
- Multi-band MelGAN: Faster Waveform Generation for High-Quality Text-to-Speech
- https://arxiv.org/abs/2005.05106
本文相当于在 MelGAN 的工作基础上结合了 Multi-Band 的方法。Multi-Band 的思想在 Multi-Band WaveRNN 工作中就有所涉及。本论文相当于将这一思想迁移到了 MelGAN 上,并进行了额外的更改。
相关工作
- 关于Multi-Band:
Multi-Band 之前被应用于自回归的 WaveRNN 声码器上,主要思想是:将原始的音频划分成四个子带 sub-band,这四个子带共享模型参数,同时对四个子带的语音信号进行预测,然后基于信号处理的方法,将四个子带的信号还原为原始的全频带信号。Multi-Band 给 WaveRNN 带来了两倍以上的加速。
- 关于训练的辅助 loss:
在基于 GAN 的声码器中,训练生成器时都会使用一些额外的损失函数,比如:Parallel WaveGAN 使用的是 multi-resolution STFT,MelGAN 使用的是 Feature Matching。
论文的主要贡献点:
增加了生成器的感受野,扩充为原来的两倍左右,能够有效提高合成音质;
将 MelGAN 的 Feature Matching 替换成了 Multi-Resolution STFT 损失函数;
将 MelGAN 修改为 Multi-Band 形式的,生成器用于生成不同 sub-band 子带的信号,然后使用信号处理的方法将多个子带信号合成完整信号,再作为判别器的输入。将子带的损失函数和全频带的损失函数结合,也能够提升合成质量。
本工作的亮点是将 MultiBand 应用于基于 GAN 的声码器上,能够有效减少模型参数量和计算复杂度,在 CPU 上能够达到 0.03 的实时率。
Multi-Band MelGAN
1. MelGAN 回顾
本文给出的 MelGAN 训练使用的是 LS-GAN 对应的最小平方损失函数:
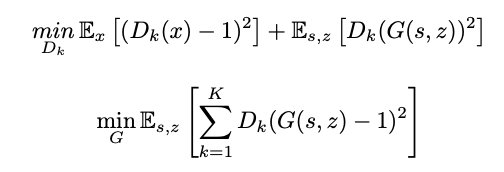
Feature Matching 特征匹配损失函数,在训练生成器 G 时增加的损失函数:
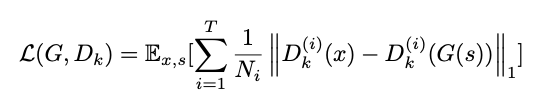
最终训练生成器的损失函数:
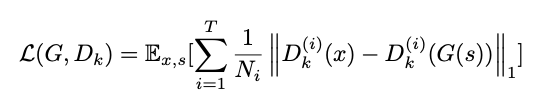
