
- Squeezeformer: An Efficient Transformer for Automatic Speech Recognition
- https://arxiv.org/abs/2206.00888
参考代码:https://github.com/wenet-e2e/wenet/tree/main/wenet/squeezeformer
示例训练:https://github.com/wenet-e2e/wenet/tree/main/examples/librispeech/s0
1 研究背景
端到端建模在语音识别领域已经收获了很大的成功,CNN 和 Transformer 成为两种主流的模型结构。CNN 系列包括:ContextNet/QuartzNet/Citrinet/Jasper,Transformer 则主要是和 CTC 等其他结合。但是 CNN 和 Transformer 建模方式各有各的缺陷,CNN 缺少对全局信息的建模能力,而 Transformer 的算力和内存要求较高。2020 年中提出的 Conformer 将 CNN 和 Transformer 相结合,用 CNN 增强 Transformer 的局部建模能力,已经成为 ASR 甚至其他语音任务 (TTS/语音增强) 的 SOTA 模型。在 ASR 领域内,Conformer 作为神经网络结构的候选,可以和其他多种不同的模型结合,比如 Conformer-CTC,Conformer-Transducer,都能取得不错的效果。
本文正是在 Conformer 的基础上,对 Conformer 结构进行分析和改进,从而得到更加简单、准确、高效的 ASR 模型结构。之前已经有论文 Efficient Conformer 针对 Conformer 进行优化改进,试图使用递进的下采样方法和 group attention 减少 Conformer 训练和推理时的开销,这篇论文不在此详述。
Efficient conformer: Progressive downsampling and grouped attention for automatic speech recognition
2 Conformer 的缺陷及优化点
回顾 Conformer 的模型结构,在 Transformer 的 MHA + FFN (另外的 layernorm + 残差) 基础上,Conformer 采用 Macaron 式的 FFN,并在两个 FNN 中加入 MHA 和 Convolution 模块。因此,Conformer 存在以下缺陷:
- Conformer 仍然使用的是 MHA,attention 计算时复杂度是O(序列长度的平方),序列越长,算力/内存的高要求问题越明显
- Conformer 结构比 NLP/CV 中使用的 Transformer 结构更复杂,使用了很多特殊设计的模块和结构,比如 swish 激活函数,macaron 式结构等,给 Conformer 模型在各种不同硬件平台的配置使用带来了更大的代价。从模型可解释性的角度,也会带来一些问题:这些特殊涉及的模块/结构,为啥是必需的,以及如何确认目前的结构已经是最优的选择呢?
