
- MelGAN: Generative Adversarial Networks for Conditional Waveform Synthesis
- https://arxiv.org/abs/1910.06711
论文将 GAN 用于合成高质量语音的声码器,主要从模型结构和训练方法上进行了一些工作。MelGAN 声码器的几个特点:
非自回归
完全卷积
参数量和同等效果的其他模型相比更小
能够在未见过的说话人上泛化性更好
声码器任务的难点在于时间的高精度,16k/24k/48k 代表了每秒语音对应的采样点个数。从时间粒度比较大的帧级别的梅尔声学特征,恢复出原本的高精度的采样率级别的数据点,即为声码器需要完成的任务。
声码器可以分为:信号处理法、自回归声码器、非自回归声码器三大类。
- 信号处理声码器
- Griffin-Lim 算法:声学信号经过 STFT 之后的序列,经过 Griffin-Lim 算法可以解码得到原始的时域信号,但是会引入较强的机器感,效果很一般
- WORLD 声码器:提取关键的声学特征,采取一系列复杂的信号处理方法进行处理
- 自回归神经网络声码器
WaveNet :完全卷积的自回归声码器模型
SampleRNN:使用 multi-scale 的 RNN 用来生成波形
WaveRNN:更简单的单层 RNN 结构,同时采用稀疏化、Subscale 等操作,提升了合成速度
总结:自回归声码器的最大问题是推理速度太慢,和下文的非自回归模型相比不够高效
- 非自回归神经网络声码器
- 特点:高度并行化、能够更充分利用 GPU 等硬件
- Parallel Wavenet / Clarinet:基于蒸馏的思想,将自回归声码器使用基于 flow 的卷积模型进行蒸馏,蒸馏往往基于输出分布的 KL 散度作为目标,往往还增加了一些其他损失函数,比如感知 loss
