
- Avocodo: Generative Adversarial Network for Artifact-free Vocoder
- https://arxiv.org/abs/2206.13404
Avocodo 的提出是为了解决 GAN 声码器中常见的伪影 (artifact),伪影 artifact 可以理解为语音合成时的瑕疵或失真。
论文认为,对于听感更重要的语音成分主要集中在低频频带,不少 GAN 声码器通过**多尺度分析 (multi-scale analysis) **对降采样后的波形进行评估,能够帮助生成器提高合成语音的音质。但论文发现,多尺度分析会造成一些混叠和伪影的瑕疵,明显影响合成语音的音质。
使用了多尺度分析思想首先涉及到降采样操作,降采样通过降低音频的采样率,限制关注的频率范围 (奈奎斯特-香农采样定理)。典型的 GAN 声码器包括:
- MelGAN:使用平均池化进行降采样,使用 MSD 多尺度判别器,对将降采样后的波形进行判别;
2)** Hifi-GAN:等间隔选择采样点**进行降采样,使用 MPD 多周期判别器,对降采样后的波形进行判别。
GAN 声码器主要有两大类问题:
- 谐波成分的合成效果变差:合成语音的基频通常不够准确,降采样会带来这种混叠问题;
- 高频频带部分的合成效果差:出现在高频部分的伪影会带来噪音,影响语音音质。
如果把「降采样方法得到的低频频带」作为训练目标,就会加重这两种问题。
本论文针对 GAN 声码器的问题,提出 Avocodo 模型,能够更好地学习各种频率特征,最小化伪影问题,提高合成音质。主要的贡献是:
