
- RetrieverTTS: Modeling Decomposed Factors for Text-Based Speech Insertion
- https://arxiv.org/abs/2206.13865
论文摘要
本文旨在研究基于文本的语音编辑任务,同时也可以作为整条文本语音合成的模型。RetrieverTTS 提出了一种「分解+编辑」的新范式,能够将语音中的全局和局部信息进行分解,从而在语音编辑中,保持全局信息和局部信息的统一性,在音色上具有全局的统一性,在韵律上具有局部的连续性和平滑性。
论文提出了 Cross-Attention 和 Link-Attention 两种新的模块,使用多个 token 作为全局信息的表征基础,然后将提取出来的全局信息通过 Link-Attention 更强地引入到建模过程中。此外,对于语音编辑任务,论文提出使用「韵律平滑」 的方式,能够建模得到上下文感知的局部信息,从而保持语音编辑任务中韵律的连续性。
最终,RetrieverTTS 在语音编辑甚至是 zero-shot 的 TTS 任务上,都达到了领先的自然度和音色相似度。
论文背景
基于文本的语音和视频编辑成为产业界的应用热点之一。通常的语音编辑系统支持:剪切、复制、插入等操作。在这些操作中,基于文本在相应位置插入语音片段是最具挑战性的。不仅仅要求语音合成的质量,而且需要在语音的音色和韵律上与前后上下文的语音保持一致性。
相关工作一:基于文本的语音插入可以视为一个 zero-shot 的基于上下文的语音合成任务。前人的工作中,主要是将文本提取出的 embedding 高层表征插入到编码后的梅尔序列中,使用 decoder 将其解码出目标的语音。但是这类方法,通常只能编辑很短的语音,而且需要较大的网络来建模,模型的训练比较难收敛较慢。