- WaveGlow:基于 flow 的生成模型,模型是非自回归的,但是效果好时模型参数量较大,训练时间长,所以实际应用的代价较高
- 论文的主要贡献
- 提出 MelGAN,使用非自回归的卷积网络进行音频的波形生成任务:不需要蒸馏自回归模型,也不需要 GAN 以外的其他损失函数 (比如感知 loss)
- 在语音/音乐合成等任务上,更快的 MelGAN 的效果可以替代自回归的模型
- 速度得到明显提升,是 WaveGlow 的 10 倍
MelGAN 细节说明
基于之前对 GAN 的描述,MelGAN 的构成也是包括:生成器、判别器及训练目标这三个关键部分。
1. MelGAN 的生成器
a) 网络结构
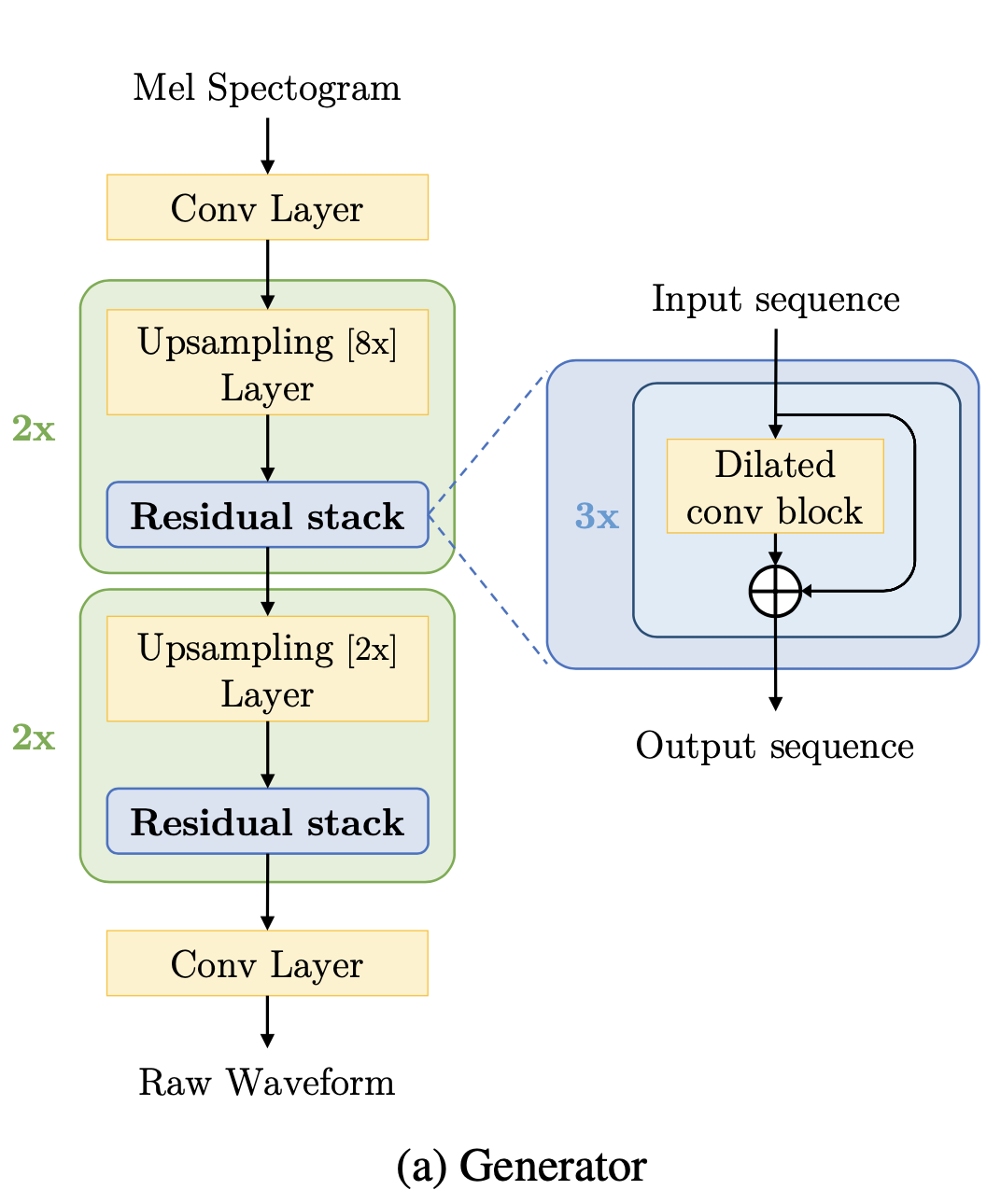
生成器部分采用完全卷积的结构,输入是梅尔谱特征 s,输出是原始的波形 x。梅尔谱特征是帧级别的,帧移通常为 10 ms,所以 1s 音频对应于 100 帧的梅尔特征;但是音频采是 24k Hz 或者更高采样率,所以梅尔特征还原为采样点粒度时,需要进行上采样。论文使用的是多层「转置卷积层/反卷积层」进行上采样操作。反卷积层是上采样的关键,每个反卷积层都紧接着多层空洞卷积构成的残差模块。
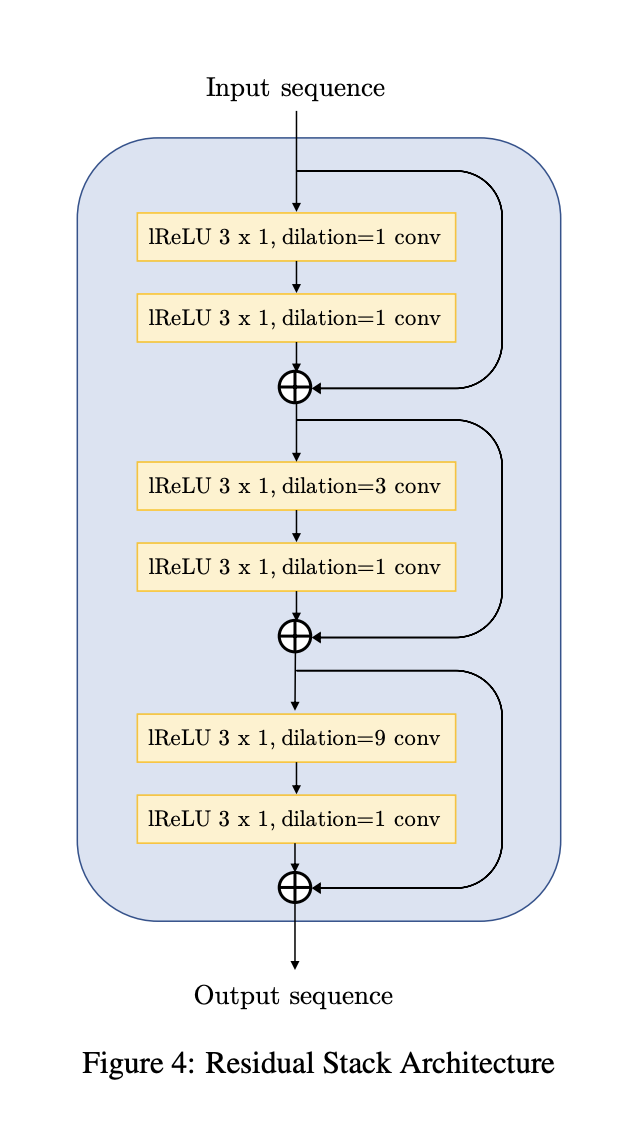
下图给出了 Residual Stack 的具体结构:
b) 关于噪声输入
在 GAN 的基础知识中,生成器需要一个噪声 z 作为输入;现在的生成器输入是梅尔声学特征,论文对比了输入是否增加噪声作为额外输入,发现差别很小,所以不需要增加噪声向量作为生成器的输入。