- 提出了两种新的判别器结构:协同 Multi-Band 判别器 (CoMBD)、子带判别器 (SBD)。 CoMBD 进行多尺度分析,设计的结构能够有效抑制伪影的出现;SBD 能够提升听觉体验,对不同频带的成分进行判别;
- 在训练阶段采用「阻带衰减更高的」 PQMF,来获取降采样或者分解的波形 。
Avocodo 的生成器对于高频成分和低频成分都进行了更好的建模,能够用于语音合成和歌声合成场景,而且对于没见过的说话人的合成效果更加鲁棒。
GAN 声码器的问题
1. 降采样造成的混叠
GAN 声码器的一些工作使用判别器对降采样之后的语音信号进行判别,以此强调学习低频部分的频谱信息。典型的两种降采样方法包括:MelGAN 为代表的平均池化 (Average Pooling) 降采样;Hifi-GAN 为代表的等间隔选取采样点进行降采样。本文通过一些初步实验,验证了这两种降采样方法都会带来混叠现象。
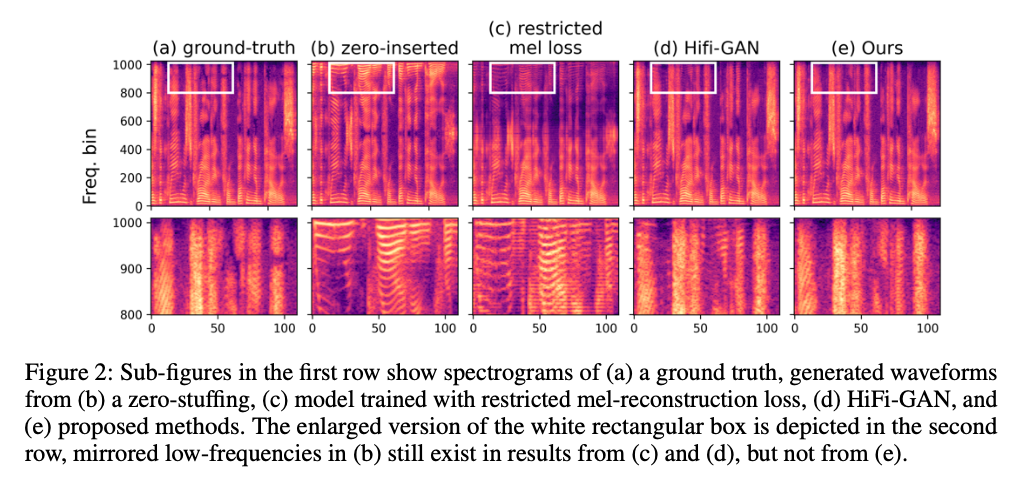
图中给出了降采样为原来 1/8 之后的结果:图 (a) 是原始的真实音频。
- 平均池化降采样:对比图 (d) 和图 (a) ,看不出来低频部分的混叠,但是超过 800 Hz 的谐波出现了混叠;
- 等间隔采样:对比图 (c) 和图 (a) ,本应该被去掉的高频部分,却生成折叠状纹路,影响了谐波频率成分。
为了避免混叠现象,必须使用带有阻带衰减的带通滤波器,正好** PQMF **是符合这一要求的,使用 PQMF 进行降采样能够很好的保留谐波成分。
2. 上采样造成的成像伪影
