
- StyleMelGAN: An Efficient High-Fidelity Adversarial Vocoder with Temporal Adaptive Normalization
- https://arxiv.org/abs/2011.01557
基于 GAN 的声码器 (MelGAN 、 Parallel WaveGAN) 等轻量级模型,在合成质量上与真实音频还是存在一定的差距。本文提出的 Style MelGAN 能够在保持 GAN 的轻量级+非自回归(速度快) 的优势同时,得到高质量的合成音频。StyleMelGAN 的几个特点:
- 论文使用时间适应性正则 (Temporal Adaptive Normalization),将目标音频声学特征建模成低维噪声向量;
- 论文提出多个随机窗判别器 (multiple random-window discriminators),对抗性地对语音信号进行评估,同时使用多尺度的频谱重建 loss 进行正则约束,能够达到更高效的训练。
更加细节化的表述:
- 目标音频的梅尔特征作为合成过程的条件输入,将梅尔特征插入到每个生成器的 block 中,插入方法是通过 Temporal Adaptive DE-normalization (TADE),最早是在图片合成任务中使用的。
参考文献:Semantic Image Synthesis with Spatially-Adaptive Normalization
- 判别器 D 的训练 loss 是四个判别器之和,分别对应于音频信号的不同频带,这四个判别器的训练过程中不以音频的声学特征作为额外输入;音频信号是采用随机窗进行采样的。
参考文献:High Fidelity Speech Synthesis with Adversarial Networks
StyleMelGAN 工作的主要贡献:
- 基于 TADE 层,将音频的声学特征作为语音合成的条件输入 (实际上就是输入);
- 随机窗判别器 + 多尺度频谱重建损失函数;
- 主观+客观双重评价指标,证明 Style-MelGAN 能够达到 SOTA 的合成效果。
Style-MelGAN 细节说明
1. StyleMelGAN 的生成器
生成器的输入:128 维的服从高斯分布的随机噪声向量,条件输入:音频的梅尔特征。
使用 Temporal Adaptive DE-normalization (TADE) 层将梅尔特征条件输入到生成器模块,TADE 层是基于「正则化激活 map」的线性调制实现的。调制的参数包含 γ 和 β,这两个是从条件输入的声学特征中学习得到的。