基于对 Conformer 结构的以上质疑和思考,本文对 Conformer 结构的每个设计进行了认真/系统化的分析,提出了一种更加简单、高效的模型结构 Squeezeformer。论文的具体贡献可以进行如下归纳:
- Conformer 结构在时间维度上,学习到的相邻语音帧的表征是高度冗余的,尤其是深层的表征,这种高度冗余的特征带来了一些不必要的计算。本文使用 U-Net 的变体模型 Temporal U-Net 结构,从时间的维度对序列进行降采样和升采样,能够提高训练的稳定性
- Conformer 将 MHA 和卷积模块背靠背放在一起,外面包上 Macaron FFN 的结构,本文认为这种结构不是最优化的,提出采用 MHA + FFN + Conv + FFN 的新结构
- 本文同时对 Conformer 结构中细粒度的模块进行了分析改进:将 GLU 替换为 Swish 激活;将多余的 pre-layernorm 替换为 scaled post-layernorm;在第一层降采样层中使用深度可分离卷积网络,明显降低了模型的 FLOPS
- 在同等参数量下,Squeezeformer 的效果比其他 SOTA 模型都更好,并且进行了消融实验验证了科学性
3 Squeezeformer 结构
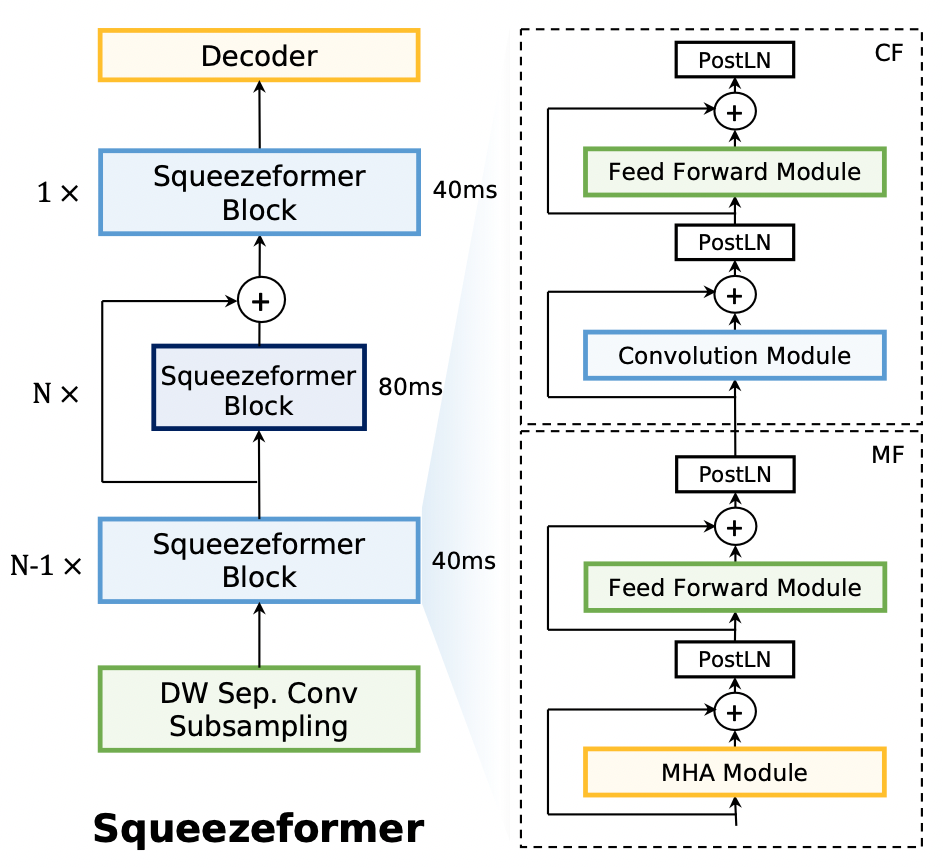
3.1 Temporal U-Net 架构
attention 的计算复杂度是 O(序列长度的平方),为了减少 attention 部分的计算开销,本文从缩短序列长度的角度进行优化。
