
- Improved Techniques for Training GANs
- NeurIPS 2016 pdf
在 GAN 的工作的基础上,本论文提出了 GAN 训练不稳定且难收敛的问题。训练 GAN 的过程相当于是寻找非凸博弈中的纳什均衡点;但 GAN 的训练方法一般是梯度下降,求解使得代价函数最小的模型参数,而不是直接寻找纳什均衡点,所以可能会存在模型不收敛的现象。
论文的主要贡献是:
- 提出了 feature matching 特征匹配和 minibatch features 小批量特征等方法
- 提出了评估 GAN 的生成效果的 Inception Score 的方法
改进一:feature matching
主要思想是:在生成器 G 端增加新的目标函数,防止在判别器 D 参数固定的情况下过度训练。对于 G 生成的样本,不再只是要求 max log(p2) 最大化生成样本被判断为真实样本的概率,而是要求生成样本和真实样本在一些「统计量」上更加相近。
所谓的「统计量」/「统计指标」,实际上是用判别器 D 来获取的,比如用判别器的神经网络的中间层的输出作为特征,要求生成样本和真实样本经过 D 的某些层后的输出保持相近,增加的损失函数是 L2 范数的平方误差损失。
注意:这个 feature matching 是在 D 参数固定的情况下,优化 G 时补充的损失函数;所以在优化 D 时没有这个新目标函数,就按 GAN 的原始交叉熵损失函数来训练即可。
改进二:minibatch discrimination
重要问题:GAN 在训练过程中存在一类失败现象 (mode collapse,即:模式崩塌),体现在模型学到了一组参数,这样的参数导致输出的结果是不变的。
论文分析原因是:GAN 在区分样本的时候是独立不相关的,整个训练过程没有针对生成器生成的样本进行相似度的判定,也就是说:没有可以强调让生成器生成的样本之间各不相同。这就可能导致,如果生成了一个让判别器认为很可能是真的样本,那么生成器就可能都向着这个生成的样本去靠近。
因此论文提出了 minibatch discrimination,每次会使用多个生成样本,同时判断这多个生成样本之间的相似性。相似性的指标来自:样本经过判别器之后的某个中间层的输出,再映射到矩阵,然后计算矩阵行向量之间的 L1 距离,作为一个指标。对于 minibatch 内的每个样本,都可以计算出它和其他样本之间的相似度向量,作为该样本的一个额外输入。这样处理的最终结果,就是 minibatch 的每个样本,都额外输入了一个表征它和 minibatch 内其他样本的区别度的特征。
改进三:Historical averaging
更新生成器和判别器时,增加额外的损失函数项,相当于更新后的参数,尽可能多次迭代的参数平均值相近。
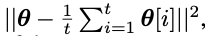
改进四:One-sided label smoothing
label smoothing 本身是为了让模型训练时学习的 label 不会过于 hard,比如将 0-1 的分类标签换为 0.1-0.9,能够提高模型对对抗样本的鲁棒性,提高模型的稳健性。

相比于传统的 Label Smoothing,GAN 的训练只对正例的概率进行的平滑到 α 的操作,负例仍然使用类别0
评价指标:Inception Score
GAN 模型的评价从客观指标上来说确实比较难评价。本篇论文还有一个突出的贡献就是提出了 Inception Score 的客观评价指标,验证了和人工打分的正相关性。
使用 Inception 模型给每个生成的图片样本计算概率分布。对于单个样本来说,如果包含明确的东西,概率分布会比较集中(集中在某个类别);对于所有类别的样本来说,生成样本的多样性会很多,说明每个类别都会有「概率集中在这个类别的」样本,所以整体的最终指标是:
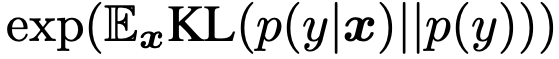
论文提出,如果使用 Inception Score 的指标,最好是在一个很大的样本集合上来计算,这样数值更加具有统计意义。参考页面:https://medium.com/octavian-ai/a-simple-explanation-of-the-inception-score-372dff6a8c7a
- 本文标题:专题分享 | GAN 系列之二:GAN 的改进
- 创建时间:2023-03-21
- 本文链接:2023/03/21/2023-01-27_gan_improved/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!