hifi-GAN 则是从信号的组成角度入手,认为语音信号是由不同周期的正弦信号迭代得到的,周期性是需要特别关注的特性。
Hifi-GAN 共包含两个判别器:多周期判别器 + 多尺度判别器。
a) 多周期判别器 MPD
多周期判别器,Multi-Period Discriminator,MPD。
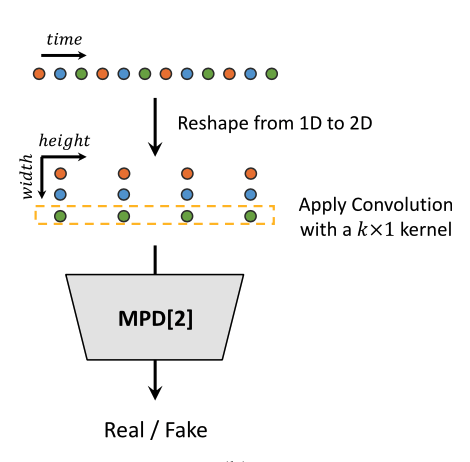
MPD 由一组判别器构成,每个判别器只关注等间隔采样得到的语音信号,此处的间隔记为周期 p。论文选择的周期间隔 p 值有 5 组,分别为 2/3/5/7/11,最小的 5 个质数,尽量避免不同判别器输入的语音采样点的重叠。
具体操作中,设语音信号长度为 T,对于给定的周期 p,先将一维的语音采样点 reshape 成二维,得到 [T/p, p] 的二维表示,再使用二维的 k × 1 卷积即可将语音信号进行划分。这种降采样的操作转换成了卷积网络,相比于提前处理得到降采样的信号,能够让训练过程更加端到端,梯度更新能够被语音信号的每个采样点感知到?
每个 MPD 判别器的结构:多层 (strided CNN + Leaky-ReLU),并且使用了 Weight Normalization。
b) 多尺度判别器 MSD
多尺度判别器,Multi-Scale Discriminator,MSD。
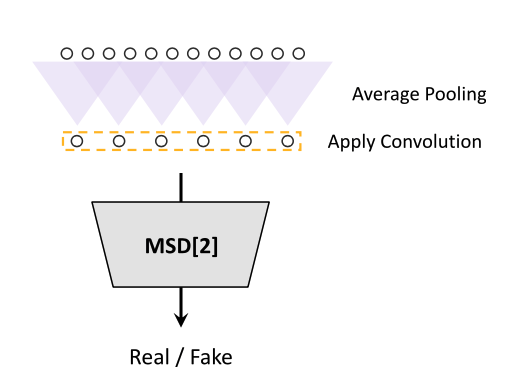
