
- BigVGAN: A Universal Neural Vocoder with Large-Scale Training
- https://arxiv.org/abs/2206.04658
之前现有的 GAN 声码器都是受限制在少量说话人+安静的录音环境下的音频合成,但是对于新的说话人/录音环境的音频,音频合成质量显著下降。所以目前声码器的挑战:在复杂多变的录音环境下,针对大量不同的说话人合成高质量的音频。
本文提出了 BigVGAN 工作,能够在多种训练过程没见过的环境下泛化得很好,是一个通用声码器。
BigVGAN 针对生成器部分,引入了周期非线性+抗混叠的表征,能够波形生成任务中所需的归纳偏置 (inductive bias),同时显著提升了音频质量。BigVGAN 基于提出的生成器以及 SOTA 的判别器,训练了目前参数量最大的 112M 的 GAN 声码器。在这种参数体量的模型训练过程中,论文研究了训练时的不稳定性,同时避免「过正则化」,保持高保真的音频生成。
BigVGAN 不只是适用于通常的语音合成任务,也适用于各种各样的集外场景,包括:新的说话人、新的语言语种、唱歌声、音乐和乐器声,甚至是训练过程没见过的噪声录音环境,都达到了 SOTA 的合成效果。
GAN 声码器作为通用声码器方法的优势:
- 相比于自回归模型或基于 diffusion 的模型,GAN 的生成过程是完全并行化的,只需要一次前向过程,就能得到音频声学特征对应的波形;
- GAN 不对模型结构有任何前提要求,可以很自然地扩大模型的参数量,得到大规模模型,但是基于 flow 的模型需要保证 latent 和数据之间的双射对应特性。
BigVGAN 的主要贡献点:
- 将周期性的激活引入到生成器中,利用了波形的高度周期性的特点;同时在每个卷积层内使用了 filtered nonliearities,具有抗混叠的作用,能够进一步减轻合成的波形在高频部分的失真;
- 14M 相同参数量的情况下,BigVGAN 具有比 Hifi-GAN 更好的合成效果,尤其是在没有见过的说话人和录音环境下,具有更好的通用性/泛化性;
- 使用 LibriTTS 训练 112M 的大模型,解决大模型训练不稳定的问题的同时,保持了合成波形的高保真;112M 的模型能够在 GPU 上达到 44.72 倍的实时效果。
BigVGAN 的细节