GAN 声码器会使用上采样层(比如反卷积层) 将输入的梅尔特征提升到和采样点长度匹配的长度。在上采样的过程中,低频的成分会因为**插入零(zero-insertion)**的操作镜像到高频成分,所以需要通过滤波将这些频率成分去掉。反卷积层就有这个过程,但是并不能完全移除这些镜像出来的高频成分。本文将这些剩下的没有被去除的高频成分称为「成像伪影」(imaging artifacts),这些成像伪影会影响合成语音的音质,造成高频频带的失真。
GAN 声码器工作中不少判别器都是集中关注低频成分,导致生成器也过多关注的是低频成分,没有注重对高频部分的滤波,从而加重了高频部分出现「成像伪影」的问题。因此,在训练生成器的时候,需要对低频部分和高频部分进行均衡考量。
Avocodo 工作详解
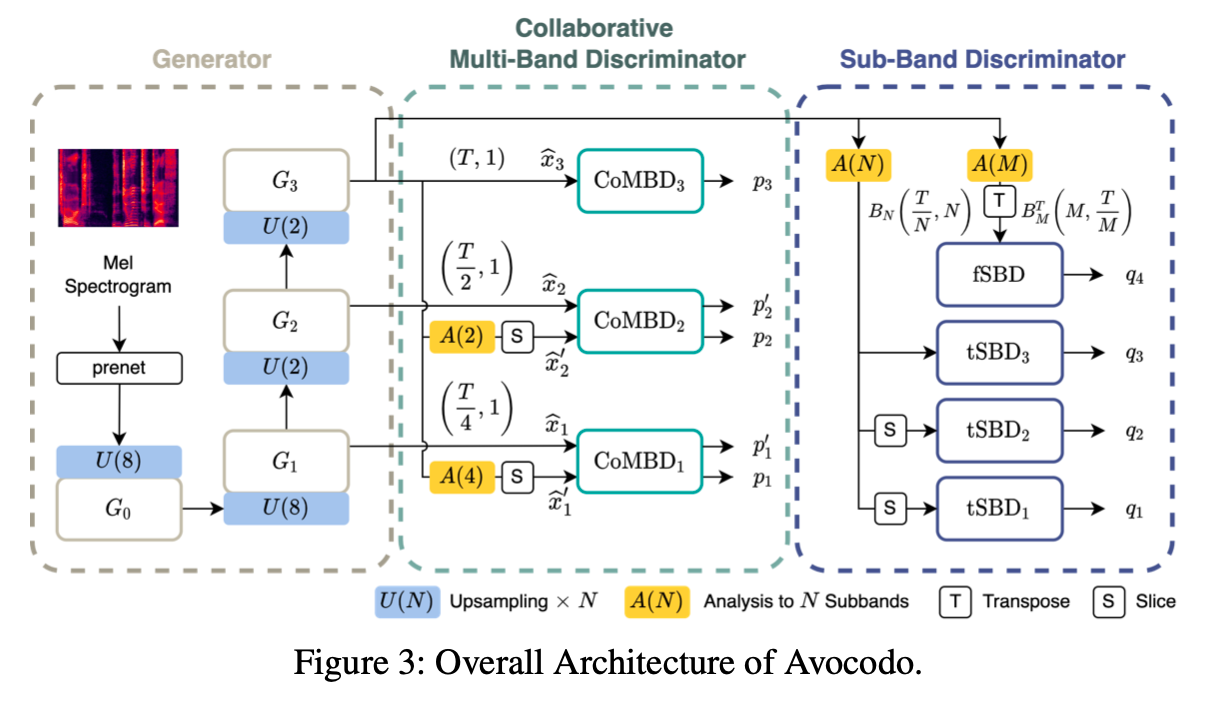
如上图所示,Avocodo 结构包含一个生成器和两个判别器:
- 生成器的输入:没有随机噪声,只有梅尔特征;生成器的输出:波形和一些中间输出结果;
- CoMBD 判别器:对最终波形、中间的降采样的波形以及中间的输出结果进行判别;
- PQMF 此处当作低通滤波器,对波形进行降采样;
- SBD 判别器对 PQMF 分析滤波器得到的子带信号进行判别。
1. Avocodo 的生成器
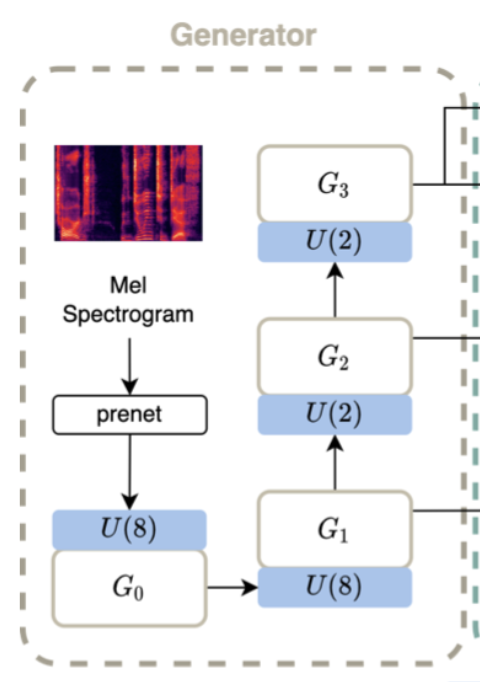
Avocodo 的生成器和 Hifi-GAN 结构基本一样,但是 Avocodo 生成器会产生多尺度的输出,包括最终采样率下的波形和一些中间输出。
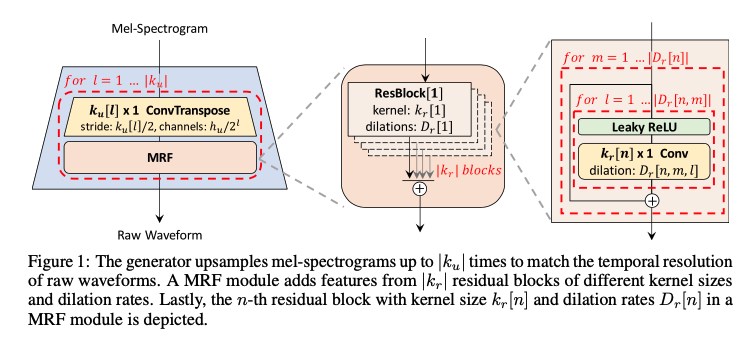