相关工作二:基于 speaker 信息的语音生成,也就是通常的 speaker adaptation 任务。对于少样本条件,可以微调整个模型后在目标音色上达到尚可的效果,但是需要多次模型迭代;对于本文研究的方向,零样本条件 zero-shot 的建模方案更加适合,即从参考音频中抽取出音色的表征向量,不需要重新微调模型,但是缺点也很明显,就是音色相似度上往往达不到较优的效果。而且对于语音编辑场景,这种方案没有关注到合成语音在原始语音中上下文的连续性。
相关工作三:另一个相关的领域就是 zero-shot voice conversion,语音转换任务。这类方法主要将 speaker 信息和语音的内容信息进行解耦,抽取出与内容无关的说话人信息表征,能够将 TTS 系统合成的语音转换到任一新的说话音色上。但是这一算法的流程是:合成语音再转换为目标的音色,流程过于冗杂,不如直接根据文本生成目标音色的语音。
本文任务,语音可以分解为全局因子(global factor)和局部因子(local factor)两部分,全局的因子表示说话人的音色/风格,通常和上下文的文本不相关,只要是同一个说话人,不管内容如何,抽取出的全局因子都应该是保持一致的;局部因子则通常表示语音的韵律信息,是和上下文紧密相关的。
在上述思想的引导下,本文采用全局和局部因子分解建模的方式,将语音分解为:文本(内容)、韵律、音色和风格四个大类。其中韵律又可以体现在音素持续时长、pitch 变化、能量变化等细节之处;而音色和风格则是偏向于全局的信息。