MPD 实际上是对语音信号的采样点进行了直接降采样,然后对降采样后的音频信号,判断是 fake 还是 true。而 MSD 则是进行了平均池化 average pooling,得到的采样点数也是指数递减的。MPD 只见到了不连续的语音采样点;MSD 则是在不同降采样比例(1/2/4 三个 MSD) 下的平均池化后的平滑的语音信号基础上进行的。
每个 MSD 判别器的结构:多层 (strided CNN + GroupConv + Leaky-ReLU)。除了第一个 MSD 判别器外,其他都使用了 Weight Normalization。第一个判别器 MSD 使用的是 Spectral Normalization。
3. Hifi-GAN 的训练
a) GAN 的 Loss
Hifi-GAN 沿用了 MB-MelGAN 的 LS 最小平方损失函数。
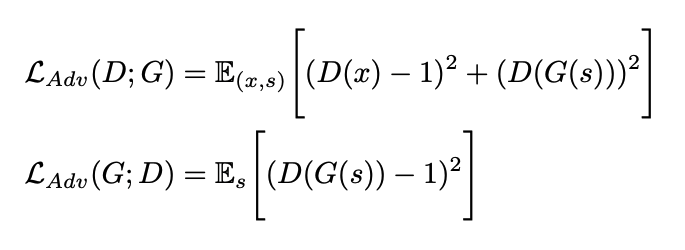
b) 梅尔谱重建 Loss
「生成器生成的语音信号的梅尔谱」与「真实语音信号的梅尔谱」之间的 L1 距离。能够帮助提高人耳的听感效果,同时增加重建损失函数有助于生成器训练稳定性。
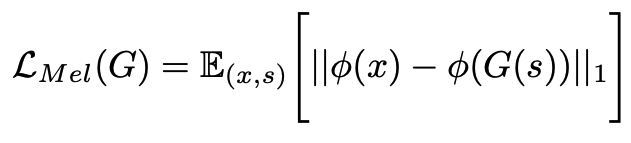
c) Feature Matching Loss
训练生成器时的补充损失函数,判别器参数固定时,真实语音信号和生成的语音信号,在判别器模型中各层的输出都能得到,同样使用 L1 损失函数,使得两个结果之间的差距尽可能小。
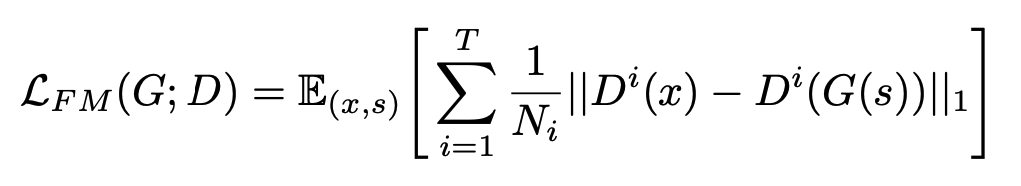
