
- Residual Adapters for Few-Shot Text-to-Speech Speaker Adaptation
- Adapter-Based Extension of Multi-Speaker Text-to-Speech Model for New Speakers
论文的核心思想来源
- Parameter-Efficient Transfer Learning for NLP
以上两篇 TTS 领域的论文都是采用 adapter 的思想对 TTS 模型进行快速 adaptation,从而在新的目标说话人上达到预期的合成效果。这两篇论文的具体细节有所差异,但是核心都是使用 adapter 的思想,增加一小部分针对新目标说话人的参数进行模型的微调。
本页面寻根溯源,对 NLP 领域提出 adapter 的这篇文章进行梳理。
工作背景
大规模预训练模型上进行 finetune 是 NLP 中一种高效的迁移方法,但是对于众多的下游任务而言,finetune是一种低效的参数更新方式,对于每一个下游任务,都需要更新整个语言模型的全部参数,需要庞大的训练资源。进而,人们会尝试固定语言预训练模型大部分网络的参数,针对下游任务只更新一部分语言模型参数。大部分情况下都是只更新模型最后几层的参数,但是我们知道语言模型的不同位置的网络聚焦于不同的特征,针对具体任务中只更新高层网络参数的方式在不少情形遭遇到精度的急剧下降。
本文提出了 Adapter 方法,针对每个下游任务在语言模型的每层 transformer 中新增 2 个带有少量参数的模块,称之为 adapter,针对下游任务训练时只更新 adapter 模块参数,保持原有语言模型的参数不变,从而实现将强大的大规模语言模型的能力高效迁移到诸多下游任务中去,同时保证模型在下游任务的性能。
Adapter 结构
Adapter 的结构中,transformer 的每层网络包含两个主要的子模块,一个 attention 多头注意力层跟一个feedforward 层,这两个子模块后续都紧随一个 projection操作,将特征大小映射回原本的输入的维度,然后连同skip connection 的结果一同输入 LayerNorm 层。