RetrieverTTS
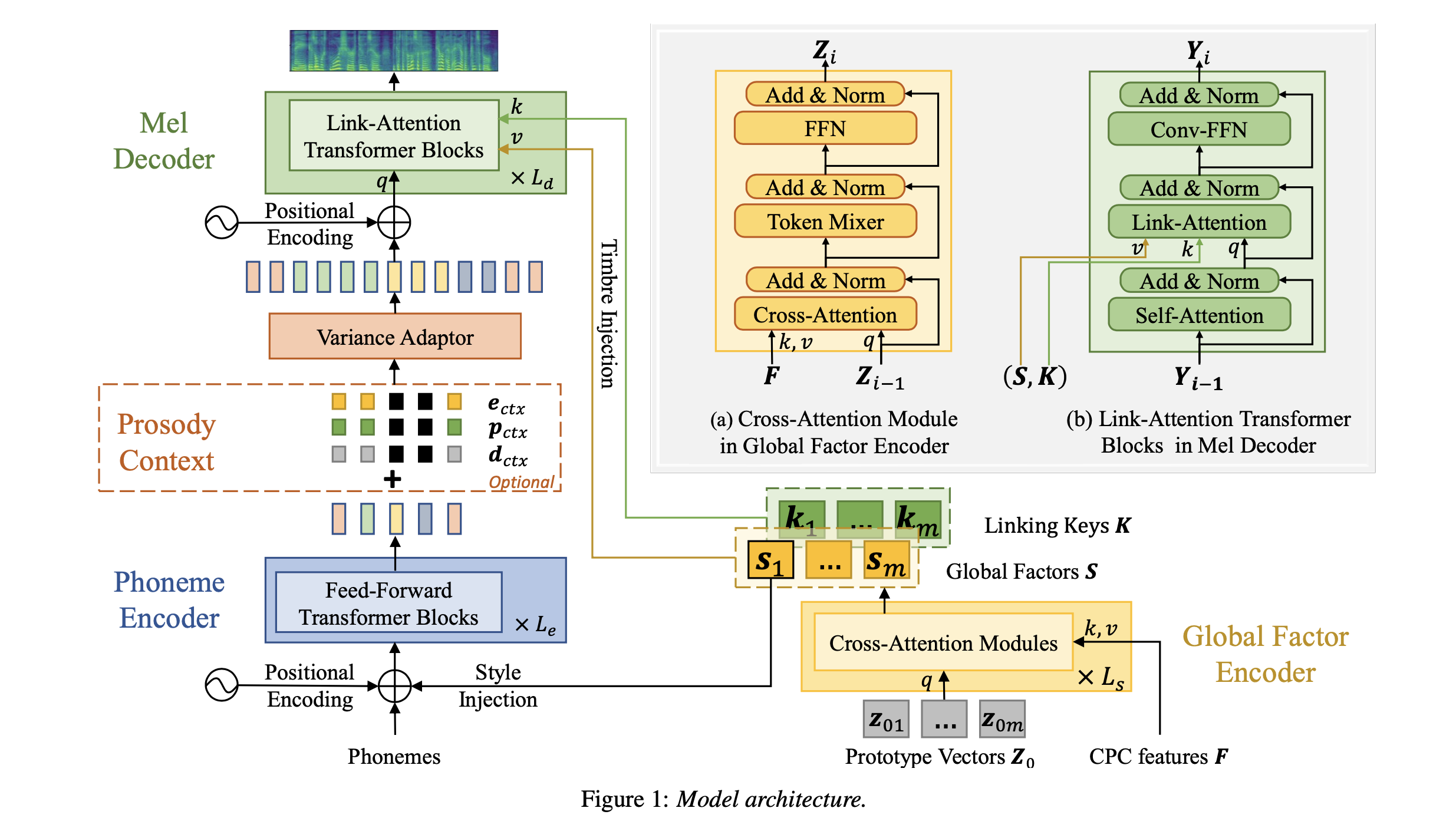
论文的主题结构采用的是 FastPitch,phoneme encoder 用于学习提取局部的因子。论文提出了 Cross-Attention 模块用于提取全局的信息,再将局部和全局的信息,通过 Link-Attention 操作融合在一起,在 decoder 模块进行建模。
关于 Phoneme Encoder 和 Variance Adaptor,论文采用和 FastPitch/FastSpeech2 完全一致的操作,剩下的基于 Cross-Attention 的 global factor encoder 和基于 Link-Attention 的 Mel Decoder 才是论文的重点。
1. global factor encoder
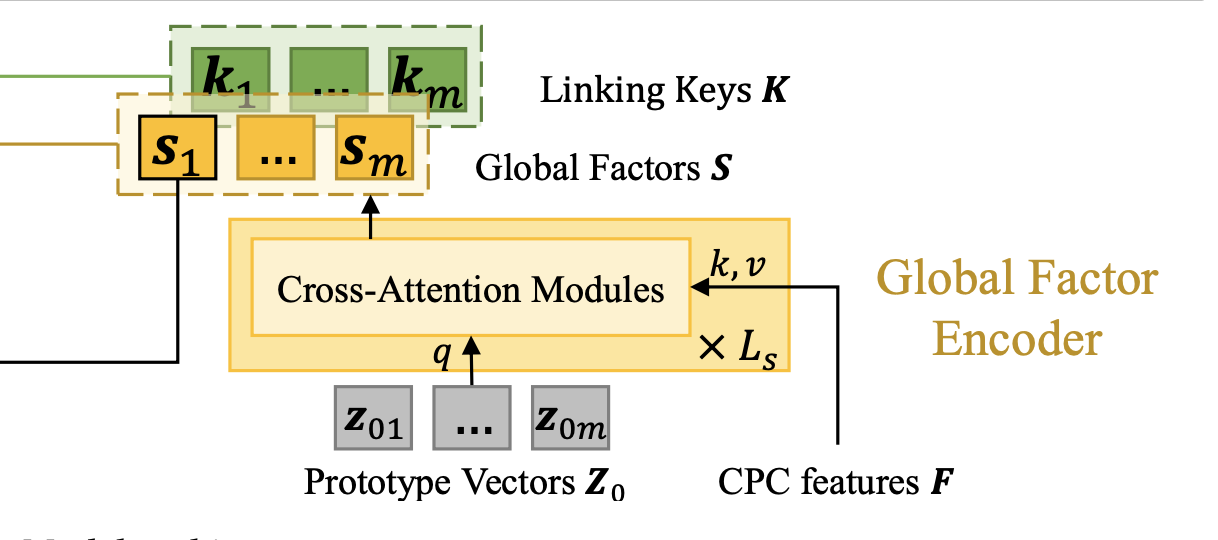
输入是预训练的 CPC 特征,作为 attention 的 key 和 value,attention 的 query 是一组可训练的参数,称为 prototype vectors,包含 m 个向量。m 是超参数,论文选择 m = 60。
Cross-Attention 包含三层,除第一层使用可训练的参数作为 attention 的 query 之外,其他层的 attention 均使用上一层的输出作为 query。最终 global factor encoder 模块的输入包含 m 个 global factors 向量。论文选择将第一个向量 s1 作为全局的音色特征表征,拼接到输入端 phoneme encoder 的输入上。