生成器包含四个子模块,分别对应上图中的 G1 - G3。G1 输出的波形对应的是 4 倍降采样,G2 输出对应 2 倍降采样,G3 对应不降采样的目标采样率的波形。G1/G2 的输出可以认为是中间结果。每个子模块都是由 Hifi-GAN 的 MRF + 反卷积构模块成的。反卷积层的作用是上采样,MRF 包含多个不同 kernel 大小、不同空洞率的残差模块,能够提供比较多样的感受野范围。
和 Hifi-GAN 的区别是,每个子模块增加了一个投影层,当作该子模块的输出,作为中间结果。
2. 协同多带判别器 (CoMBD)
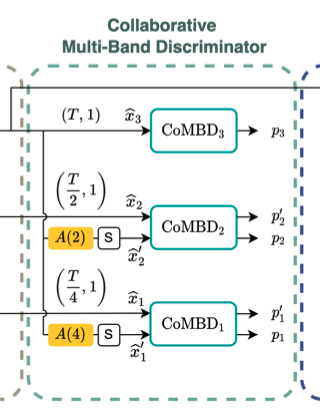
CoMBD 用于判别生成器给出的多尺度输出,每个 CoMBD 模块结构基本相同,包含多个卷积层+ReLU激活,只不过用来评估不同时间精度上的波形。
a) CoMBD 的结构详解
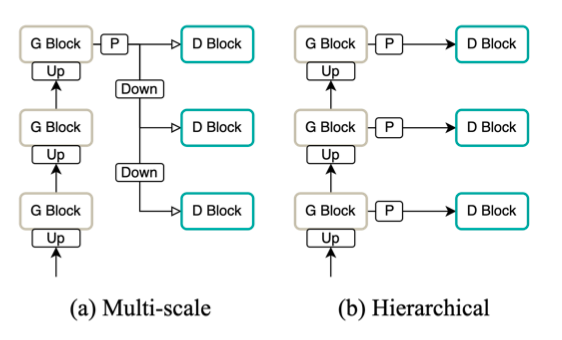
Avocodo 结合了判别器的两种常见结构:多尺度 (Multi-Scale) 和 层次化 (Hiearchical)。如下图所示,多尺度是在生成器最终输出的波形上,再进行 2 倍/ 4 倍降采样,分别经过判别器判别;而层次化结构则是保留了生成器中上采样阶段的中间结果,在最终输出波形前的上采样模块,保留中间结果输出,直接作为判别器的输入。
Avocodo 将两种方式巧妙结合在一起,针对降采样波形的判别器 CoMBD1 和 CoMBD2,输入包含两路,分别是「生成器的中间波形结果」和「最终生成波形进行降采样后的波形」。两路输入经过完全相同的权重一样的模块,分别得到概率 p 和 p’。
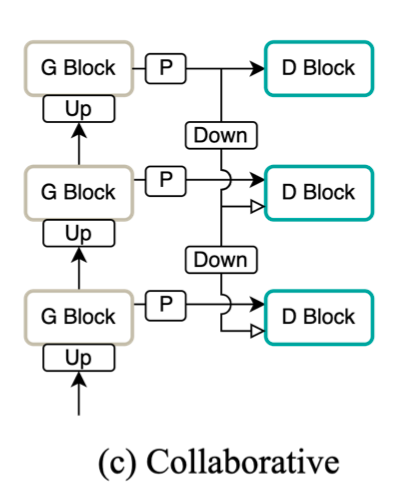