对于生成任务来说,因为是一对多的映射任务,所以往往需要额外的噪声引入生成所需的多样性信息;但是本论文和前人的工作都印证了一点:当输入的条件信息(此处为梅尔声学特征)属于强信息时,噪声输入并不重要。事实上,几乎在之后全部基于 GAN 的声码器工作中,生成器都移除了对噪声向量输入的依赖。
c) 引导感受野 (扩充感受野)
在图像生成领域,相邻的像素之间是高度相关的,因为感受野是高度重叠的。对于音频领域,序列粒度很小,实际上在更广的时间步长范围内都应该是相关的,因此:论文在上采样之后层之后,增加了多层空洞卷积和残差结构,使得上采样之后的输出,对应的输入是高度重叠的。个人理解是卷积层输出对应的输入信息的感受野得到了扩充。实际上,多层空洞卷积层对应的感受野是随着卷积层数的增加而指数级扩充的。感受野的高度重合,实际上更符合音频领域较长时间步内的相关性高的特性。
d) 棋盘效应
反卷积的常见问题就是棋盘效应,主要体现在模式的重复性。但是可以通过仔细选择 kernel-size 和 stride 来解决:kernel size 需要是 stride 的整数倍,dilation 空洞率需要是 kernel size 的幂指数。整个反卷积操作的过程相当于「开枝散叶」的过程,kernel-size 是每次分叉的个数,每个 kernel size 再进行分叉。
256x upsampling is done in 4 stages of 8x, 8x, 2x and 2x upsampling.
Each residual dilated convolution stack has three layers with dilation 1, 3 and 9 with kernel-size 3, having a total receptive field of 27 timesteps.