1. 回顾 GAN 声码器
对于 GAN 声码器的生成器部分,不同的网络结构在单说话人的语音合成任务中效果是几乎差不多的;但是本论文证明了对生成器的一些改进能够明显提高声码器的通用能力。BigVGAN 在 Hifi-GAN 的生成器的基础上进行改进,这些针对声码器通用能力的改进也可能应用在其他不同的生成器结构上。
针对判别器部分,Hifi-GAN 使用了 MPD + MSD 两种判别器结构;而 Universal MelGAN / UnivNet 则是使用的 MRD (Multi-Resolution Discriminator,多精度判别器),MRD 也是由多个判别器构成,在多个 2 维的线性谱上使用不同精度的 STFT 操作。论文发现,将 Hifi-GAN 的 MSD 替换为 MRD 能够提高音频合成质量,能够锐化语音信号的频谱,减轻 pitch 和周期方面的失真度。
参考文献一:Universal melgan: A robust neural vocoder for high-fidelity waveform generation in multiple domains
论文链接:https://arxiv.org/abs/2011.09631
参考文献二:UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation
2. 周期性归纳偏置
说明: 关于本文中的**归纳偏置(Inductive Bias)**,可以理解成一种针对数据样本的先验假设(归纳性的规律)。归纳偏置可以理解为,从观察到的现象中归纳出一定的规则,对模型做一定的约束,从而可以起到“模型选择”的作用,即从假设空间中选择/设计出更符合现实规则的模型。其实,贝叶斯学习中的“先验(Prior)”这个叫法,可能比“归纳偏置”更直观一些。参考讨论页面:https://www.zhihu.com/question/264264203
在本文的工作中,强调了:音频信号是高度周期性的,可以认为是很多周期性成分叠加构成的。论文希望将这种「归纳偏置」或者「先验」加入到生成器结构的设计中。
- 现有的基于 GAN 的声码器,都是纯粹依赖于空洞卷积层,在不同的频带学习周期性成分,逐点激活函数(ReLU)能够提高模型的非线性建模能力,但是没有提供『周期性』这一归纳偏置。