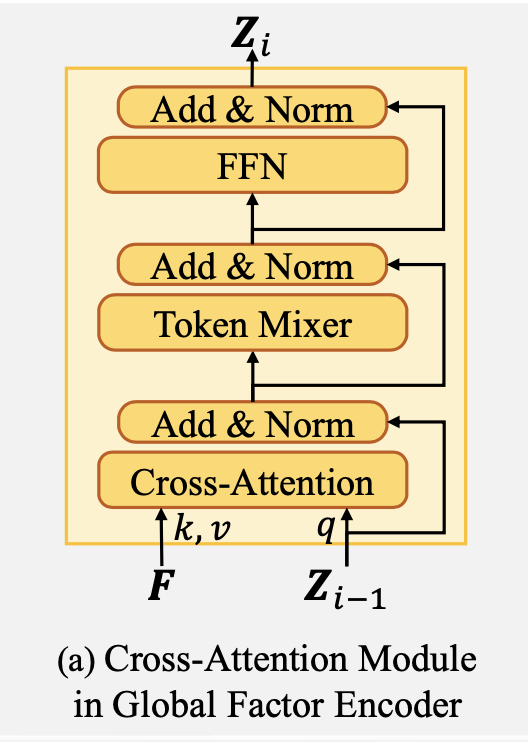
关于 Cross-Attention 的内部细节,如上图所示,其中 token mixer 论文中没有过多表述。本人的实验过程中发现使用 self-attention 的效果非常不错。
2. link-attention mel decoder
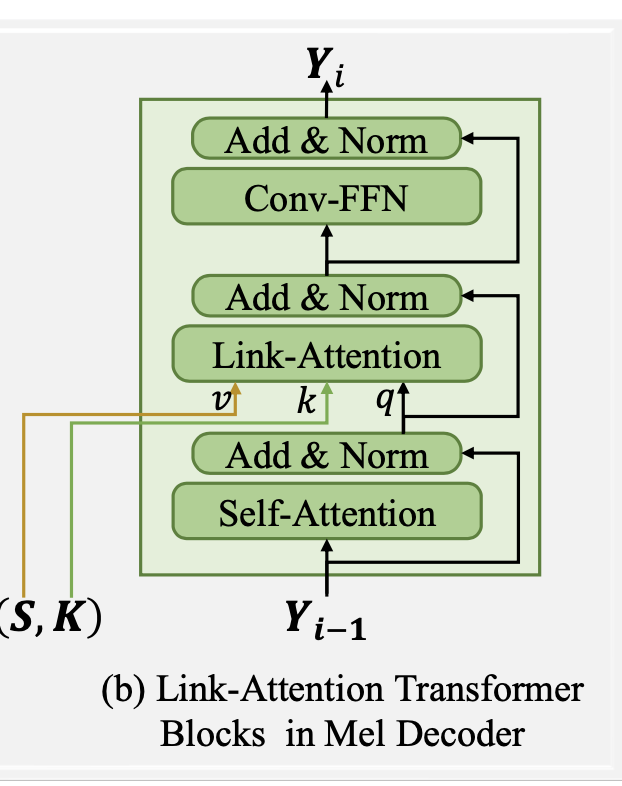
关于 Link-Attention 模块,输入首先经过 self-attention 模块,self-attention 的输入是 phoneme encoder 经过 variance adaptor 后的输出,self-attention 模块的输出经过 add+norm 作为 link-attention 的 query。Link-Attention 的 key 是另外一组可训练的参数,而 value 则是 global factor encoder 输出的 m 个 global factor 向量。
3. 关于模型的训练
使用 duration/pitch/energy 三种额外信息的 MSE 损失函数 + 梅尔重建损失函数。原始论文使用的是一个联合训练的对齐模块,因此还需要包含一个对齐损失函数。
为了模拟插入语音的操作,在训练过程中,论文引入了韵律平滑的训练策略,在 50 % 的训练样本中,将 GT 得到的 duration/pitch/energy 的 embedding 进行 mask,相当于没有传入这部分音素对应的语音信息,让模型通过上下文进行预测,并且恢复出原始的对应于全部音素的波形。