条件输入的声学特征被加入到生成器的各个层中,所以在不同的上采样阶段,音频信号的信息都进行了保留。
Temporal Adaptive DE-normalization (TADE) 的具体结构:
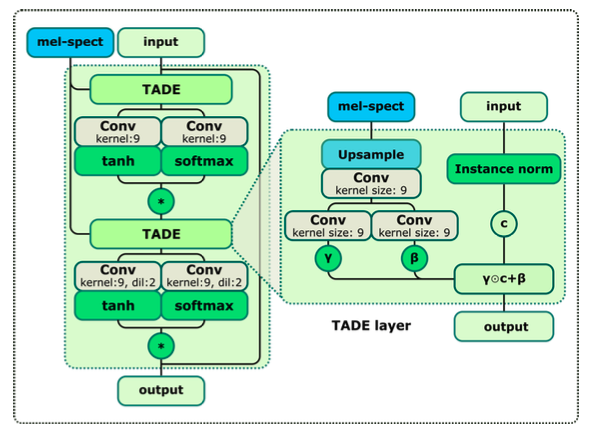
1) TADE 层的结构
a. 两个输入,分别是随机噪声和梅尔谱特征:
b. 随机噪声向量使用 instance norm 得到 content 向量 c,c 经过逐元素的线性函数 γ⊙c+β 得到一部分输出;
c. γ 和 β 两个参数则是基于梅尔谱特征得到的,是经过上采样+两层卷积得到;
d. instance norm + 线性函数 体现了 style transfer 的过程,是生成器的核心部分;
2) TADEResBlock 的结构
a. 一层 TADE 的输出,复制两路,一路经过卷积后经过 tanh 激活,另一路经过卷积后经过 softmax 计算,然后这两路的结果相乘,该操作称为:softmax-gated tanh,比 ReLU 激活函数相对更好,能够减轻音频生成的人造痕迹;
参考文献:Analysis by Adversarial Synthesis - A Novel Approach for Speech Vocoding
论文链接:https://www5.informatik.uni-erlangen.de/Forschung/Publikationen/2019/Mustafa19-ABA.pdf
b. 经过 softmax-gated tanh 后的输出作为下一 TADE 层的输入,梅尔谱特征也作为 TADE 的条件输入;
c. 同时 TADEResBlock 还引入了残差,在模块的输出上,叠加了输入的噪声向量。
3) StyleMelGAN 的生成器结构
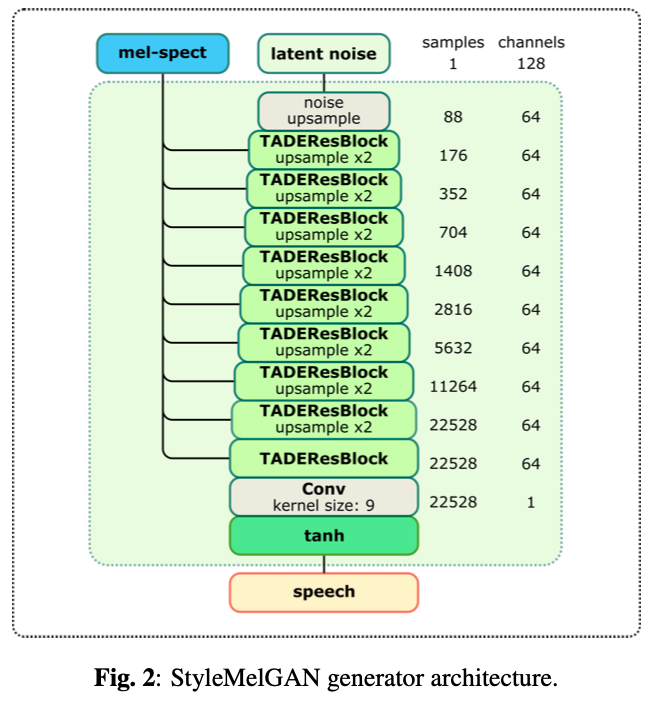
整个生成器包含了 9 个 TADEResBlock,其中前 8 个都进行了上采样,每层上采样倍数为 2,最终上采样倍数为 2 的 8 次方 = 256 倍。最后经过一个不上采样的 TADEResblock,以及 Conv + tanh 激活,最终 channel 数为 1。
2. StyleMelGAN 的判别器
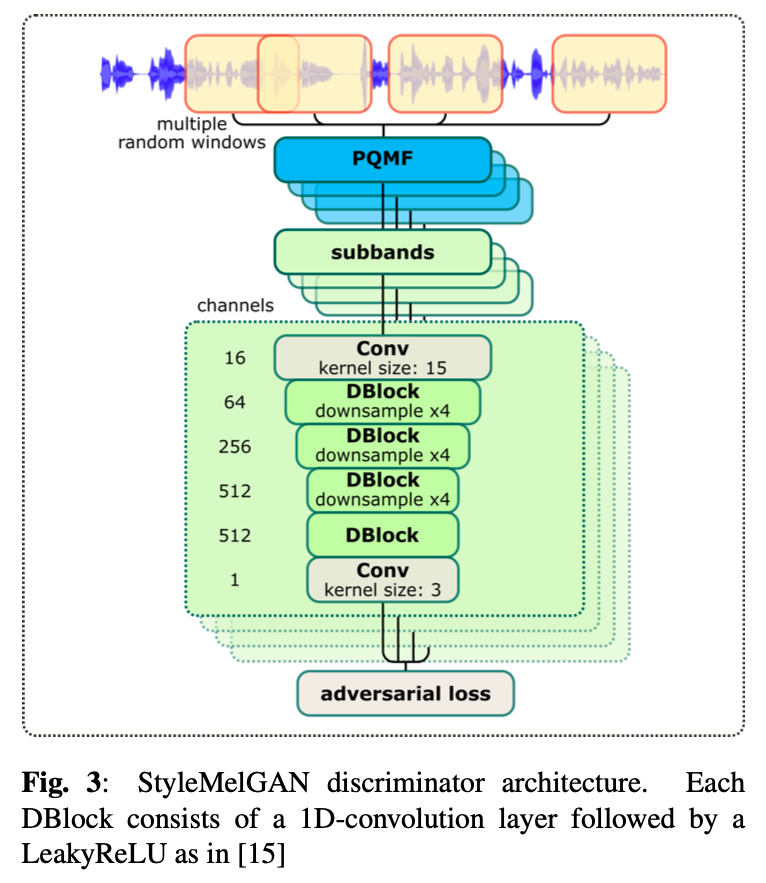