- 论文发现 Leaky-ReLU 在波形方面的外推 (extrapolation) 上表现较差:虽然模型能够在见到过的录音环境或者是安静干净的录音下生成高质量语音,但是如果是没有见到的场景或者是乐器类声音上,性能就会明显变差。
简而言之,论文意思:现有GAN 声码器没有充分利用周期性的先验信息,在录音场景的泛化性上也较差。
针对周期性先验信息和 Leaky-ReLU 作为激活函数的泛化性差问题,论文在生成器部分采用了最近新提出的周期性激活函数 Snake 函数。其中 α 是用来控制周期对应的频率的可训练参数,α 越大建模的频率越高。
参考文献:Neural Networks Fail to Learn Periodic Functions and How to Fix It
在 Snake 的论文中,给出了如下公式变换:
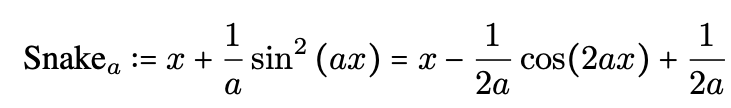
不同的 α 对应的激活函数图像如下图所示, α 越大,对应频率越快,周期越短,但是激活函数仍然是严格单调激增的函数。
因此,论文的第一个主要工作是:将 Leaky-ReLU 替换成 Snake 激活函数,其中 snake 函数中的可训练参数 α 是和 channel 相关的,不同的 1-D 卷积 channel 使用不同的 α 来激活,从而建模不同的频率分量。论文验证了 Snake 激活函数下的生成器,能够提高声码器在通用场景下的生成效果。
3. 抗混叠的表征
参考文献:Alias-Free Generative Adversarial Networks (StyleGAN3)
StyleGAN3 论文针对图像生成中 GAN 的混叠效应 (alias) 进行了研究。alias 可能发生在生成器结构里的不同部分,比如上采样层、离散采样时的非线性。StyleGAN3 将这些数据/信号解释为连续函数,针对这一问题提出了一系列方法来保证**平移等变性 (translation equivariance)**,消除特征空间内的混叠效应。
StyleGAN3 不再像之前一样在离散采样时采用逐点的非线性运算,而是受到奈奎斯特-香农采样定理的启发,在更高的时间精度上使用非线性操作,比如在原本 2 倍的精度上近似得到连续表征。这种非线性的连续表征能够保证特征空间的平移等变性,非线性也能够在连续域内生成新的频率,而不至于产生混叠。