Adapter 直接应用到这两个子模块的输出经过 projection 操作后,并在 skip-connection 操作之前,进而可以将 Adapter 的输入跟输出保持同样的维度,所以输出结果直接传递到后续的网络层,不需要做更多的修改。每层 transformer 都会被插入两个 adapter 模块。
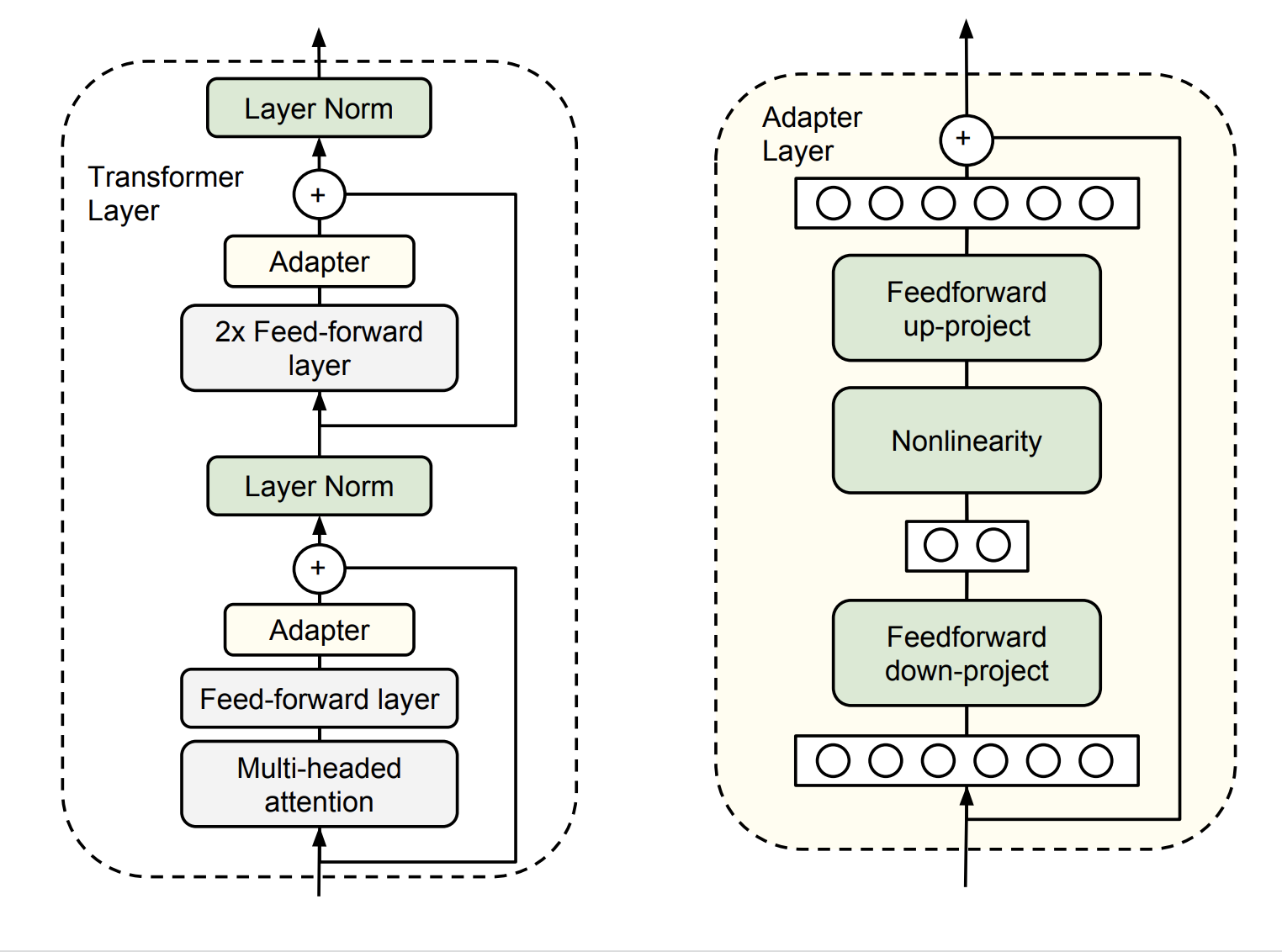
adapter 的具体结构:首先通过 feedforward down-project 的矩阵乘法降低特征维度,然后通过非线性层和一个 feedforward up-project 层将特征维度升到跟输入一样的水平,同时通过一个 skip connection 来将 adapter 的输入重新加到最终的输出中去,这样可以保证保证即便 adapter 一开始的参数初始化接近0,adapter 也有由于 skip connection 的设置而初始化接近于一个恒等映射,从而保证训练的有效性。