两种方式结合后能够有效减轻生成波形的伪影现象,综合了 Multi-Scale 和 Hiearchical 的优点:
- Multi-Scale: 在完整波形和降采样后的波形上进行判别,帮助生成器更关注于低频频带的频谱特征;
- Hiearchical: 不过分关注在低频频带部分,低频和高频能够更平衡地学习,有效减轻伪影现象。
b) CoMBD 和 MSD 的对比
- 相同点:两个判别器都可以用来评估不同尺度(时间精度)上的波形的 fake/true
- 不同点一:模块输入来源
- MelGAN 和 Hifi-GAN 中的 MSD,是以生成器最终的波形作为输入,在判别器端加入了降采样操作 (strided average pooling),然后将不同倍数的降采样波形作为后续 MSD 模块的输入;
- Avocodo 中的 CoMBD,不只是在判别器端再对全精度的波形进行降采样,而且利用了生成器中不同升采样模块输出的中间结果作为输入,相当于降采样部分的判别器 (2 倍/4 倍),对应于图中的 CoMBD1 和 CoMBD2,有两个输入
- 不同点二:模型结构设计
- MelGAN 中 MSD 的结构是一样的,感受野大小相同;
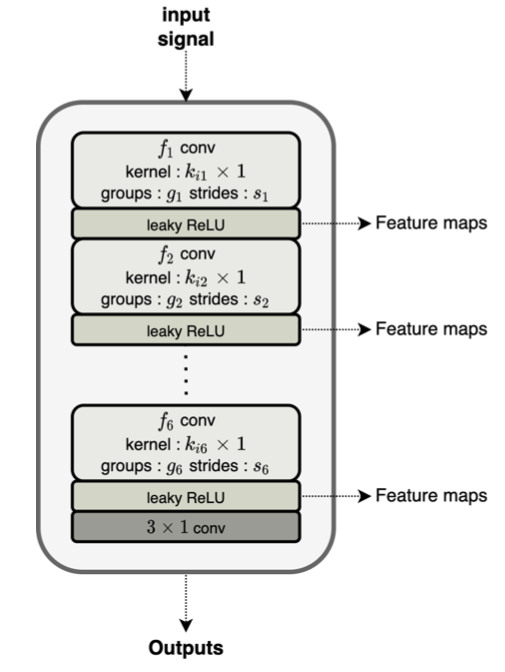
- Avocodo 的 CoMBD 对于不同的时间精度,卷积层的感受野大小也做了区分,主要体现在卷积核 kernel size 的设置存在差异。具体参数如下:

- Avocodo 的 CoMBD 的结构示意图:
为了进一步减轻合成音频的伪影,提高语音音质,论文在降采样时使用了可微分的 PQMF 模块,避免混叠现象。具体流程为:先将完整的波形使用 PQMF 分析滤波器进行频带拆分,切分为 N 个子带,每个子带的采样点个数是原本全部波形采样点的 1/N,然后选择第一个子带的信号即可。
3. 子带判别器 (SBD)
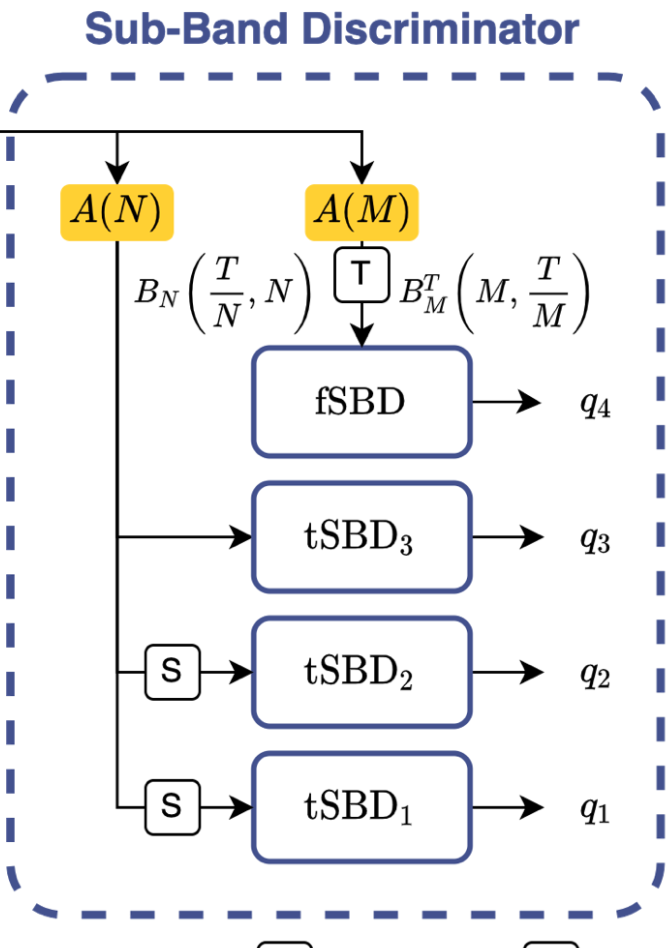
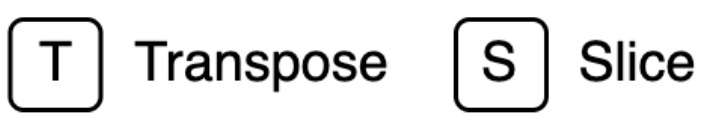
Avocodo 的另一个判别器是 Sub-Band 子带判别器,对 PQMF 分析滤波之后的子带信号进行判别。PQMF 分析滤波如果将信号分为 N 个子带,原始波形的采样率为 s 的话,第 n 个子带信号包含的信号频率范围在:
因此,子带判别器内部相当于对每个子带频率范围的信号进行判别,学习相应的判别特征。
自带判别器内部包含两大模块:tSBD 和 fSBD,结构上是相同的,只不过输入不同。关于 SBD 的结构,如下图所示。SBD 里包含多个感受野不同的空洞卷积组,利用到了语音方面的先验信息(不同频率范围上需要不同大小的感受野),所以在不同的频率范围上,论文特意选择了不同的空洞率大小因子。

针对 tSBD 和 fSBD 的细节信息,下文进行详细介绍:
a) tSBD: 捕捉时间维度的特征变化
tSBD 的输入:生成器生成的最终波形,经过 A(N) 也就是 PQMF 分析滤波器,划分成 N 个子带。子带对应的信号在时域上进行卷积;图中的 S 代表 Slice,即从已经划分好的 N 个子带上,Slice 切分出一部分子带,作为 tSBD 的真实输入,即可在不同 tSBD 上,关注到不同频率范围进行判别,从子带覆盖的频率范围上增加多样化。
b) fSBD: 捕捉各子带之间的信号关系