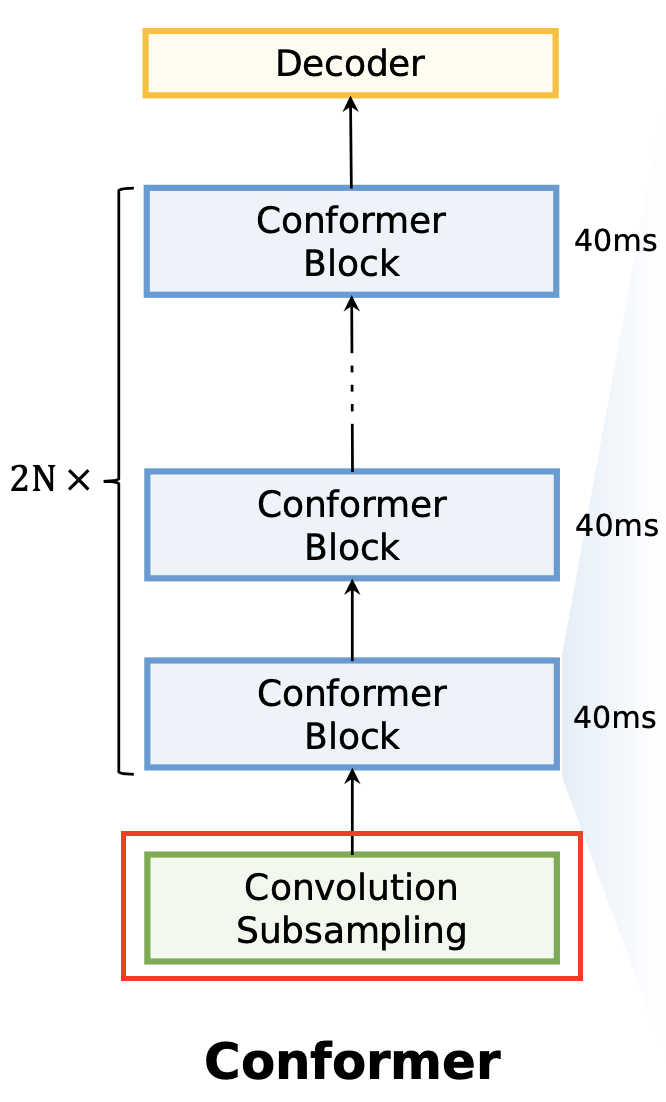
在原始的 Conformer 结构中,输入端经过卷积降采样模块,将输入的帧率从原始的 10 ms 降低至 40 ms,然后整个模型的主体部分都是在 40 ms 帧长对应的帧率下面。
论文首先分析验证了目前使用的帧率下,深层学习到的特征表征仍然是存在冗余的,分析了每个语音帧学习到的特征 embedding 是如何随着 Conformer 模型的深度可导的。随机从 Librispeech 的 dev-other 数据中抽取 100 条音频,记录模型前向之后每个 Conformer block 之后的输出,然后使用平均的余弦距离用于衡量隐层的相邻时刻的 embedding,结果如下图所示。
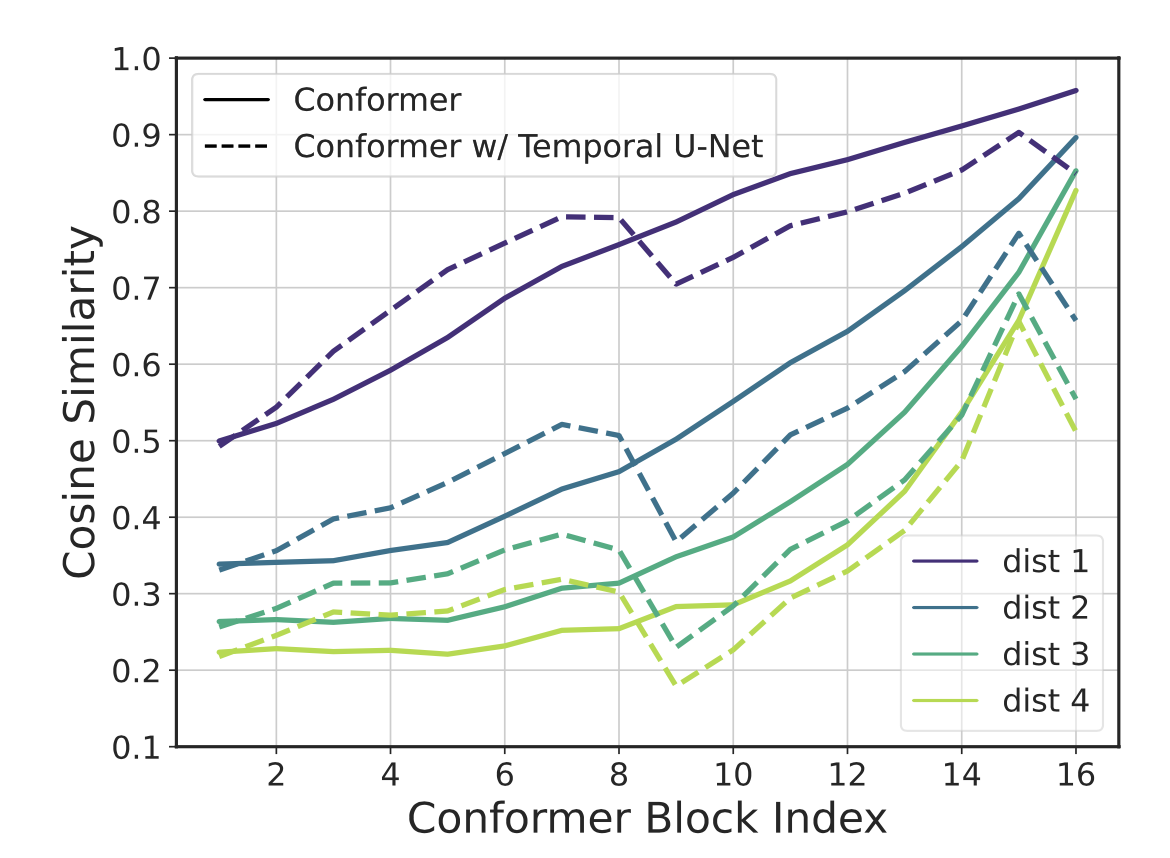
从图中实线表征的原始的 Conformer (不使用 Temporal U-Net),可以看出,随着 Conformer 层数的加深,相邻时刻(帧的距离从1到4)的 embedding 余弦相似度明显升高,到最后第 16 层时,dist=1 的平均相似度甚至可以达到 95%,dist=4 的平均相似度也保持在 80% 以上。所以,对于原始的 Conformer 结构,随着深度的加深,相邻时刻的 embedding 表征是越来越高度冗余的。因此,论文从这一角度出发,甚至对于更深层的 Conformer Block,还可以进一步压缩帧率,这样明显的好处就是可以减少模型体量和推理计算量,但是需要验证的是:是否会对模型的识别效果带来负面影响。