adapter引进的模型参数:假设 adapter 的输入的特征维度是d,而中间的特征维度是 m,那么新增的模型参数有:down-project的参数 dm+m,up_project 的参数md+d,总共2md+m+d,由于 m 远小于d,所以真实情况下,一般新增的模型参数都只占语言模型全部参数量的 0.5%~8%。
同时要注意到,针对下游任务训练需要更新的参数除了 adapter 引入的模型参数外,还有 adapter 层后面紧随着的 LayerNorm 层参数需要更新,每个 LayerNorm 层只有均值跟方差需要更新,所以需要更新的参数是2d。(由于插入了具体任务的 adapter 模块,所以输入的均值跟方差发生了变化,就需要重新训练)
通过实验,可以发现只训练少量参数的 adapter 方法的效果可以媲美 finetune 语言模型全部参数的传统做法,这也验证了 adapter 是一种高效的参数训练方法,可以快速将语言模型的能力迁移到下游任务中去。同时,可以看到不同数据集上 adapter 最佳的中间层特征维度m不尽相同。
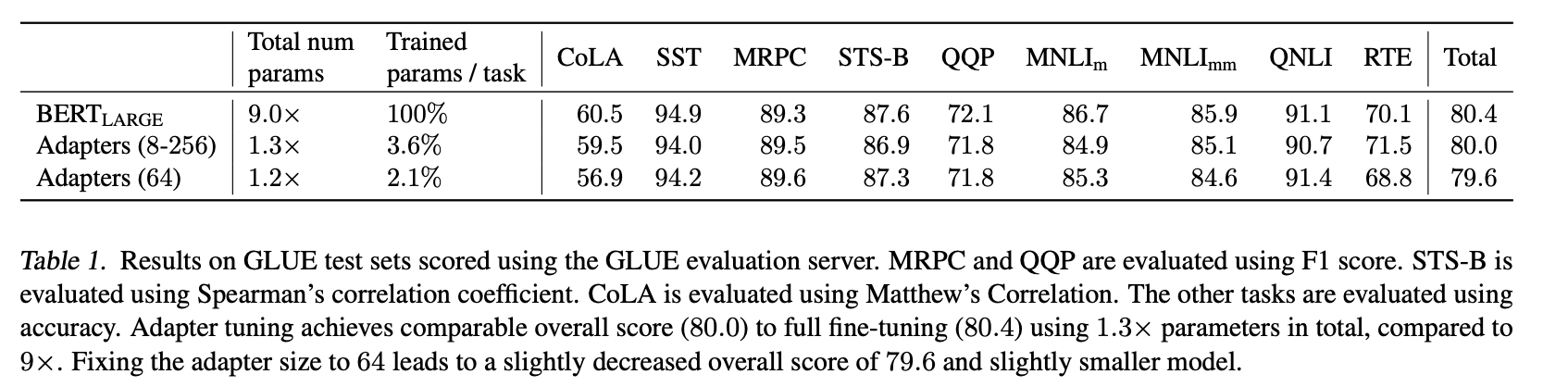
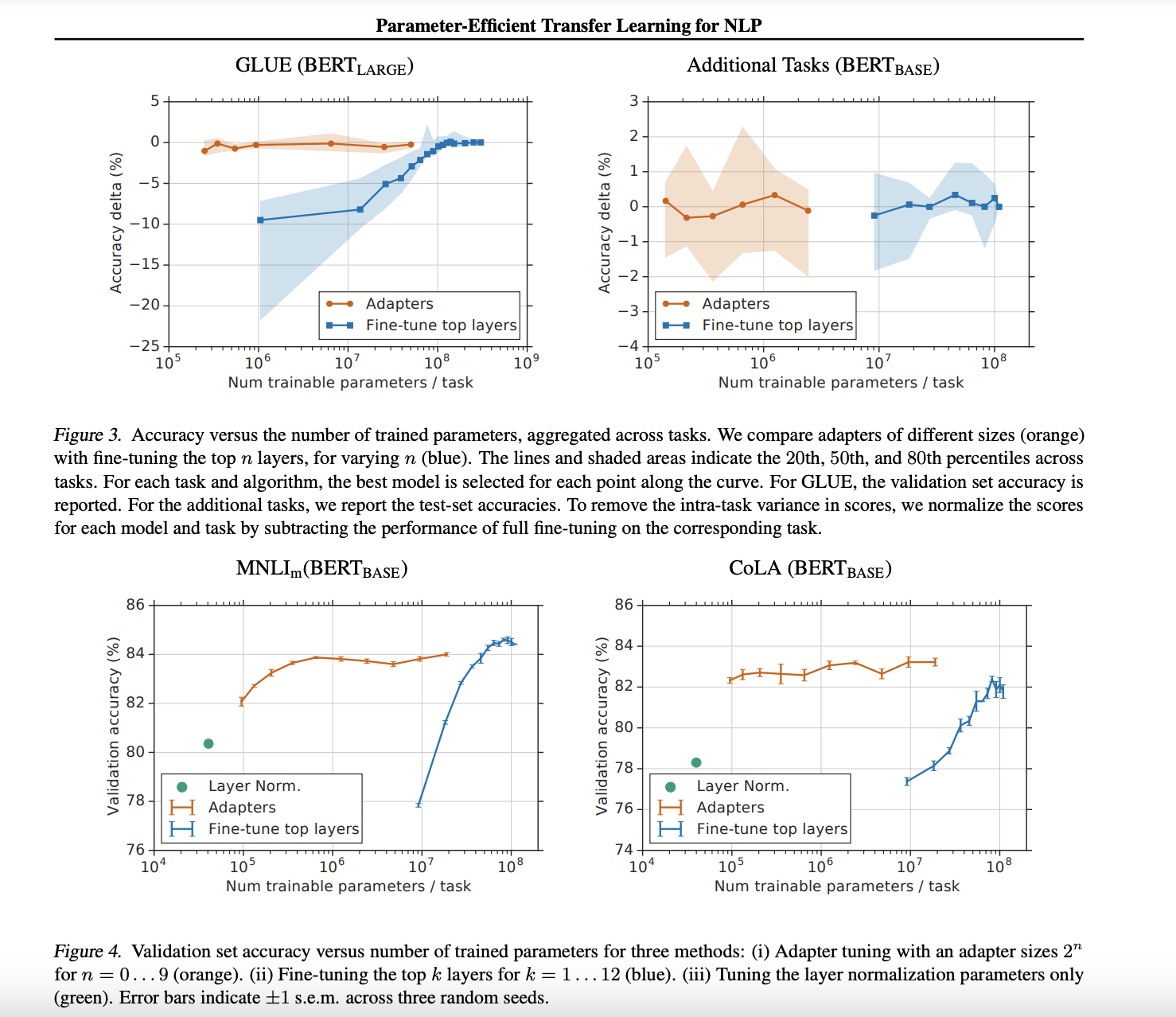
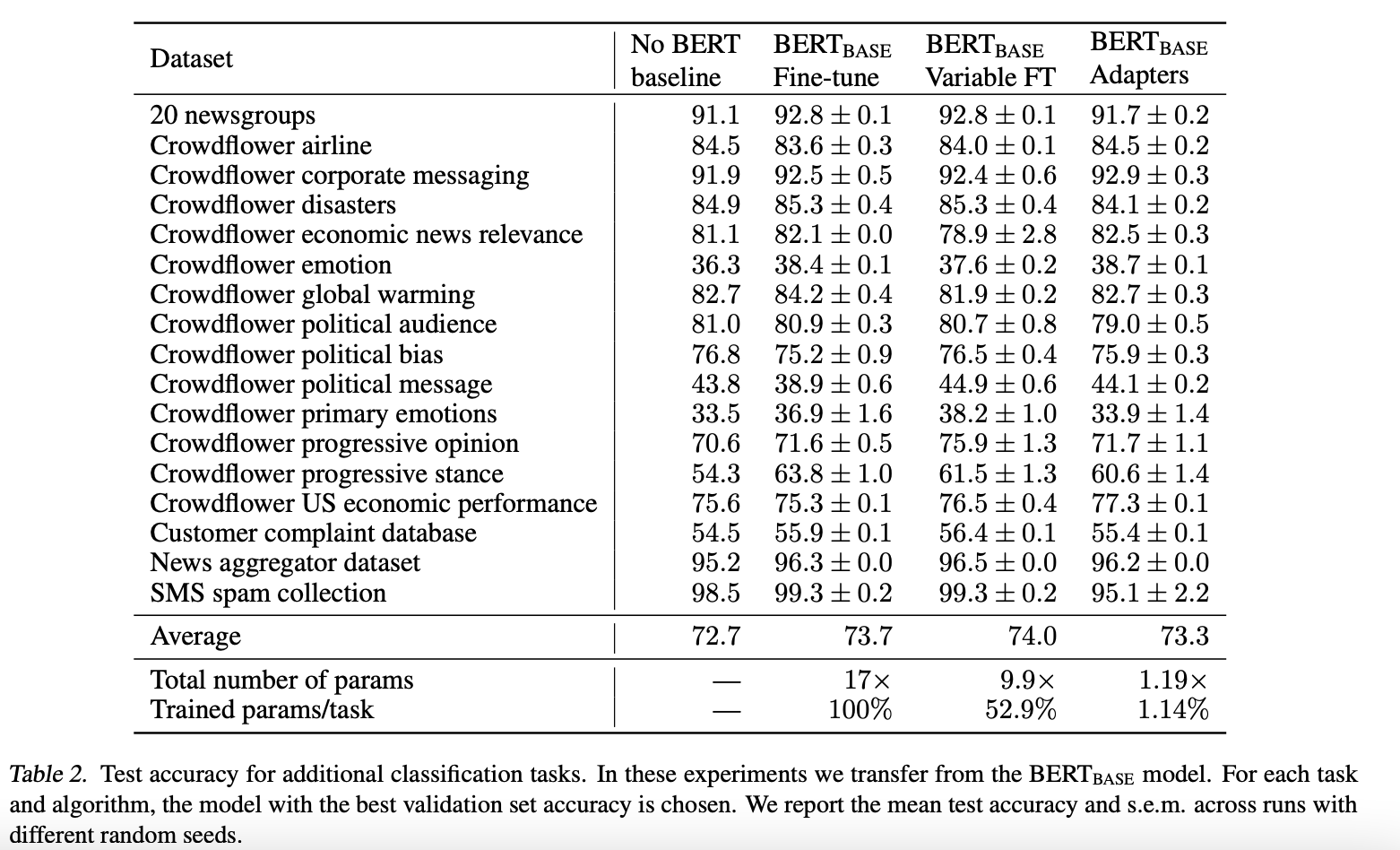
为了进一步探究adapter的参数效率跟模型性能的关系,论文做了进一步的实验,同时比对了 finetune 的方式(只更新最后几层的参数或者只更新 LayerNorm 的参数),从结果可以看出 adapter 是一种更加高效的参数更新方式,同时效果也非常可观,通过引入 0.5%~5% 的模型参数可以达到不落后先进模型 1% 的性能。
Google 的 Residual Adapters
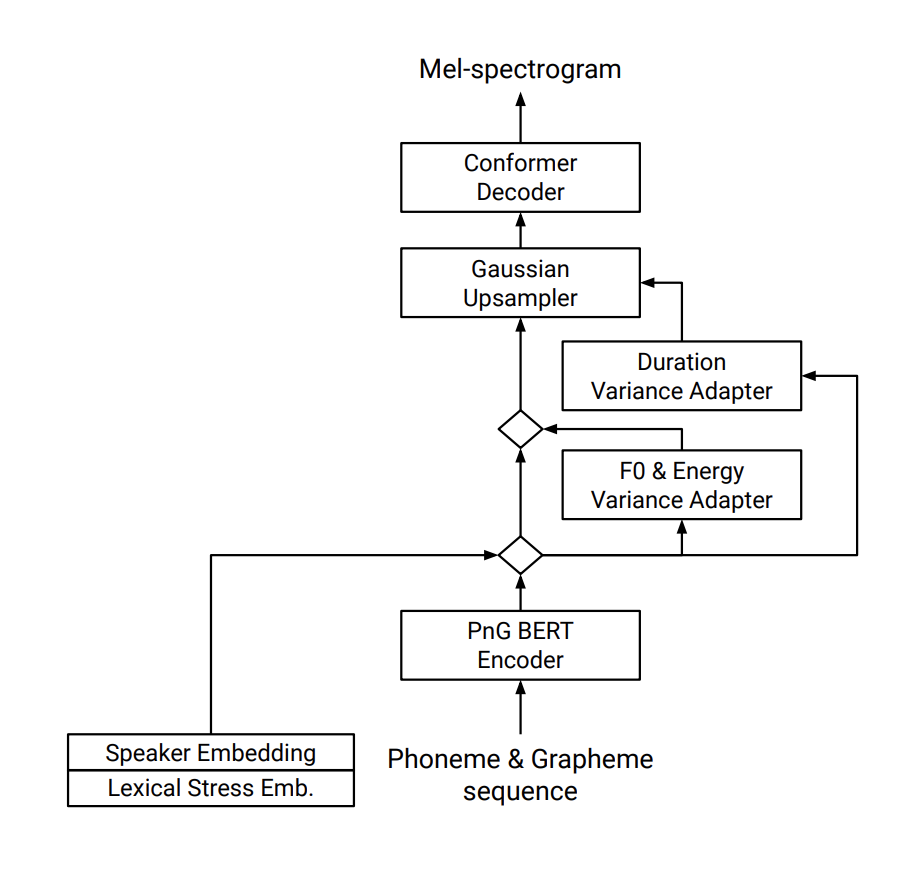
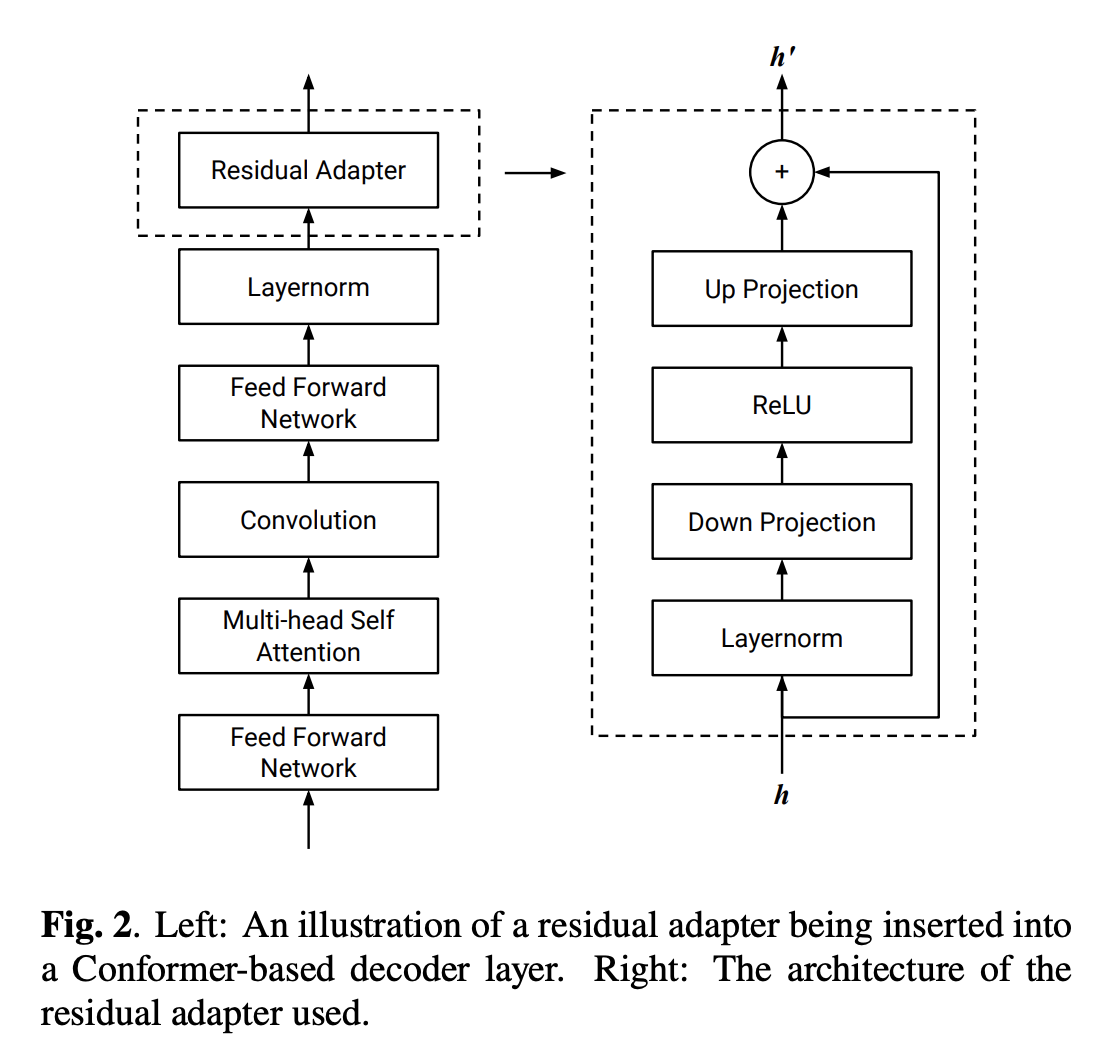
