
- Mega-TTS 2: Zero-Shot Text-to-Speech with Arbitrary Length Speech Prompts
- https://arxiv.org/abs/2307.07218
论文介绍
本文延续了 Mega-TTS 的思想,仍然是认为 TTS 认为需要利用上语音信号的先验信息(内容、音色、韵律、相位是不同的特性,分别设计模块来建模)。但是 Mega-TTS 集中解决的是,如何使用更长的(不定长的)prompt 参考音频,来使得 Mega-TTS 达到更好的效果。相当于利用上更多的更充分的音色、韵律信息,帮助零样本 TTS 达到更好的迁移效果。
论文相比于Mega-TTS,主要的改进点包括:
- 使用多条参考音频的音色提取器(Multi-Reference Timbre Encoder,MRTE),可以从多条参考音频提取更靠谱的音色信息;
- 使用更长的音频训练 P-LLM 模块,达到更强的韵律建模效果;
- 将时长预测模块 duration predictor 也修改为自回归建模方式,推理时可以加入 prompt,从而具备了 in-context learning 的能力;
- 论文还引申了将多个韵律输出的结果进行组合的方式,从而得到更具表现力、更可控的韵律合成效果。
论文还特别提到了模型的一个用处:P-LLM 使用的 prompt 可以使用其他说话人的音频提取的 code,这样可以保持音色像某一个人的同时,说话的韵律更像另一个人。
论文方法
论文思想
更长的 prompt 音频,能够带来的提升主要集中在发音和韵律两方面(音色相似度倒不要求 prompt 音频的长度越长越好)。

模型主体结构