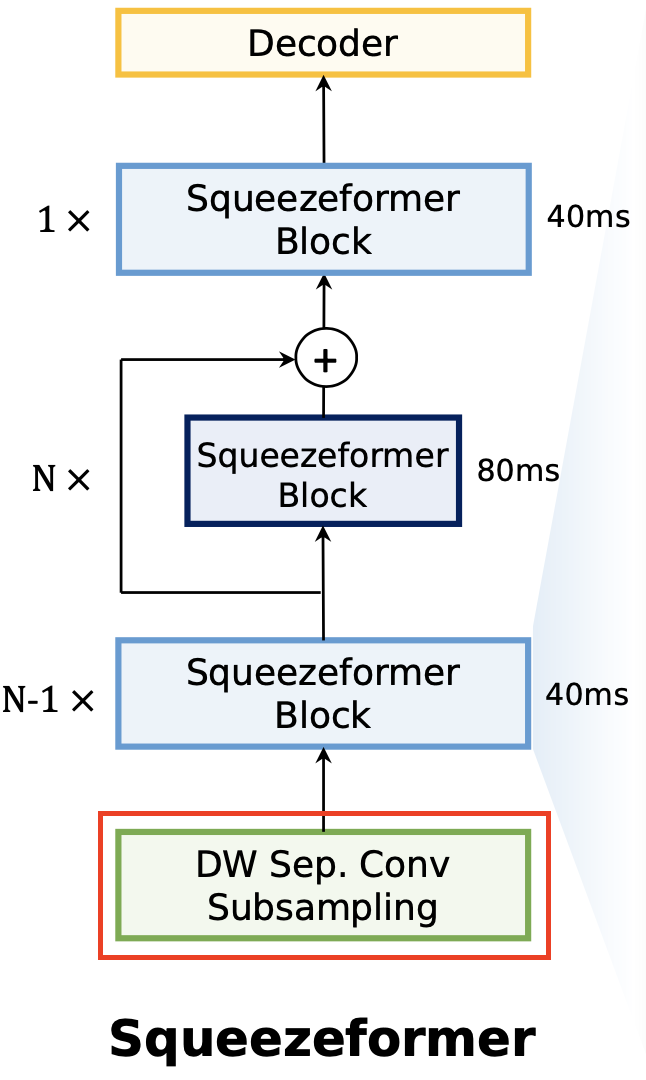
Squeezeformer 的第一个优化点是对 Conformer 的降采样策略进行修正。对于第 1-7 层的 Conformer Block,都采用 Conv2d 降采样之后的 40ms 的帧率;在此基础上,将帧率进一步减半,两倍降采样后帧率变为 80ms,降采样的模块:深度可分离卷积,stride=2,kernel=3 作为 pooling 层进行降采样。80 ms 的帧率保持 8 层的 Conformer Block。论文发现,如果剩下的全部 Conformer Block 都使用 80 ms,模型训练是不稳定的而且不收敛,分析原因可能是 80 ms 的帧率对于 ASR 任务来说时间上的分辨率已经太低了,因为 80 ms 在时间维度上可能已经不只是对应到 1 个char/phone 上了(时间的跨度太大)。因此,论文从 Temporal U-Net 获取灵感,在最后一个(第 16 个)Conformer-Block 又进行了升采样,还原为 40 ms 的帧率。
总结来看,原始 Conformer 采用 16 层 40 ms 帧率的 Block,替代为了 8 层 40 ms 的帧率 + 4 层 80 ms 的帧率,模型的整体计算量 FLOPs 减少了 20%。值得惊奇的是,这种操作下,模型的识别效果还得到了一定的改观。
然后再次回顾图中虚线表示的带有 Temporal U-Net 的模型,第 8 层之后相邻 embedding 的余弦距离得到显著降低,验证了 Temporal U-Net 与预期的效果相一致。