2. Multi-Resolution STFT
本文使用的 STFT 损失函数,相当于一个度量两个音频相似程度的 metric。先补充 STFT 的知识点:
STFT mystft(x, win, hop, nfft, fs) 由一组参数来决定。对于给定的语音信号,计算其 STFT 结果,除了用到语音信号的采样率外,还需要三个参数:win 代表窗长,hop 代表步长(每次窗移动时跳过的采样点个数),nfft 代表 FFT 的大小。一组固定的参数下,计算 STFT,相当于单精度 single-resolution 的 STFT。
先以单精度的 STFT为例,假设
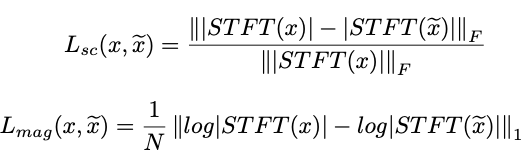
所谓的多精度 STFT,指的是进行多组不同参数的 STFT 分析,得到不同的结果。损失函数是这些 STFT 损失函数的平均值:
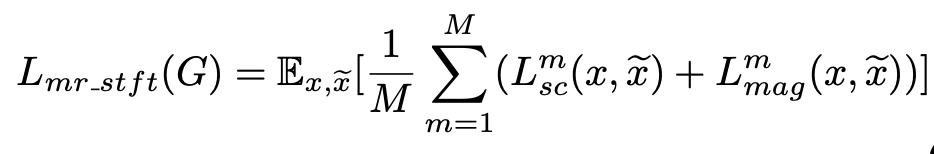
当 x 是全频带的语音信号时,该公式表示的就是全频带的生成器的损失函数,记为: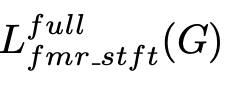 ;如果 x 是自带的语音信号,则对应记作
;如果 x 是自带的语音信号,则对应记作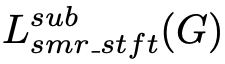
本文将 Feature Matching 替换为 MR-STFT 损失函数后,训练生成器的目标函数为:
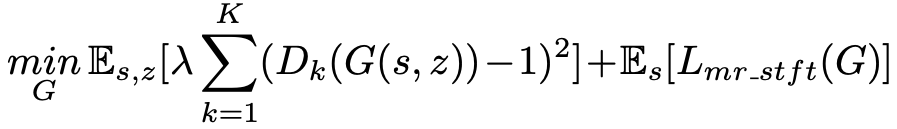
3. Multi-Band 的解读
a) 各子带目标信号的获取:基于分析滤波器 (analysis filter) 进行子带划分,得到各子带的波形信号
b) 模型预测:梅尔特征输入生成器,同时预测各个子带的语音信号 (训练目标是 分析滤波器 划分子带之后的信号)
c) 合成滤波器得到全带信号:基于合成滤波器 (synthesis filter) 将子带的信号合成全带的信号
注意:
a) 和 b) 之间的信号可以用来计算各个子带的 MR-STFT 损失函数;c) 和原本的语音信号可以计算全带的 MR-STFT 损失函数。所以最终的 MR-STFT 可以表示为:
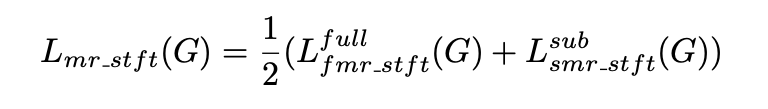
另外,划分和合并自带所用到的分析滤波器和合成滤波器,都是使用的 PQMF 方法,后续会补充学习。
参考文献:Near-perfect-reconstruction pseudo-QMF banks