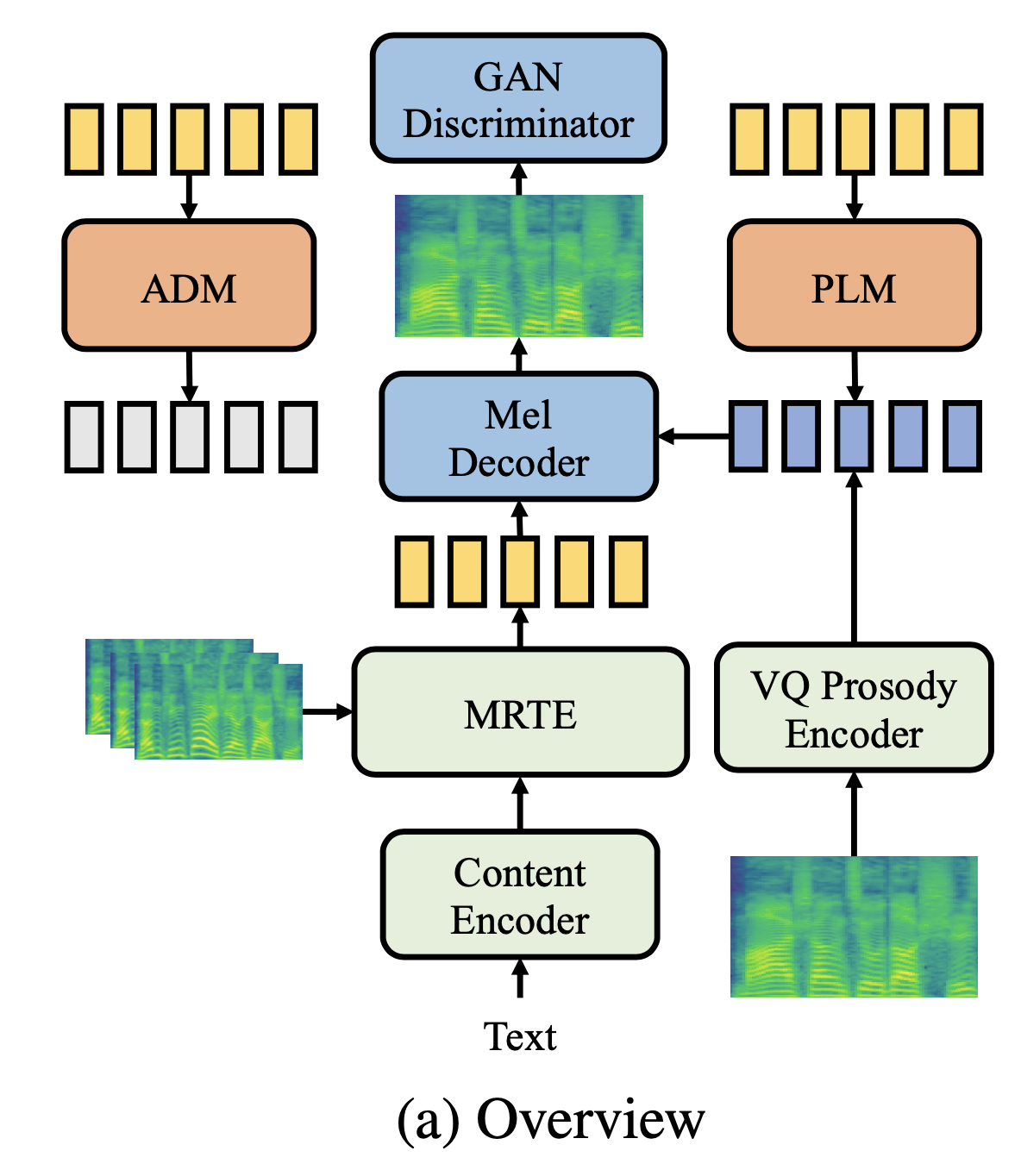
模块一:MRTE 多条参考音频的音色 encoder
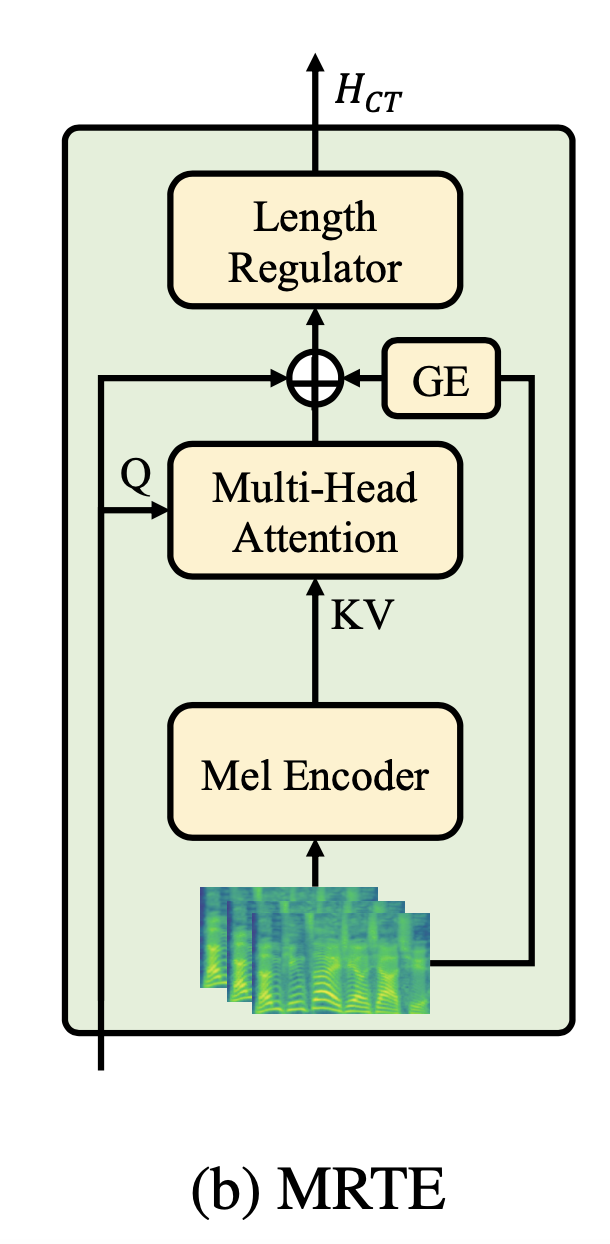
传统的基于 Speaker Encoder 的音色表征方式,假定的音色是一个片段级别的全局的表征,而忽略了音色的时变特性。相比 Mega-TTS,本文强调了音色可能会随着表达的语义不同而发生时序的变化。
论文将 timbre encoder 进行了增强,除了之前 speaker encoder 的 global encoder(GE)建模方式之外,还使用了一个 mel-to-phoneme 的 cross-attention 模块。该模块的 query 输入是 phone-level 的 content encoder 的输出 embedding,key 和 value 都是「多条参考音频 mel 特征」经过 Mel Encoder 之后的输出。
将 phone-level 的音色表征和全局的音色表征拼接到一起,即可得到最终的音色表征。音色的表征会和 phone-level 的 embedding 相加之后再使用 length regulator 进行扩帧。
模块二:P-LLM 韵律语言模型
使用多条音频训练 P-LLM 的思路很简单,就是将多条同一说话人的参考音频在时间维度上进行拼接。每个 batch 内,最大的参考音频帧数为 32k 帧。在训练阶段,只会将模型当作一个普通的语言模型来训练,不特别区分哪一段是 prompt。整条音频使用 teacher-forcing 的方式,训练目标即为 prosody code 预测的交叉熵损失函数。