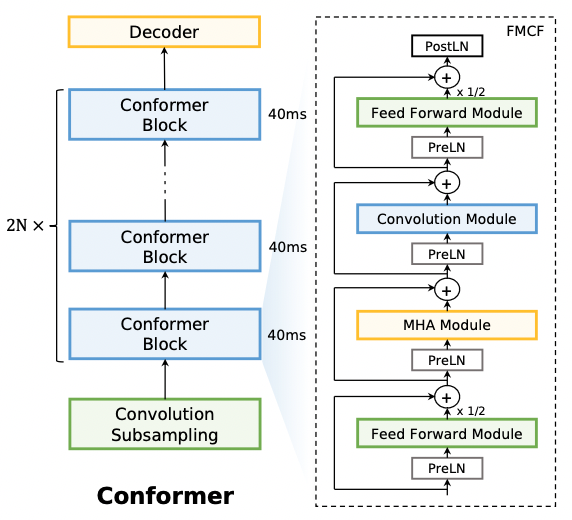
3.2 Squeezeformer Block
| Conformer Block | Squeezeformer Block |
|---|---|
 |
|
Conformer 的原始结构采用 macaron 式,即 FMCF (Feedfoward-MHA-Conv-Feedforward) 的结构。在 ASR 的模型结构中,Conv 模块的 kernel size 为 31,实际已经比较偏全局的信息。论文尝试回归到类似 Transfomer Block 的结构,采用 MF/CF (MHA-Feedfoward)/(Conv-Feedforward) 的就结构,相当于将 Conv 视作一个提取 local 局部信息的 Attention 模块,和 MHA 在不同层级上进行局部/全局信息的抽取。
实验结果证明,这种改动不仅更加直观可解释性更好,而且还能在 WER 效果有略微的更好。

3.3 统一化激活函数
Conformer 在大多数层的激活函数选用的是 Swish,但是在 Conv 模块选择的是 GLU。Squeezeformer 选择将这一奇怪的操作进行统一化,在 Conv 模块也使用 swish 激活函数,实验证明对模型效果影响很小。

3.4 简化的 LayerNorm
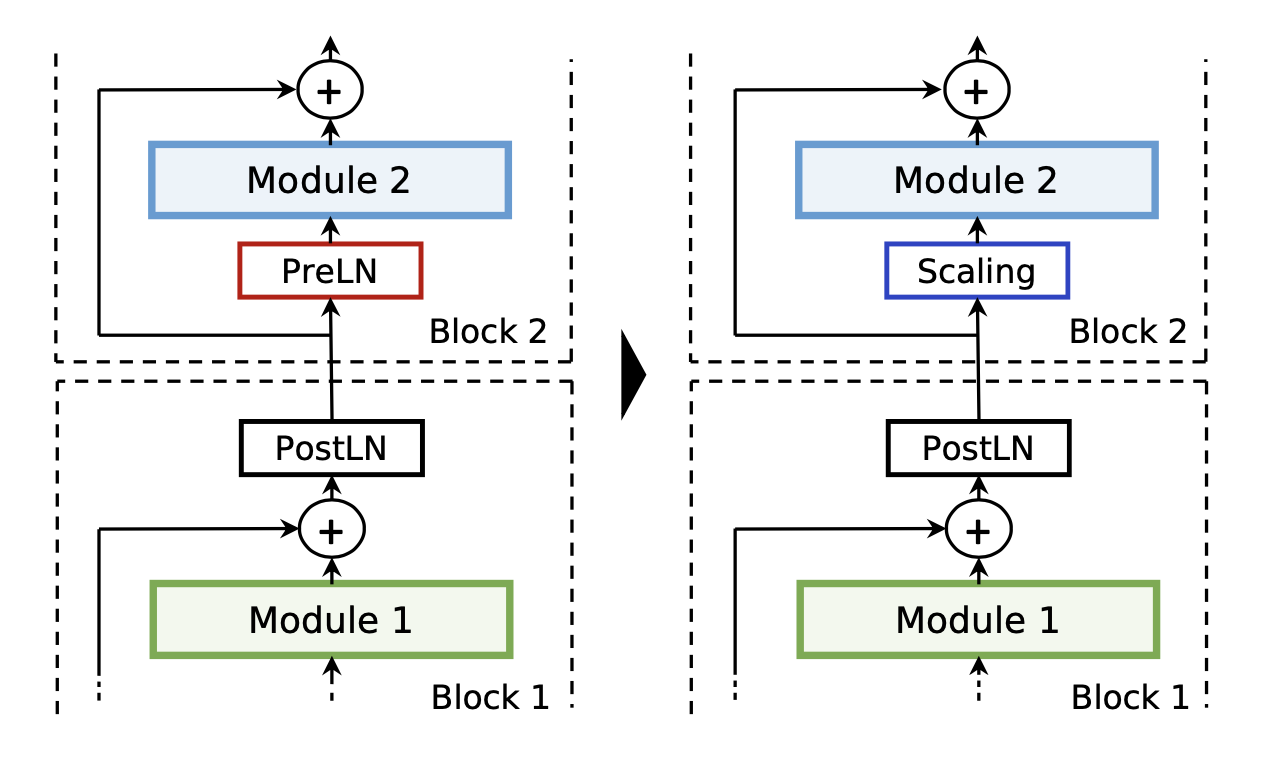