e) Normalization
MelGAN 同时强调了 **Normalization **的重要性,图像生成的条件 GAN 通常使用 instance norm;但是在音频生成领域,instance norm 会抹除掉 pitch 信息,导致生成的音频有金属感。Spectral Norm 同样效果不好,相当于在判别上强加了 Lipshitz 条件,论文认为这会影响 feature matching 的目标训练。
论文给出的效果最好的 normalization 是 weight normalization,并不对判别器产生限制。论文生成器和判别器中所有层都用的 weight norm。
2. MelGAN 的判别器
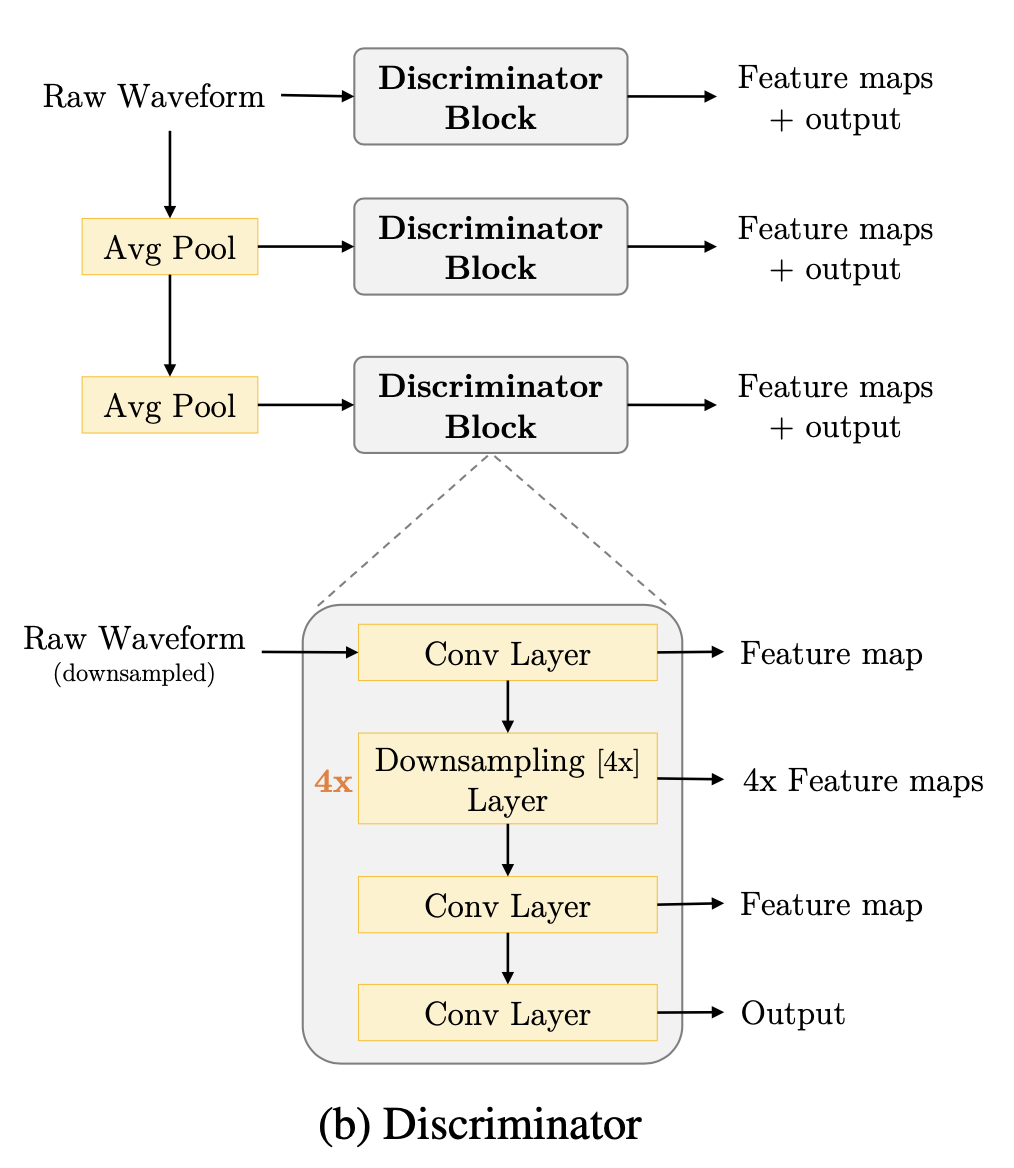
a) 多尺度结构
生成器采用的是多尺度结构,3 个完全相同的网络,只不过输入的音频是不同尺度上的(相当于是不同的帧率)。三个判别器分别为 D1、D2、D3,D1 处理的是原始音频帧率的采样点,D2 处理的是 2 倍降采样之后的音频采样点,D3 处理的 4 倍降采样后的采样点,处理的音频采样点帧率不同,可以称之为不同的尺度(多尺度结构)。
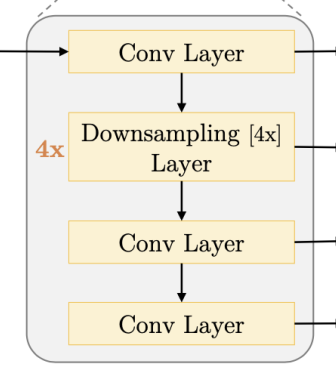
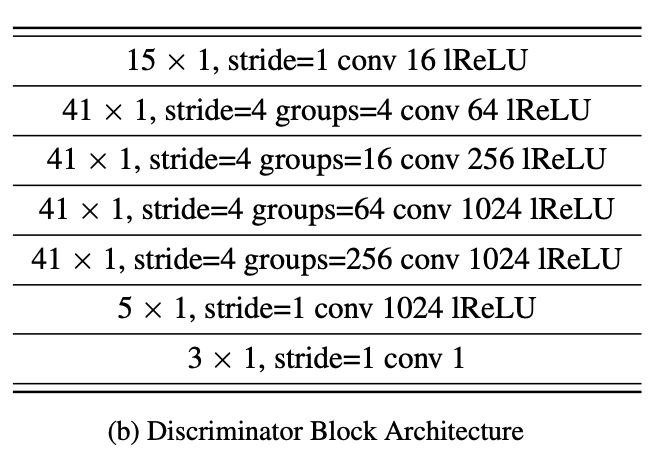