fSBD 的输入:同样地,输入也来自于生成器最终的输出波形,经过 A(M) 对应的 PQMF 分析滤波器,划分成 M 个子带。子带信号经过转置操作?之后作为 fSBD 的输入。
c) SBD 和 FB-RWD 的区别
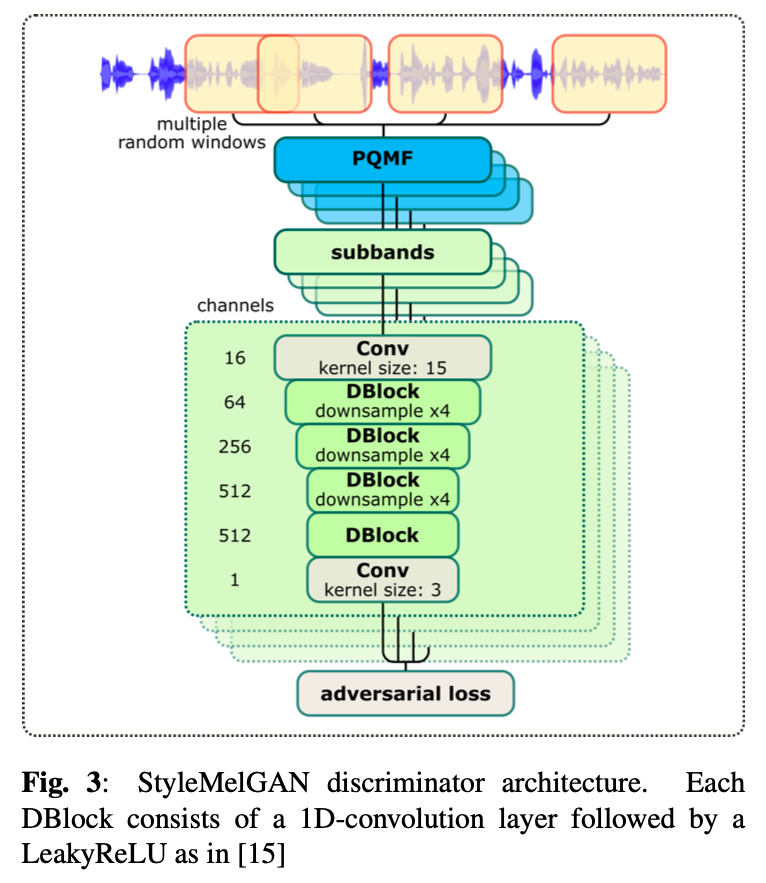
回顾 StyleMelGAN 中的 FB-RWD 判别器模块,是先随机选择一个时域窗口,然后经过 PQMF 划分子带得到子带信号进行判别。但是,SBD 和 FB-RWD 有较大的区别:SBD 的每个子模块关注的是相同频带划分方法下的不同子带范围的信号;FB-RWD 是对输入的波形进行不同个数的子带信号划分。
在实验配置可以看到,SBD 的模块能够见到不同的信号,包括:低频带、全部频带、不同频带间的关联,从而能够见到更多样的组合,相比于 FB-RWD 的建模是更加有效的。比如本文给出的下列配置中,tSBD 部分将输入波形进行 N=16 的子带划分,tSBD1 关注第 1-6 个频带,tSBD2 关注 1-11 频带,tSBD3 关注所有的频带。
3. Avocodo 的训练目标
a) GAN 的损失函数
使用 LS-GAN 的损失函数,针对中间结果输出 V 和完整波形降采样后的 W,各有一套损失函数。

b) Feature Matching 损失函数
固定判别器不变,计算波形经过判别器的某层后的输出结果,使用 L1 损失函数,使得合成的波形与真实波形对应的输出结果相近,以此作为生成器额外补充的训练目标。
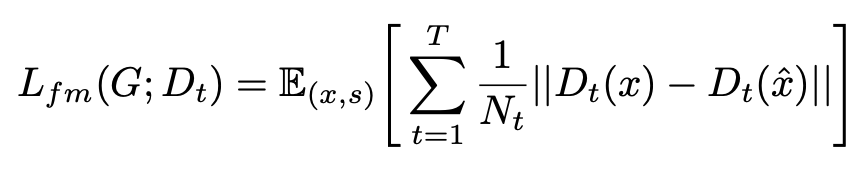
c) 梅尔重建损失函数