原始的 Conformer Block 中每个残差连接内采用的是 pre-layernorm,但是每个 block 最后还会使用一个 post-layernorm,因此在两个 block 的连接处,相当于存在两个 layernorm。LayerNorm 的作用中,pre-layernorm 通常认定可以稳定训练,post-layernorm 则是能够提高模型效果。
论文为了简化 LayerNorm,发现如果移除两者中的其一,模型无法正常收敛。模型诊断发现,layernorm 学习到的变量在数值的数量级上差别巨大,尤其对于 pre-layernorm,会对输入进行很大程度的缩放,对残差连接的部分给予更大的权重。因此,论文选择简化 pre-layernorm 部分,并且将其直接替换成一个缩放的层。这一操作在 NF-Net 和 DeepNet 中都有类似的工作。
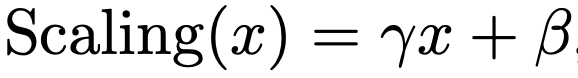
实际上相当于替换成了线性变换层,然后整个模型中只保留 post-LayerNorm。实际上这部分的参数能够合并到后续的 linear 中,因为都是简单的线性变换,所以实际上对于模型来说没有引入额外的运算量。简化完 LayerNorm,模型效果也变好了:

3.5 基于深度可分离卷积的降采样
 |
 |
|---|
Squeezeformer 对于 Conformer 靠近输入端的降采样模块也进行了改进。论文发现原始的 Conformer-CTC 模型下,降采样模块占了 28% 的 FLOPs 运算量。这是因为原始的降采样层使用的是普通的 stride=2 的卷积操作。