降采样的方法:stride 平均池化,2 倍降采样的尺度上,相当于每隔 2 个数取 n 个数的平均值作为池化后的数值,此处 n 取值为 4。使用多尺度结构的思想:音频的不同尺度是有对应不同频域分布的,采样率越低,音频信号的变化(频域范围)越小,所以相应的判别器会偏向于学习低频的成分。因此,采用多尺度结构相当于让模型学习音频信号的不同频率范围。
b) 基于窗的目标函数
判别器本来是需要判别一整条音频(不论是真实音频还是生成器生成的音频)是生成的还是真实的。但是 MelGAN 的判别器是在加窗的音频 chunk 上进行判别的,相当于对音频进行了分块处理。加窗分块时也保留了重叠区域。加窗处理有很多优点:能够捕捉到关键的高频结构、group 卷积所需的参数量更少、运行更快速而且还能方便地应用在不等长的音频上。
3. MelGAN 的训练目标
a) GAN 损失函数
MelGAN 使用的 hinge loss 版的目标函数,论文也和 LS-GAN 进行了对比,发现 hinge loss 效果稍微好一点。s 表示条件输入的梅尔特征,x 表示真实的波形,z 表示生成器输入的噪声(该论文最终没有用到 z)。
Hinge Loss 对应于生成器和判别器的具体损失函数为:
i. 判别器:
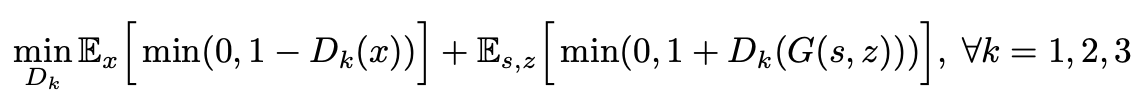