相当于在 Conformer Decoder 的基础上增加了带有残差的 adapter 结构。
NVIDIA 的 Adapter-based TTS
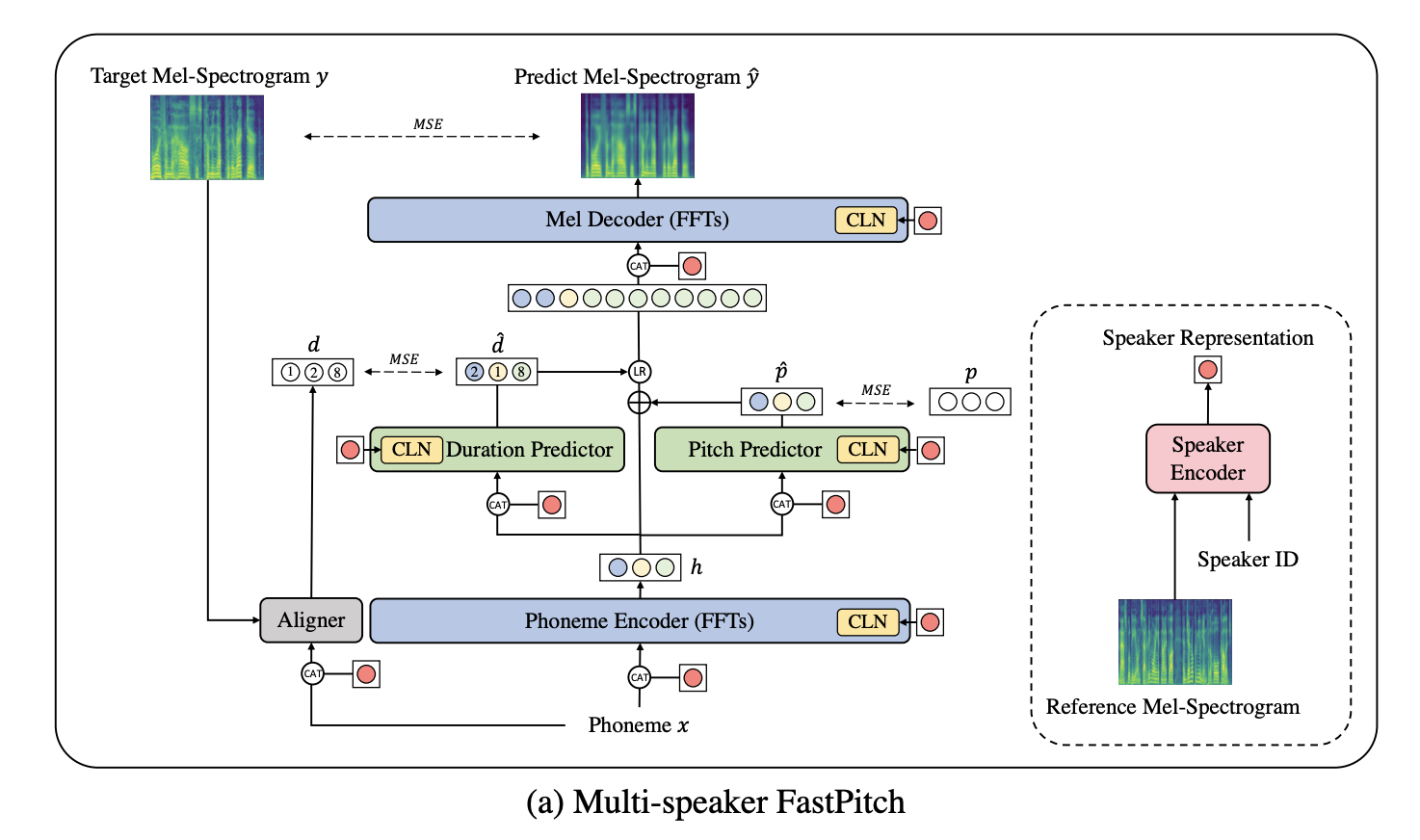
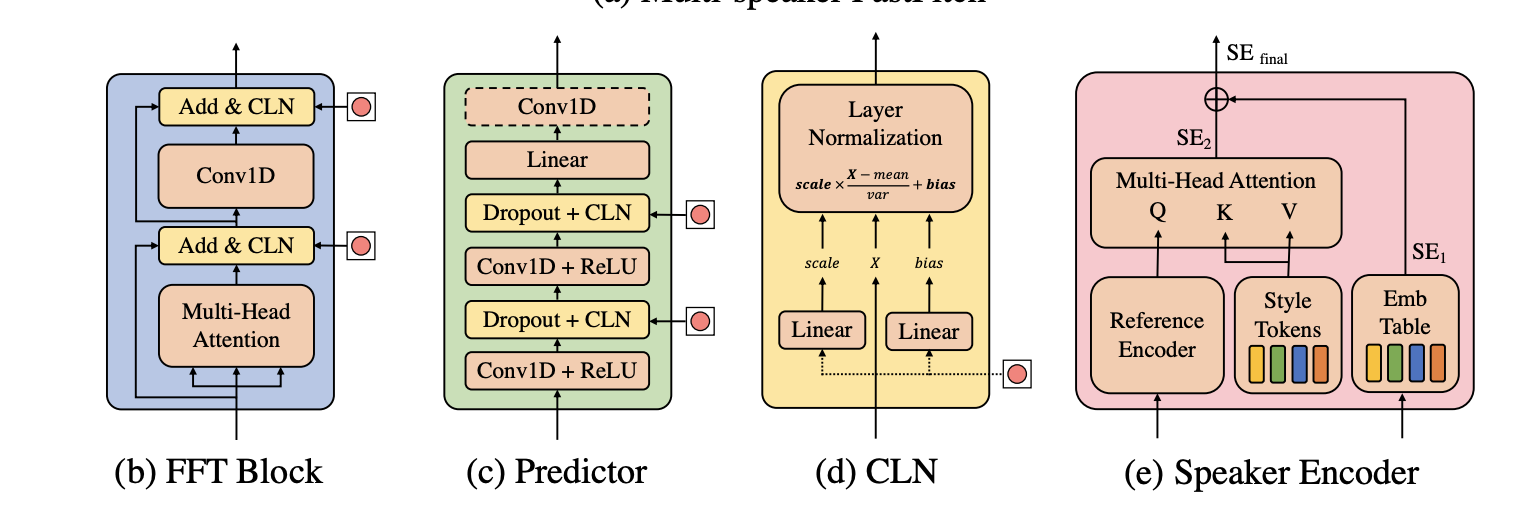
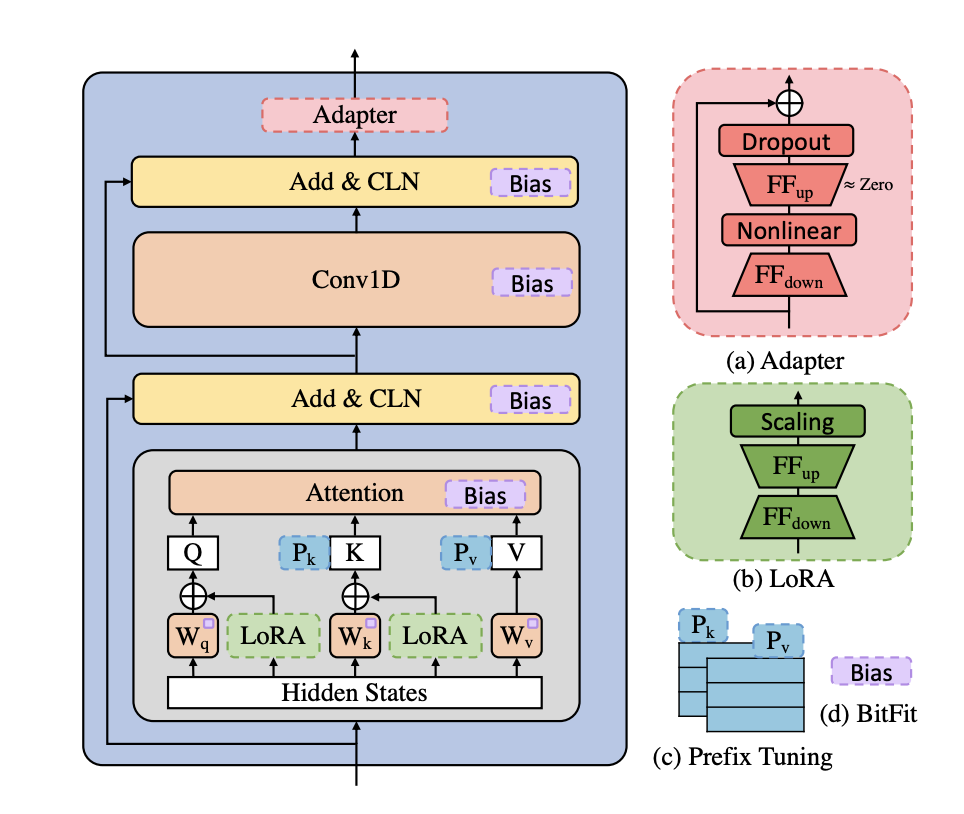
NVIDIA 的论文创新点更多:
- 包含 Layernorm 的模块都采用了 Conditional LayerNorm 的配置,条件依赖于说话人表征
- 说话人表征采用两种表征方式的加权:speaker embedding table + 基于 GST 的表征
- 在 FFT (FeedForwardTransformer) 模块中,增加了 adapter 等 adaptation 的方法
参考代码及论文
- https://github.com/thuhcsi/interspeech2022-cdfse-tts
- https://github.com/google-research/adapter-bert
- https://github.com/NVIDIA/NeMo/tree/tts_adapters
- https://github.com/rabeehk/hyperformer
- https://github.com/dongzelian/SSF
- https://github.com/google-research/vision_transformer/blob/main/vit_jax/models_mixer.py
- Simple, Scalable Adaptation for Neural Machine Translation
- Compacter: Efficient low-rank hypercomplex adapter layers
- Parameter-efficient multi-task fine-tuning for transformers via shared hypernetworks
- Conditionally adaptive multi-task learning: Improving transfer learning in nlp using fewer parameters & less data
- Lst: Ladder side-tuning for parameter and memory efficient transfer learning
- Towards a unified view of parameter-efficient transfer learning
- 本文标题:专题分享 | 基于 Adapter 的少样本 TTS 方案
- 创建时间:2022-12-22
- 本文链接:2022/12/22/2022-12-22_tts_adapter/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!