对合成的波形提取梅尔特征,计算其与真实波形对应梅尔特征之间的差异,作为生成器额外的训练目标。
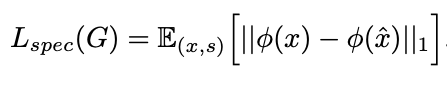
d) 最终完整的损失函数
将以上损失函数结合,得到如下所示的判别器/生成器优化目标。
P 表示 CoMBD 子模块的总个数,(P-1) 表示只有 (P-1) 个 CoMBD 模块的输入是两路;Q 表示 SBD 的子模块个数。
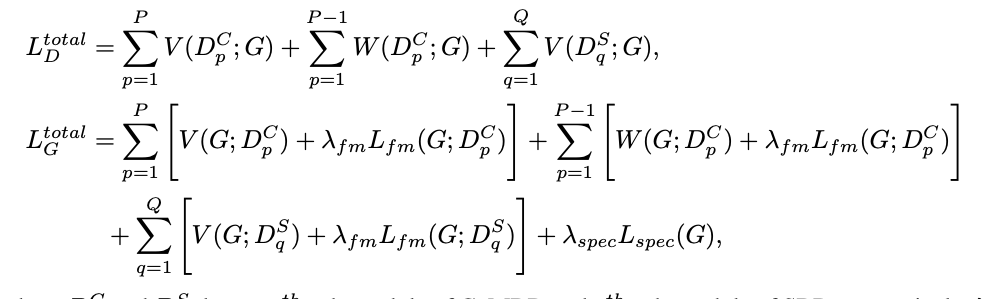
Avocodo 实验部分
1. 单说话人/多说话人 TTS 任务
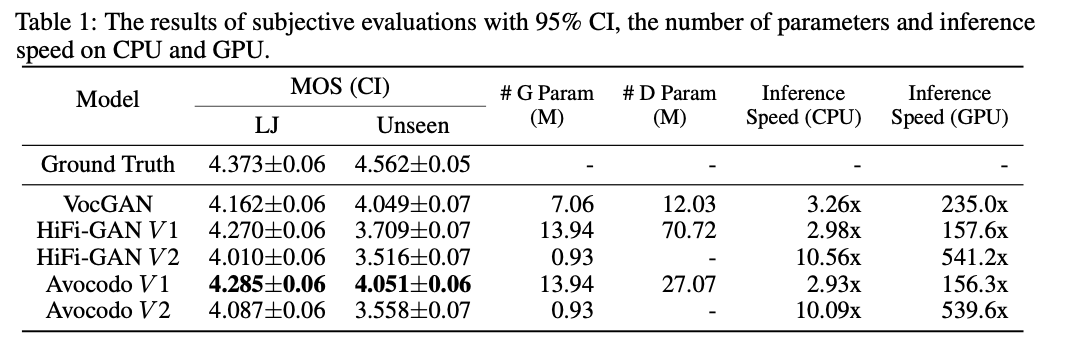
和 Hifi-GAN 论文中的 V1/V2 不同参数量一样,本文也按照参数量相当的情况进行了对比实验。
SBD 中 tSBD 的子带个数 N=16,fSBD 的子带个数 M=64。
主观评测结果:
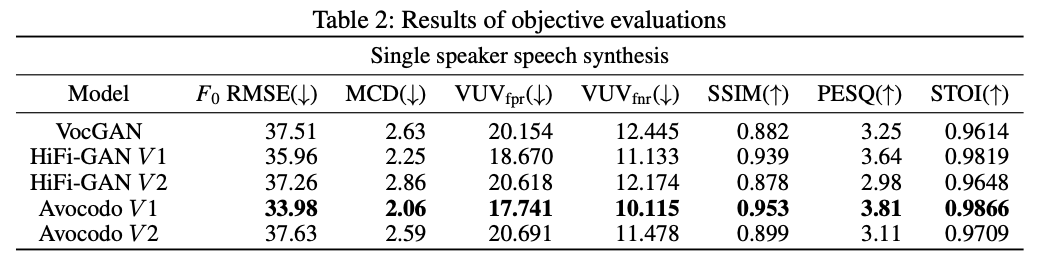
客观评测结果:
2. 歌声合成任务
主观评测结果:

客观评测结果:

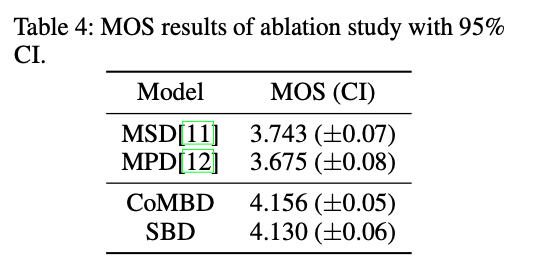
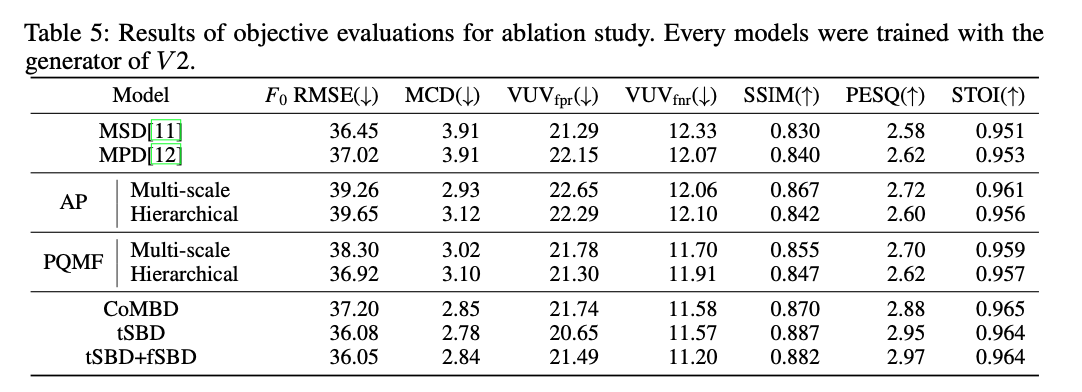
3. 消融实验
- 本文标题:声码器 | Avocodo:进一步缓解伪影问题
- 创建时间:2022-10-16
- 本文链接:2022/10/16/2022-08-16_avocodo/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!