对于每个尺度下的生成器,都对应于两部分损失函数:第一部分是最大化真实样本的输出值,值最大为1;第二部分是最小化生成样本的输出值,值最小为 -1。
ii. 生成器:
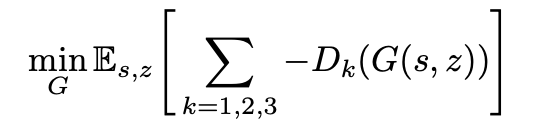
生成器是最大化「生成样本对应于三个判别器上的输出值之和」。
b) 特征匹配损失函数 feature matching
和「GAN 的基础知识」中提到的特征匹配方法类似,目标都是使得:生成样本和真实样本经过判别器 D 的某些层后的输出保持相近。此处使用的是 L1 loss:
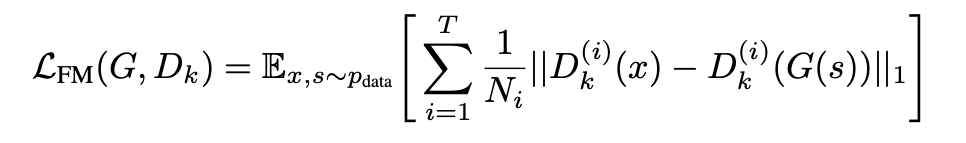
feature matching 和感知 loss (perceptual loss) 是类似的。论文是将 feature matching 用在了判别器 D 的所有中间层上。
注意:这个 feature matching 是在 D 参数固定的情况下,优化 G 时补充的损失函数;所以在优化 D 时没有这个新目标函数,就按 GAN 的原始交叉熵损失函数来训练即可。所以最终优化生成器 G 的完整损失函数为:
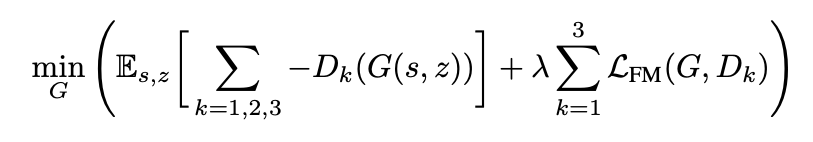
MelGAN 的相关实验
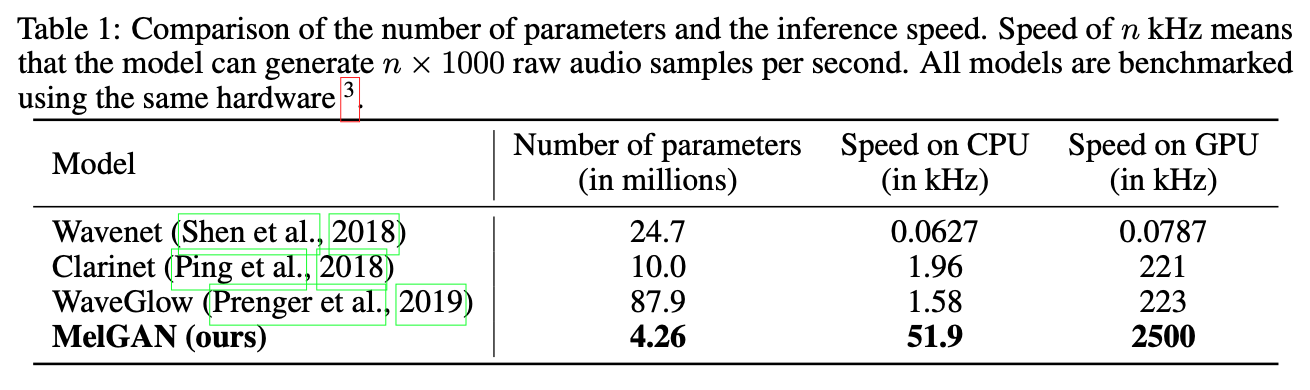