论文链接:https://ieeexplore.ieee.org/document/258122
实现代码:https://github.com/kan-bayashi/ParallelWaveGAN/blob/master/parallel_wavegan/layers/pqmf.py
参考博客:
- [https://andrew.gibiansky.com/pqmf-subband](https://andrew.gibiansky.com/pqmf-subband/) - [https://andrew.gibiansky.com/pqmf-sub-band-coding-for-neural-vocoders-part-2](https://andrew.gibiansky.com/pqmf-sub-band-coding-for-neural-vocoders-part-2/)
4. Multi-Band MelGAN 的训练流程
初始化 G 和 D 的参数
使用 MR-STFT 损失函数预训练 G 直到 G 收敛 (采用预训练的方式帮助模型更好收敛)
交替训练 G 和 D 直到 G 和 D 收敛
实验细节
1. 模型结构和实验参数
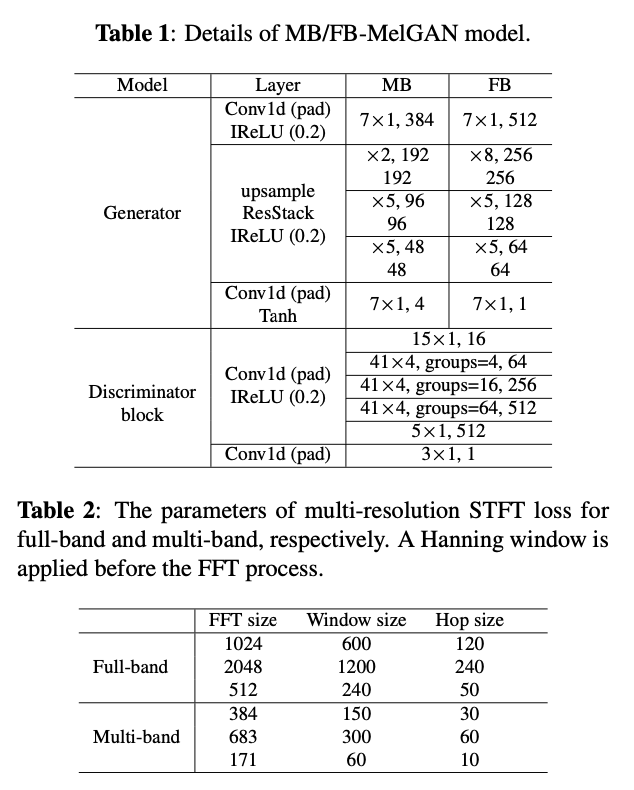
实验数据:data_baker 中文女生音色的音频,12小时,留出 20 条测试音频,50 ms 帧长,12.5 ms 帧移,1024 点 FFT。梅尔特征进行了正则化分布(标准化),20个中国人进行 MOS 评测;
PQMF (Pseudo-QMF) 是使用的有限冲激响应滤波器,阶数为 63,划分为4 个子带;
在生成器上采样中间的 ResStack 层上,本文增加了层数,从而增加了感受野,达到 81 个时间步
2. 消融实验结果
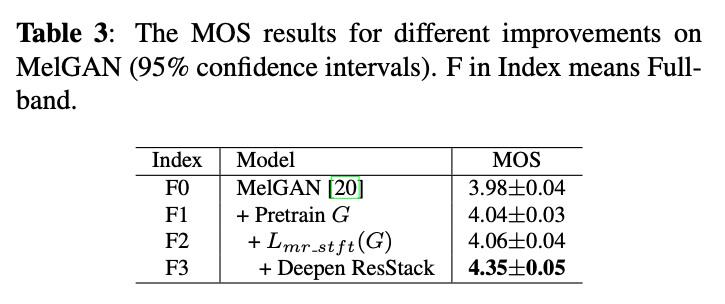
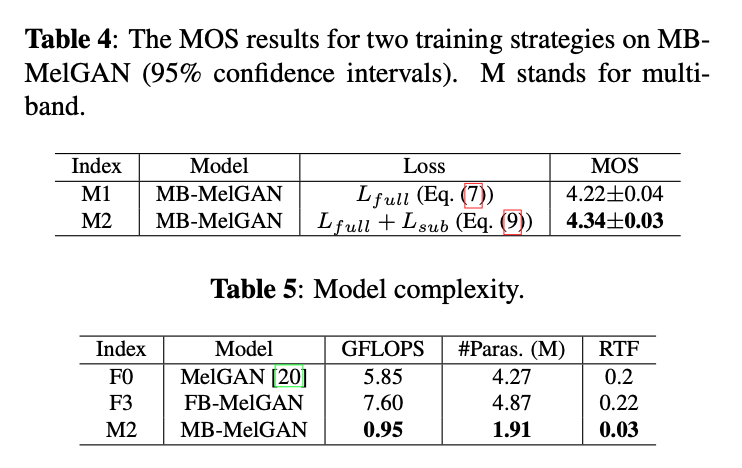
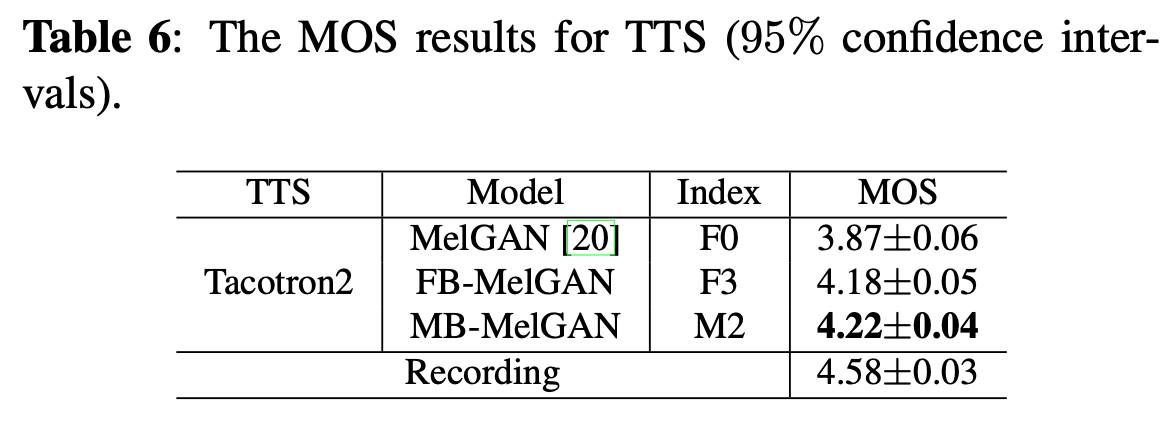
3. 语音合成实验
- 本文标题:声码器 | Multi-Band MelGAN:引入多频带建模
- 创建时间:2022-07-18
- 本文链接:2022/07/18/2022-07-18_multiband_melgan/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!