在训练过程中,为了避免 over-smoothness 过平滑的问题,还引入的 Mel-GAN 的对抗训练,帮助声学模型的建模。
4. 关于模型的推理
RetrieverTTS 有两种推理模式:zero-shot TTS 和 zero-shot 语音编辑。
针对 zero-shot 语音编辑的模式,global factors 和 prosody 信息都是从语音本身提取得到的。对于插入新词后的文本,会得到一个新的音素序列,其中包含了插入词对应的音素。对于原本语音就存在的音素,直接从原始语音中抽取 duration/pitch/energy 等信息,然后新插入的音素部分输入都是零(相当于模拟训练过程中 mask 掉的效果),这种情况下生成完整的语音,然后将插入的文本对应的语音片段抽取出来,插入到真实语音中相应的位置即可。
实验结果
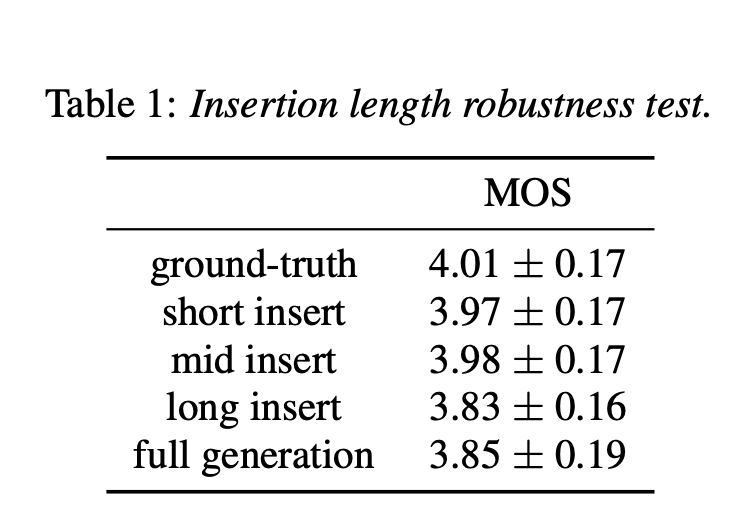
消融实验
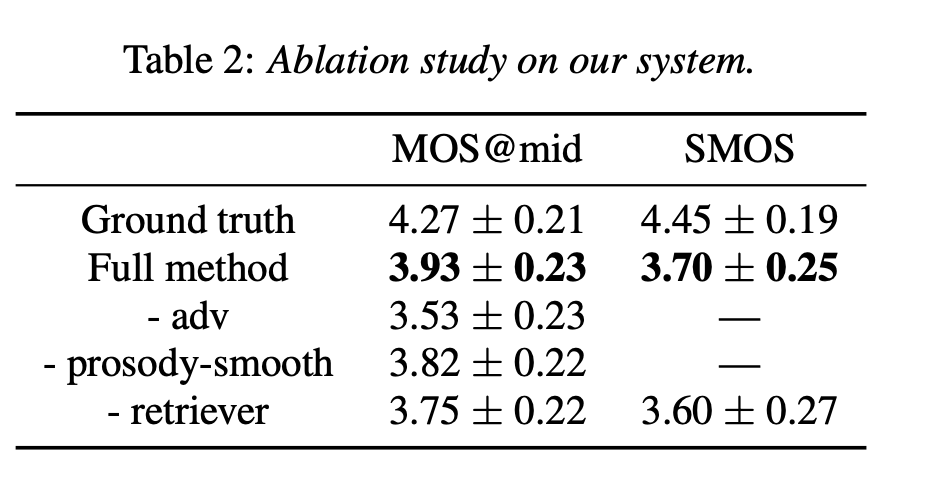
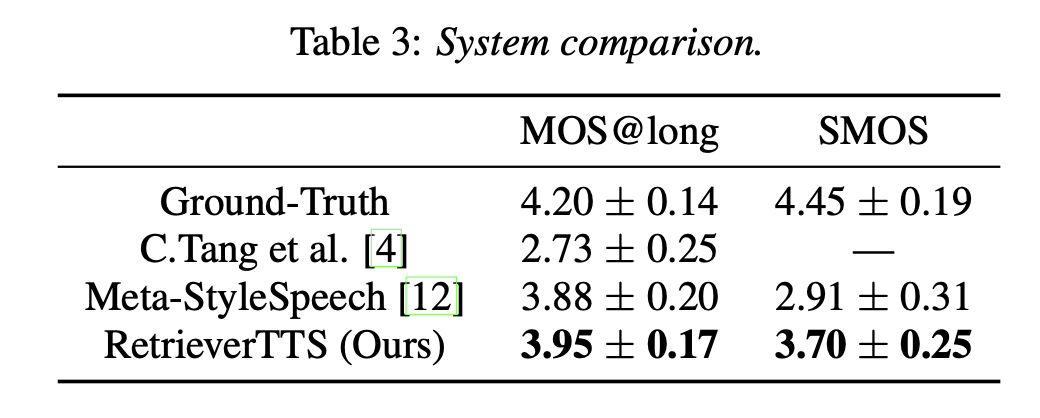
与其他论文工作的对比
- 本文标题:语音合成 | RetrieverTTS:基于 Perceiver 架构的语音合成方案
- 创建时间:2022-11-28
- 本文链接:2022/11/28/2022-11-28_retriever_tts/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!