1. 参数量和生成速度对比
2. 消融实验
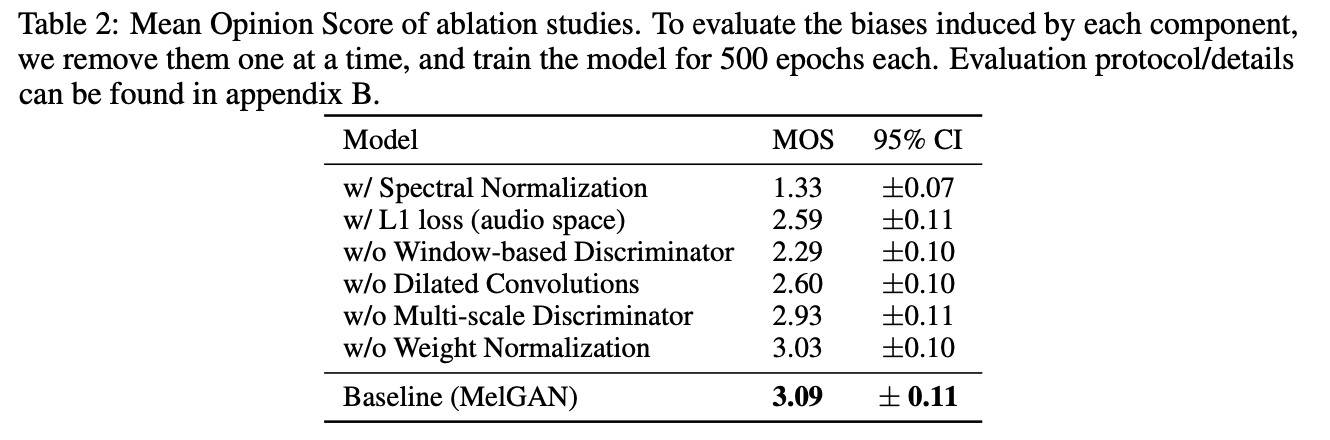
- weight normalization + dilation conv stacks:去除后高频有问题
- 只用一个判别器,不用多尺度,会合成金属感声音,尤其是在呼吸声部分;甚至会导致跳过部分声音片段
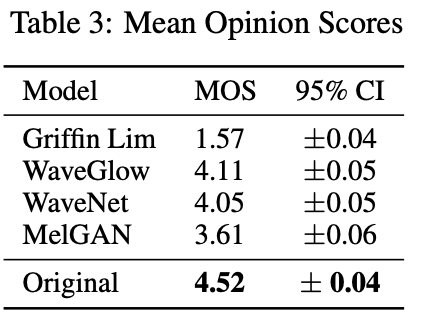
MOS 对比结果中,MelGAN 相比于参数量大的 WaveGlow 和非自回归的 WaveNet,还是存在一定的差距,之后其他论文在 MelGAN 的基础上进行了更进一步的优化。
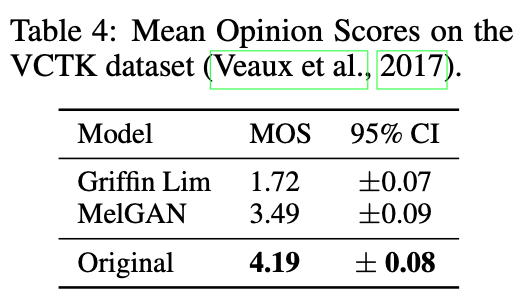
3. 端到端语音合成实验
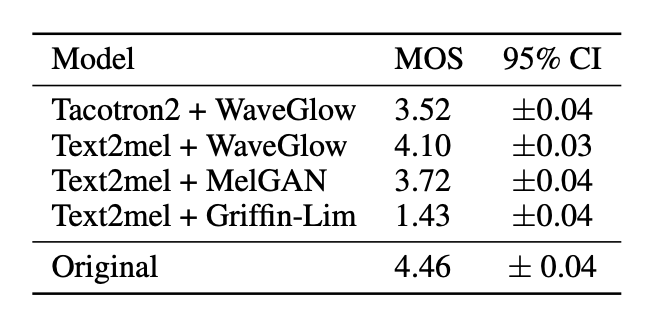
结论:MelGAN 效果不错,但是相比于 WaveGlow 还有较大的提升空间。
- 本文标题:声码器 | MelGAN:高质量语音合成声码器
- 创建时间:2022-07-09
- 本文链接:2022/07/09/2022-07-09_melgan/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!