本文对于音频合成任务,如果直接在连续空间内使用 snake 激活函数,也有可能产生随机的高频,这些高频在之间的离散时间域内是无法表征出来的 (由于奈奎斯特-香农采样定理,当采样率是一定的时候,能够完全还原的高频信号,频率是有限制的);但是这种副作用也可以使用一个低通滤波器来解决,去除过高频率的信号。
本文采用的抗混叠方法是,在时间维度上先对信号进行 2 倍升采样,然后使用 snake 激活函数,再将信号降采样回原来的采样率;每个升采样和降采样操作都使用加 Kaiser 窗的 sinc 滤波器进行低通滤波。此处的非线性称为:滤波后的 Snake 非线性 (filtered snake nonlinearity)。

sinc 低通滤波器:https://zh.wikipedia.org/zh-cn/Sinc%E6%BB%A4%E6%B3%A2%E5%99%A8
Kaiser 窗:https://zh.wikipedia.org/wiki/%E5%87%AF%E6%B3%BD%E7%AA%97
在生成器内的每个带有残差的空洞卷积多层结构中,都使用「滤波后的 Snake 非线性」操作,从而得到周期性的 1 维信号的抗混叠表征,这样的模块称为 AMP (抗混叠多周期组)。
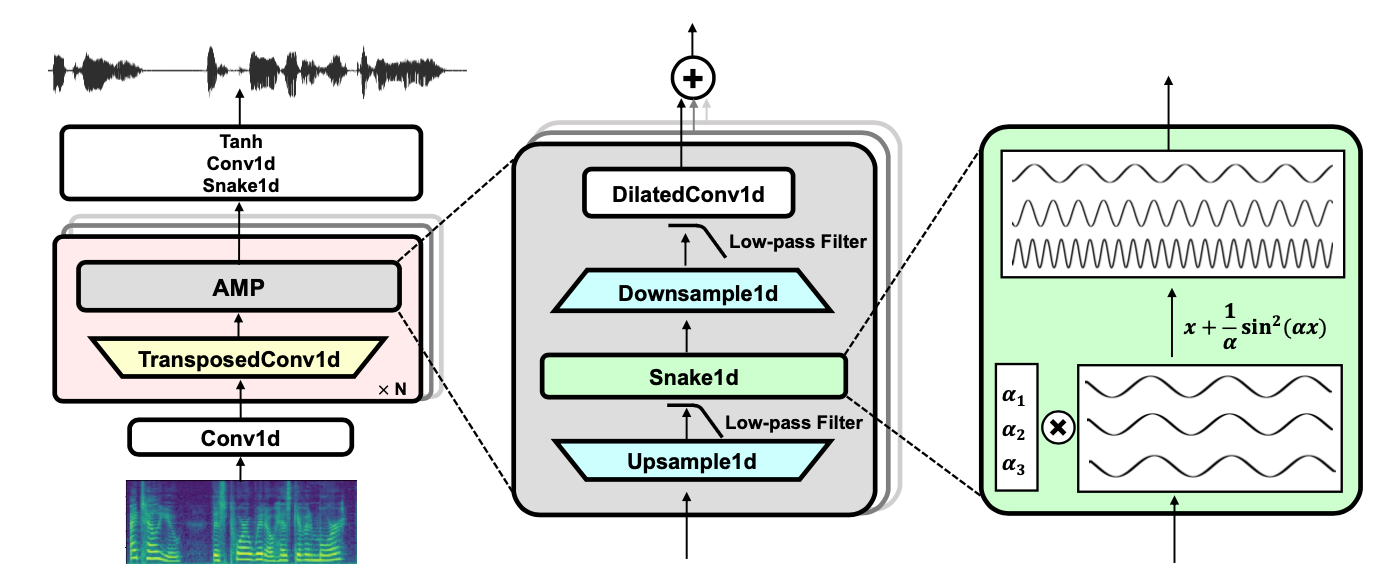
BigVGAN 的生成器结构
4. BigVGAN 大规模预训练
目标:训练要稳定、推理要高速、模型体量大、泛化性更好。
和 Hifi-GAN v1 的配置参数量可比 (14M) 的情况下,得到 BigVGAN-base。在 BigVGAN-base 的基础上,通过增大上采样模块的个数已经每个 block 的卷积通道数,以此提升 BigVGAN 的体量,对应的 112 M 大模型作为论文提出的 BigVGAN 模型。
BigVGAN 训练时的一些 trick 实践:
- Hifi-GAN 的默认学习率在训练早期会导致 BigVGAN 的崩塌,现象是判别器模块在几千次迭代后会训练收敛到 0,将学习率调整为一半会减轻这种现象;
- 更大的 batch size 能够减轻模式崩塌,因为每个 batch 可以见到相对更多的模式,所以论文将 batch size 从 16 调整成 32;