为了减少这一部分的计算开支,论文将第二层降采样层,修改为深度可分离卷积 DSConv 操作。这一波操作下来能节省 22% 的 FLOPs,虽然深度可分离卷积在硬件加速器上比较难使用,但是节省了很多计算量的情况下,推理速度还是得到的 1.34 倍的加速,同时模型效果没有变差。
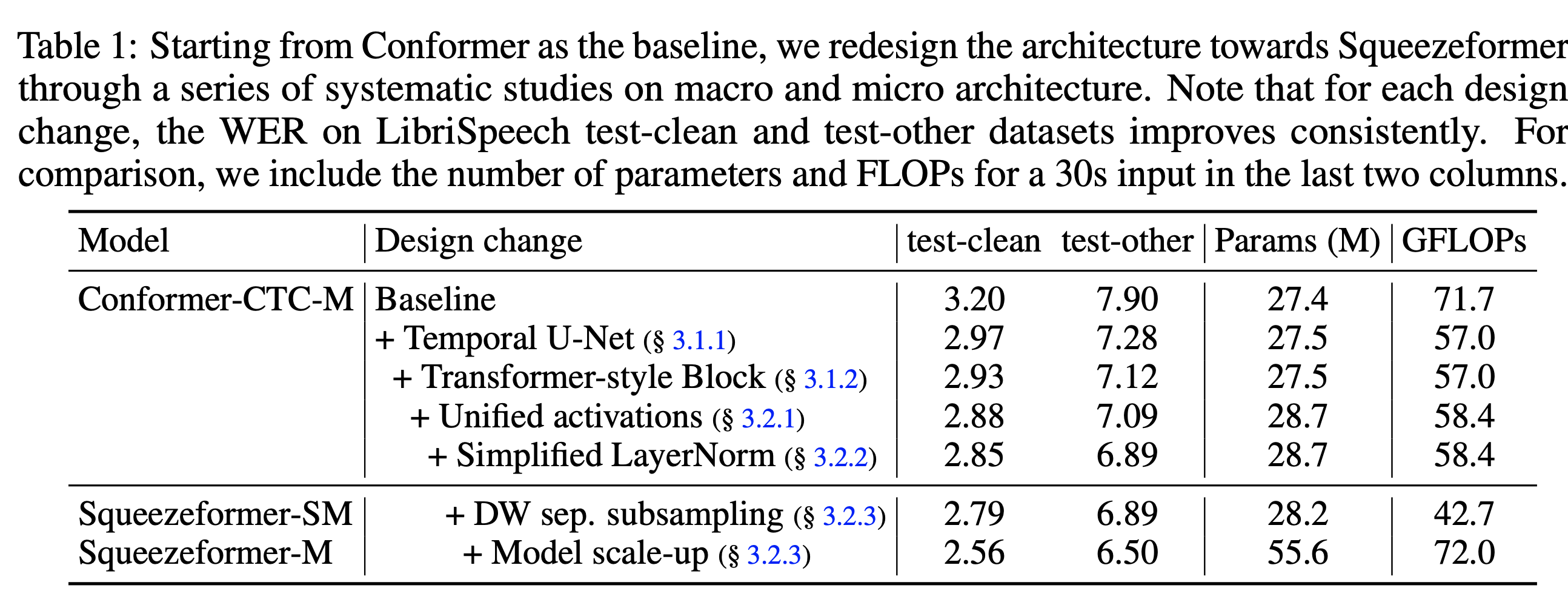
总之,Squeezeformer 的 WER 限制降低,FLOPs 降低了 40%,当 FLOPs 提升至和原本的 Conformer 相近时,模型的识别准确率显著提升。不同参数量/FLOPs 下的模型如下表所示:
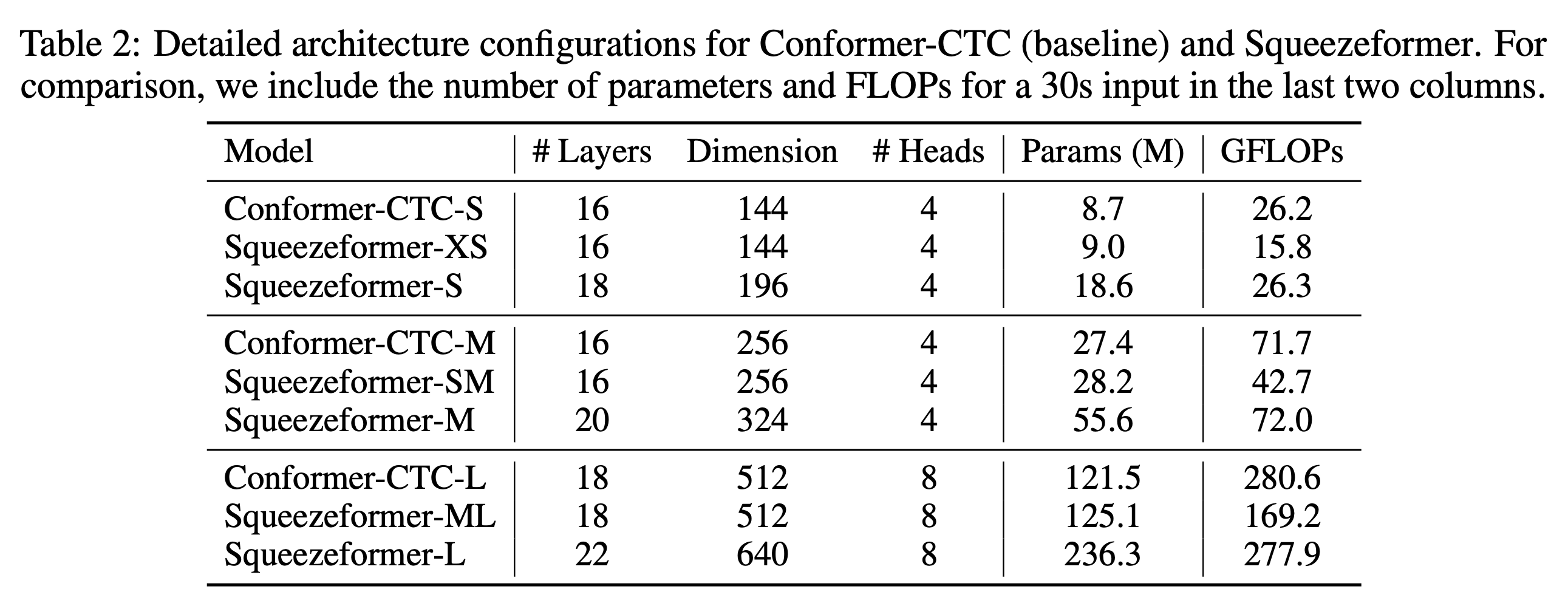
4 实验
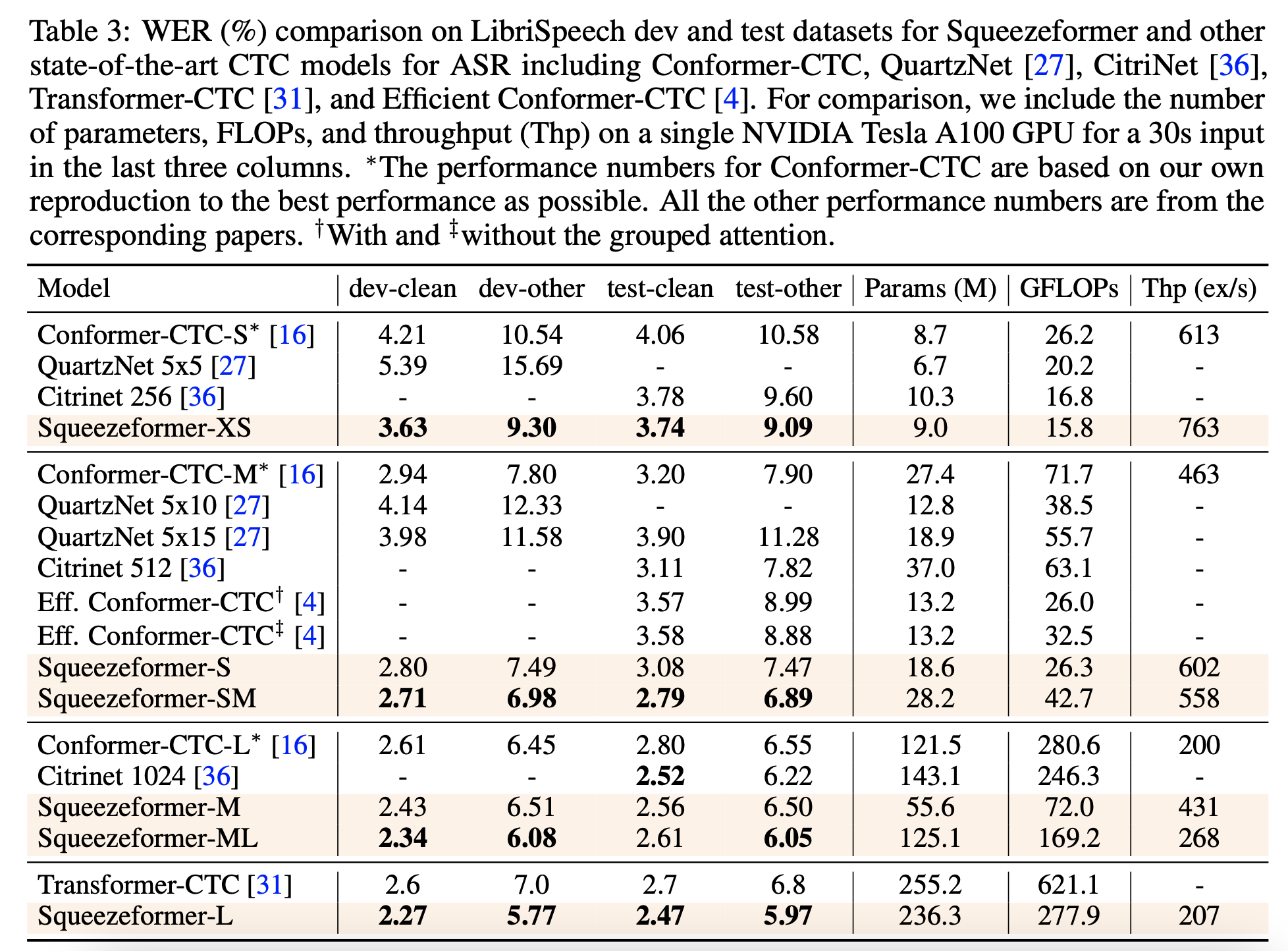
实验主要探究 Encoder 网络结构的效果,因此 Decoder 可以认为各对比模型是等价的,选择使用 CTC 作为论文中的 Decoder / loss 方法。
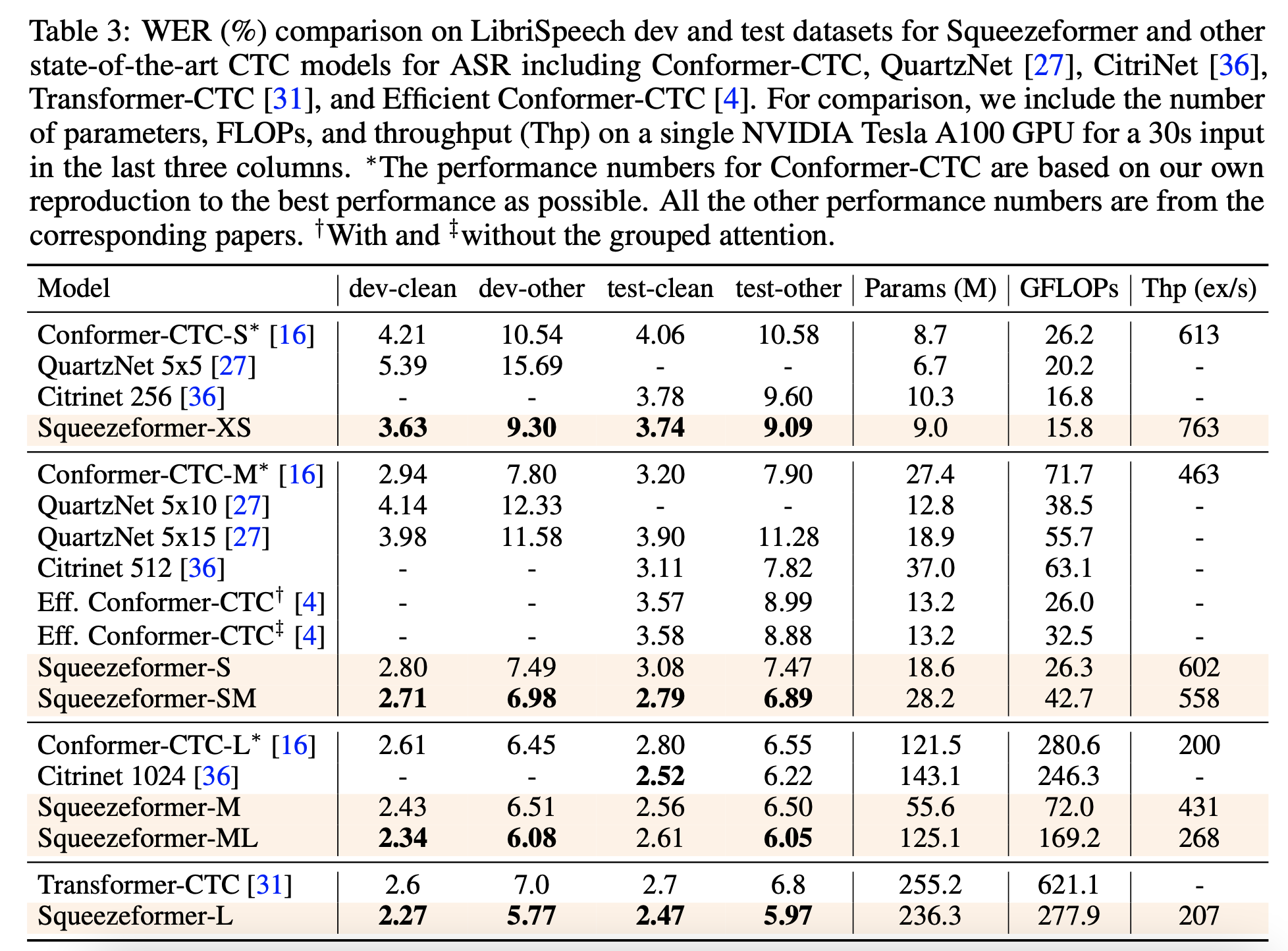
消融实验结果
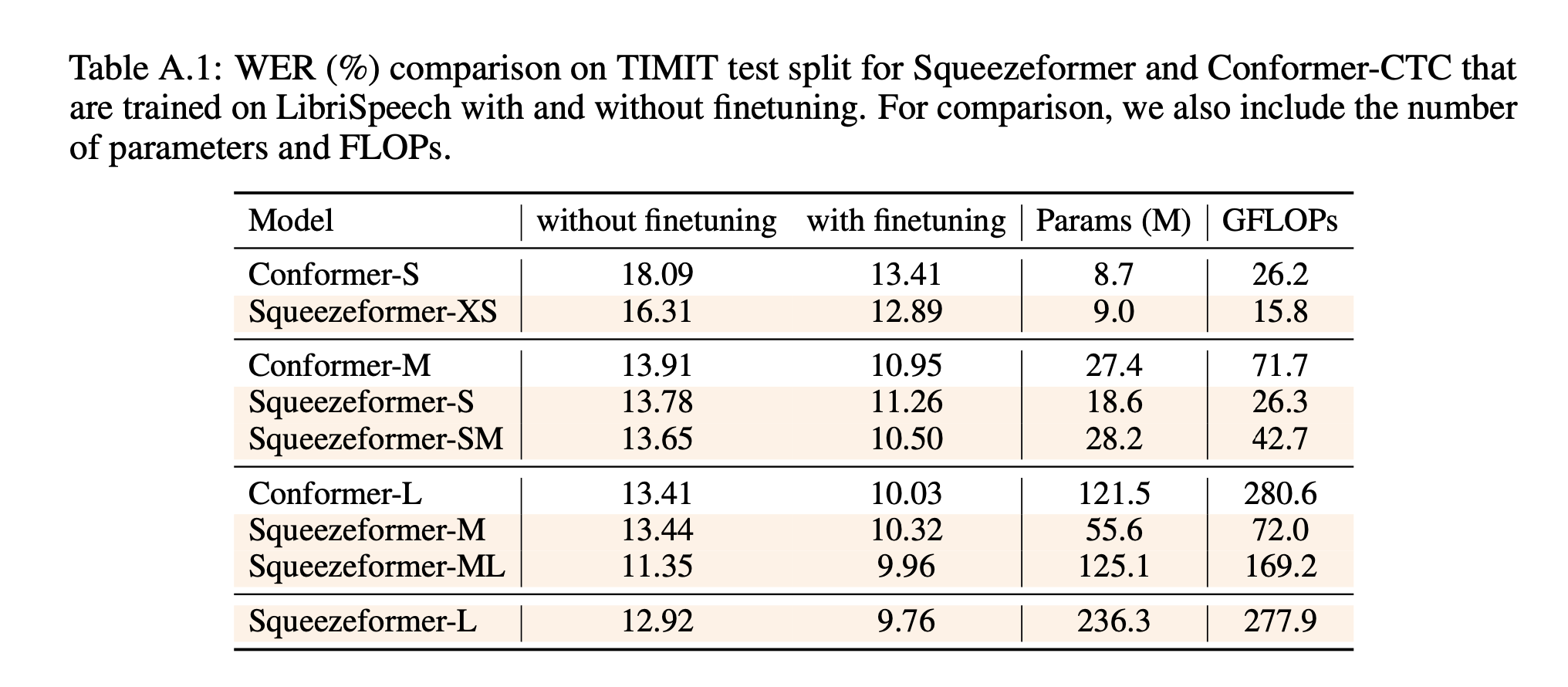
TIMIT 上的补充实验
- 本文标题:语音识别 | Squeezeformer:高效的语音识别方案
- 创建时间:2022-11-16
- 本文链接:2022/11/16/2022-11-16_squeezeformer/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!