生成器和判别器的损失函数汇总:
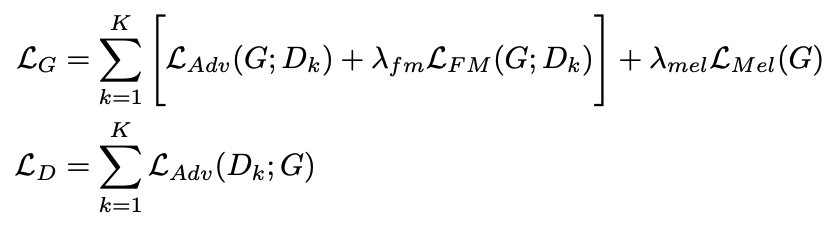
4. Hifi-GAN 的实验结果
a) 不同参数配置的 Hifi-GAN
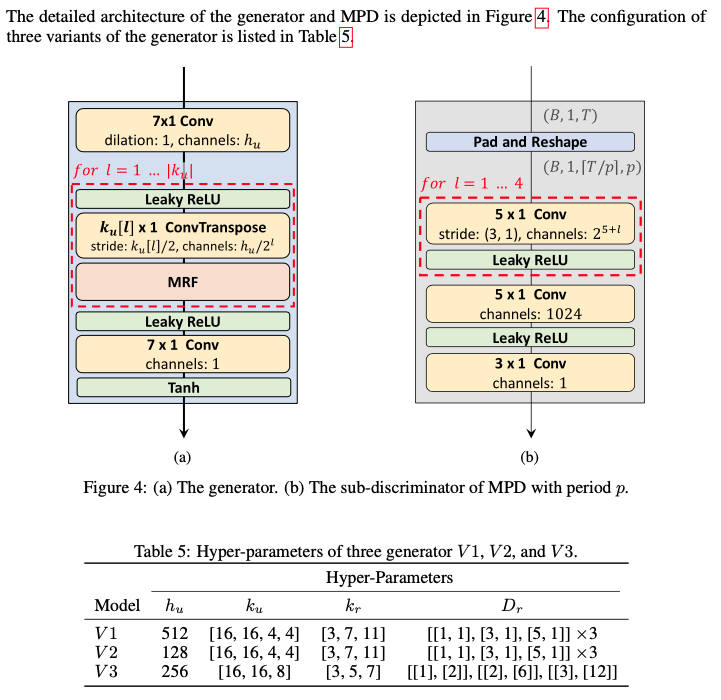
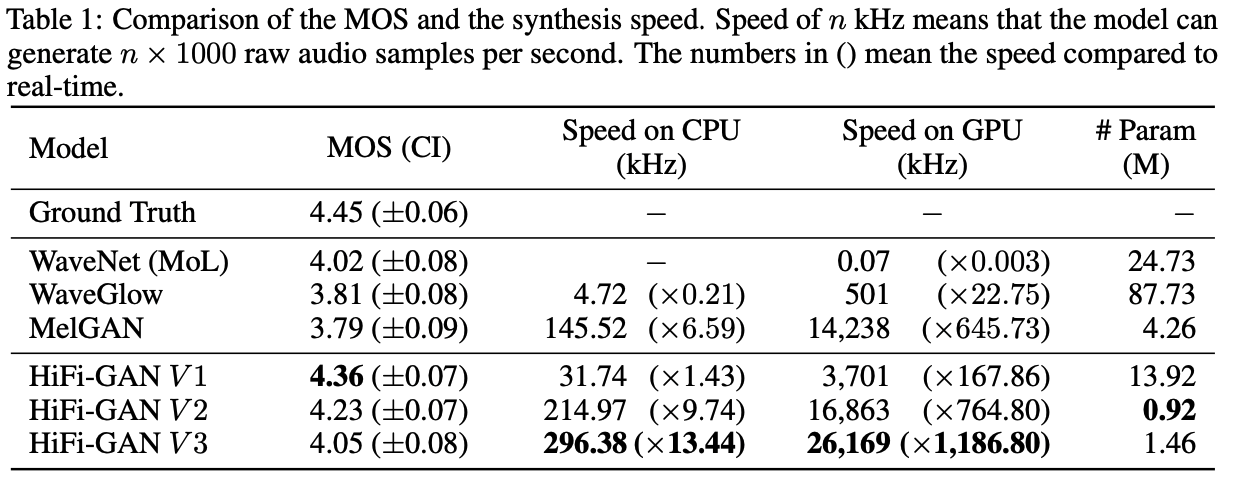
V1: 反卷积的参数:隐含层个数
MRF 的参数:卷积核大小
V2: 参数量更少的版本,
V3: 反卷积的参数:隐含层个数
MRF 的参数:卷积核大小
V3 是人工筛选的更精巧的结构。
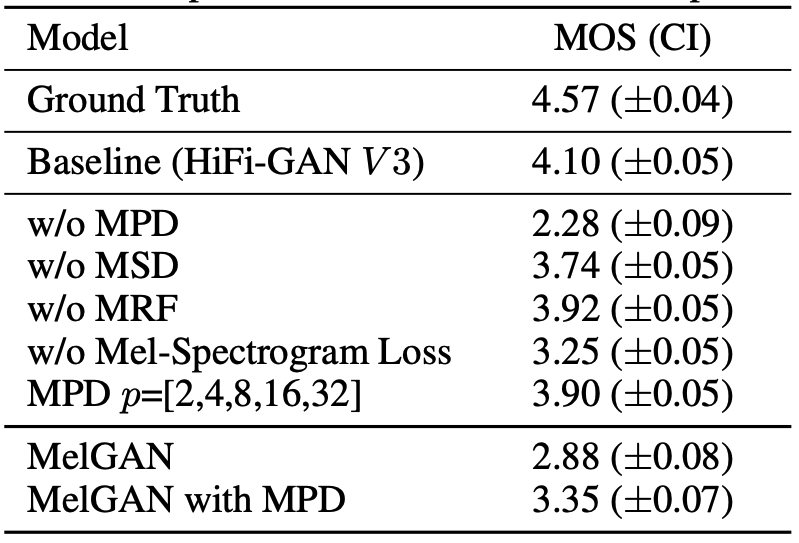
b) 消融实验
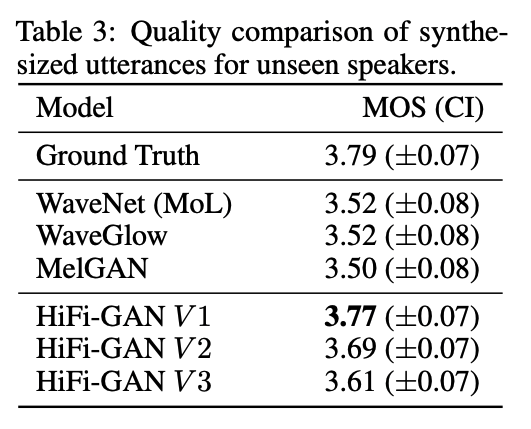
c) unseen speaker 的泛化性
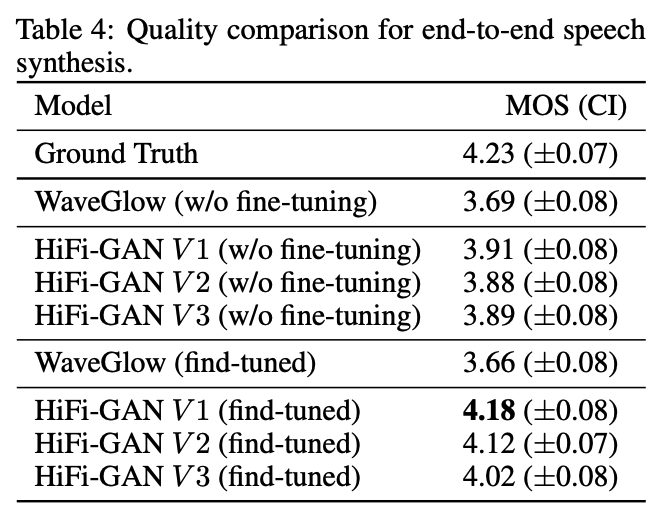
d) 端到端语音合成效果
Tacotron2 用来生成梅尔特征,fine-tuned 模型表示使用 Tactotron2 预测的梅尔特征作为输入,真实音频信号作为目标,对 Hifi-GAN 声码器进行 finetune。
- 本文标题:声码器 | HiFi-GAN:兼顾效率与音质的声码器
- 创建时间:2022-06-22
- 本文链接:2022/06/22/2022-06-22_hifigan/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!