- 通过每层的「梯度范数」(gradient norm) 来诊断模型,发现抗混叠非线性模块会显著扩大 MPD (多周期判别器) 的梯度范数,所以训练早期梯度不收敛,造成训练的不稳定或者崩塌;论文因此增加了 clipping gradient norm 的梯度裁剪操作,这一操作在图像生成领域的大模型训练上没啥用,但是在音频方面却有很好的效果。
BigVGAN 的实验
1. 实验数据
LibriTTS 的全量训练数据,包括 train-clean-100 + train-clean-360 + train-other-500,都用在了训练中。BigVGAN 作为通用声码器,数据量以及数据的多样性是非常重要的。合成音频的采样率是 24 kHz。
一般 STFT 使用的是有限的频带,在 [0, 8000] Hz 之间,去除高频部分为了更容易建模;但是 BigVGAN 进行的是全频带的建模,频带是 [0, 12000] Hz,使用的是 100 维的对数梅尔特征。
STFT 的参数:FFT_size,winsow_size, hop_size = 1024, 1024, 256。
2. 实验结果
- 合成速度

- 评估指标
主观指标使用 MOS 值、SMOS 表示真实音频和合成音频间的相似程度;
客观指标有 5 种:
Multi-Resolution STFT:不同精度下的频谱距离
Perceptual Evaluation of Speech Quality,PESQ:语音质量评估
Mel-Cepstral Distortion,MCD:梅尔倒谱之间的差异 (使用 DTW 动态时间规整)
Periodicity Erro:周期误差
有人声/无人声分类的 F1 分数 (这是 GAN 声码器的重要失真表现之一)
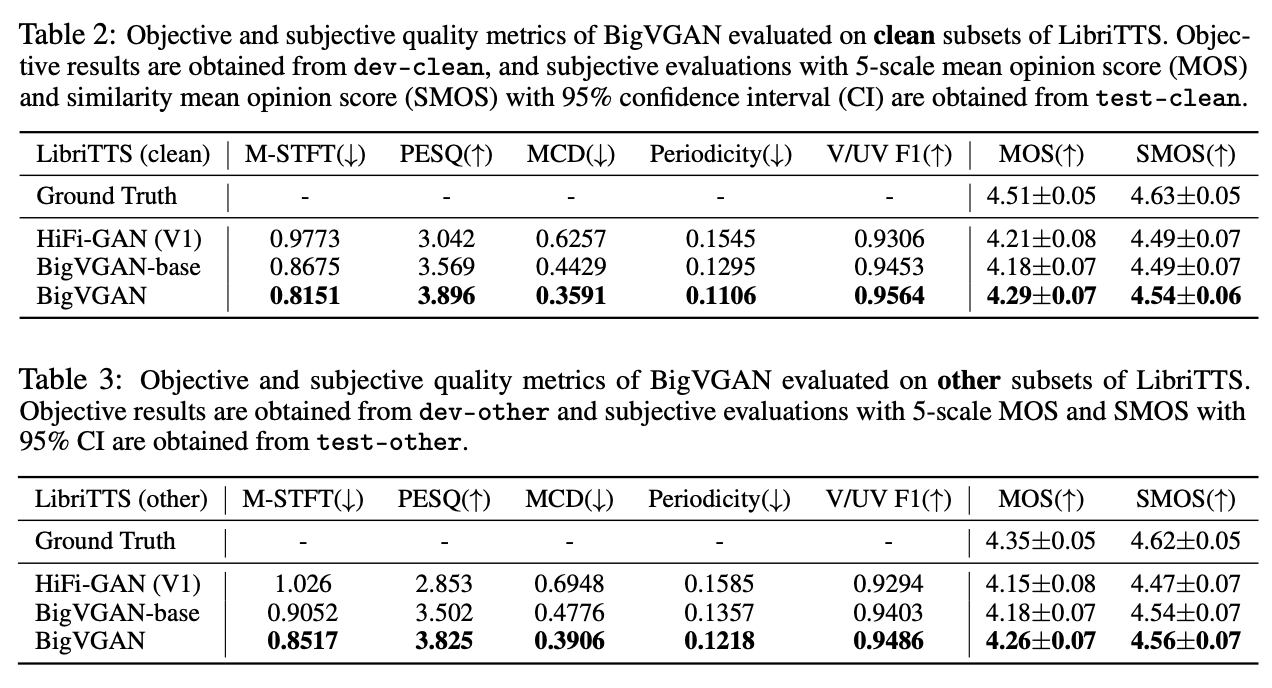
- 集内场景的评测
- 集外场景的评测
噪声场景 或者 乐器声音的合成
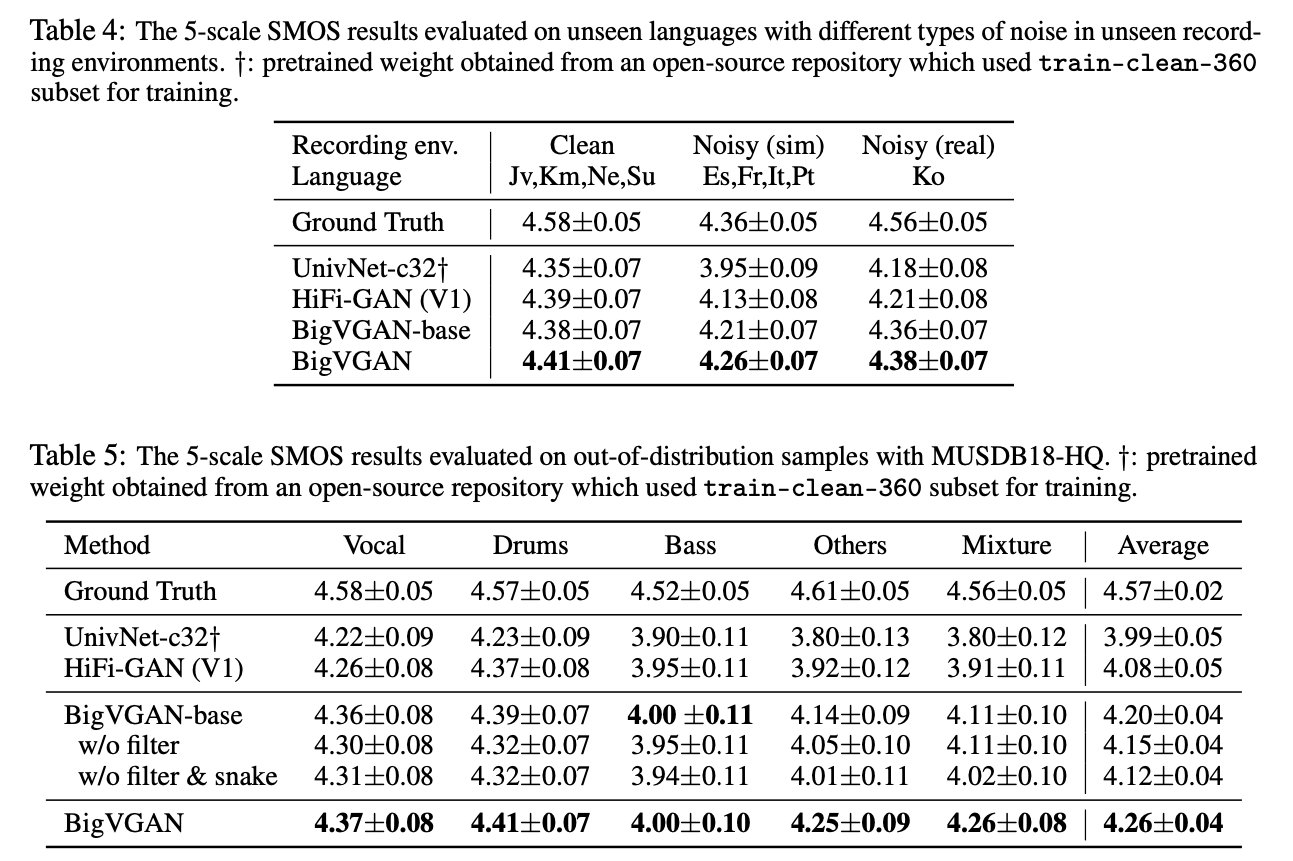
同样的评测集,但是训练数据的来源不同
- 本文标题:声码器 | BigVGAN:大规模训练的通用声码器
- 创建时间:2022-09-15
- 本文链接:2022/09/15/2022-08-15_bigvgan/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!