StyleMelGAN 的判别器相当于加强版的 Multi-Band MelGAN,实现了在时域和频域两个维度上的多精度。对于 Multi-Band MelGAN,主要是用「分析滤波器」划分成多个子带,相当于频域上的操作。对 StyleMelGAN 的判别器来说,主要有以下特点,下面以 4 个随机窗的情况为例说明:
- 先从输入音频中,随机选择 4 个窗的音频信号;
- 对于每个窗的音频信号,都使用 PQMF 的分析滤波器进行子带划分,划分为 M 个子带;
- 4 个窗的采样点个数分别为:512,1024,2048,4096
- 4 个窗对应的子带数 M 分别为:1,2,4,8
- 对于 4 个随机窗的语音信号,来源既可以是真实语音信号,也可以是生成器生成的语音信号,分别对应 fake/true 的判别器标签,判别器计算各个随机窗的对抗损失函数之和,用来优化判别器。
3. StyleMelGAN 的训练流程
- 预训练生成器:和 Multi-Band MelGAN 一样,先用 MR-STFT 损失函数预训练 G 直到 G 收敛;虽然这么训练的结果能够合成有调的语音信号但是在高频有杂音,但是作为 GAN 生成器的初始化是足够了,能够从谐波结构中更好地进行后续学习,而不至于从随机参数从头开始学习(这样难度很大);
- GAN 的训练:本文使用的是 hinge loss 作为 GAN 的对抗训练损失函数,生成器的训练损失函数为:
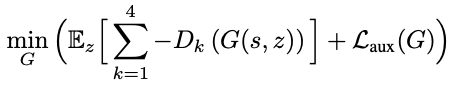
生成器的目标是:最大化「生成样本对应于三个判别器上的输出值之和」,同时最小化频谱重建损失函数
在生成器 G 和判别器 D (各个 D) 的全部卷积操作后,都使用了 weight normalization 操作。
Style-MelGAN 实验
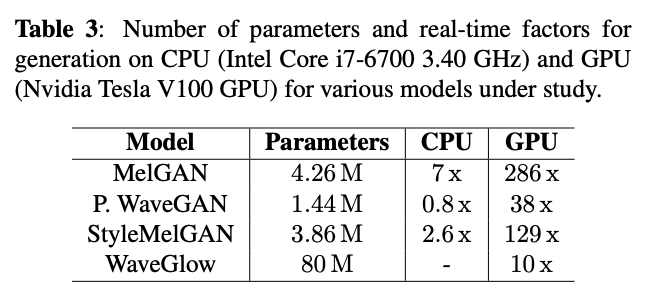
- 客观评价指标
conditional Fréchet Deep Speech Distances (cFDSD),数值越小越好
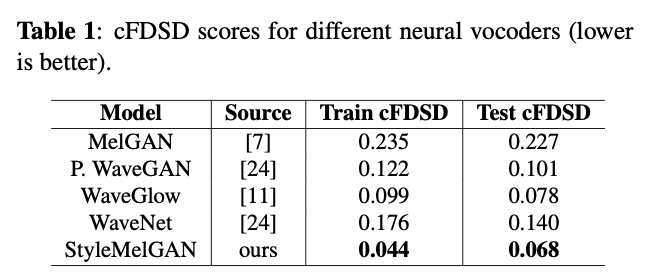
声码器参数量和推理速度
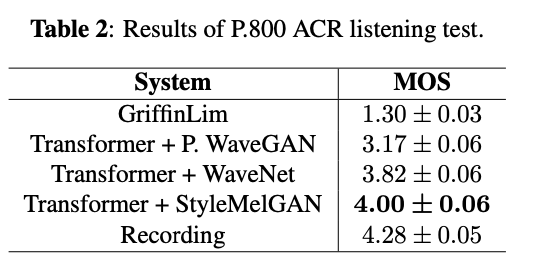
- 主观评价指标
MOS 评测
- 本文标题:声码器 | StyleMelGAN
- 创建时间:2022-07-21
- 本文链接:2022/07/21/2022-07-21_style_melgan/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!