推理阶段,使用 prompt 对应的 prosody code 自回归给出待合成文本的 prosody code。
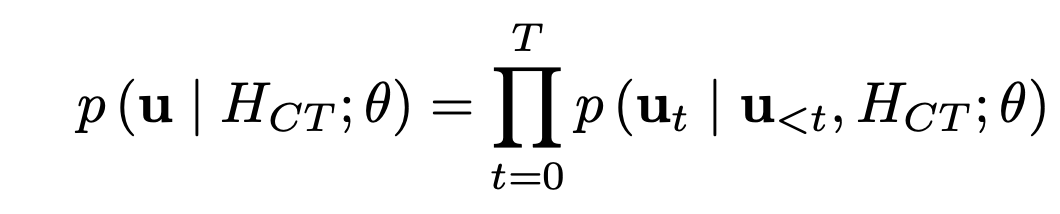
content 和 timbre 则是用待合成文本预测得到的,基于 prosody + timbre + content 三个信息,即可使用 mel decoder 得到目标的梅尔特征。
模块三:ADM 自回归的时长预测模型
phoneme-level 的时长预测模块采用自回归结构,这样也能具备 in-context learning 的能力。模型结构和 P-LLM 完全一样,只不过输入编程 duration 的连续值(不是离散的 prosody code),训练的目标也不是交叉熵而变成了 MSE 损失函数。
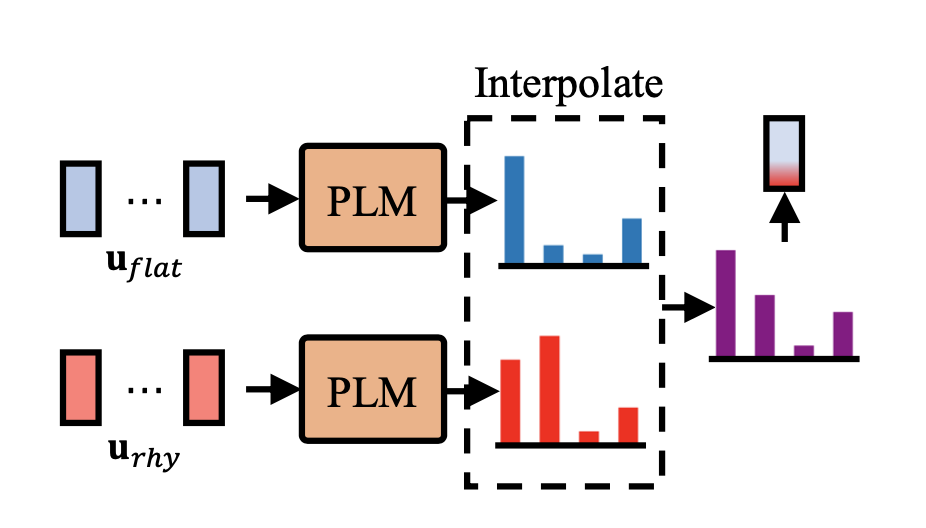
灵活使用:韵律的插值
应用场景:使用目标说话人的音色,但是替换成另外一个人的韵律;或者采用插值的方式将不同的多种韵律风格结合在一起。示例:
本来一个说话人 A 说话比较平,没什么特别强的韵律变化;另一个说话人 B 说话人抑扬顿挫的、表现力比较丰富。现在的目标是想用 A 的音色生成 B 那种韵律的音频,解决方法:
先使用说话人 B 的音频提取表现力丰富的 prosody code,再从说话人 A 的音频提取比较平的 prosody code,分别用 P-LLM 模型对两个 prompt 自回归式地生成待合成文本对应的 prosody code 概率分布,自回归的每个 step,都将两个概率分布值加权即可。
实验细节
训练数据:38k 小时,包含中英文常见的开源 ASR 数据集。
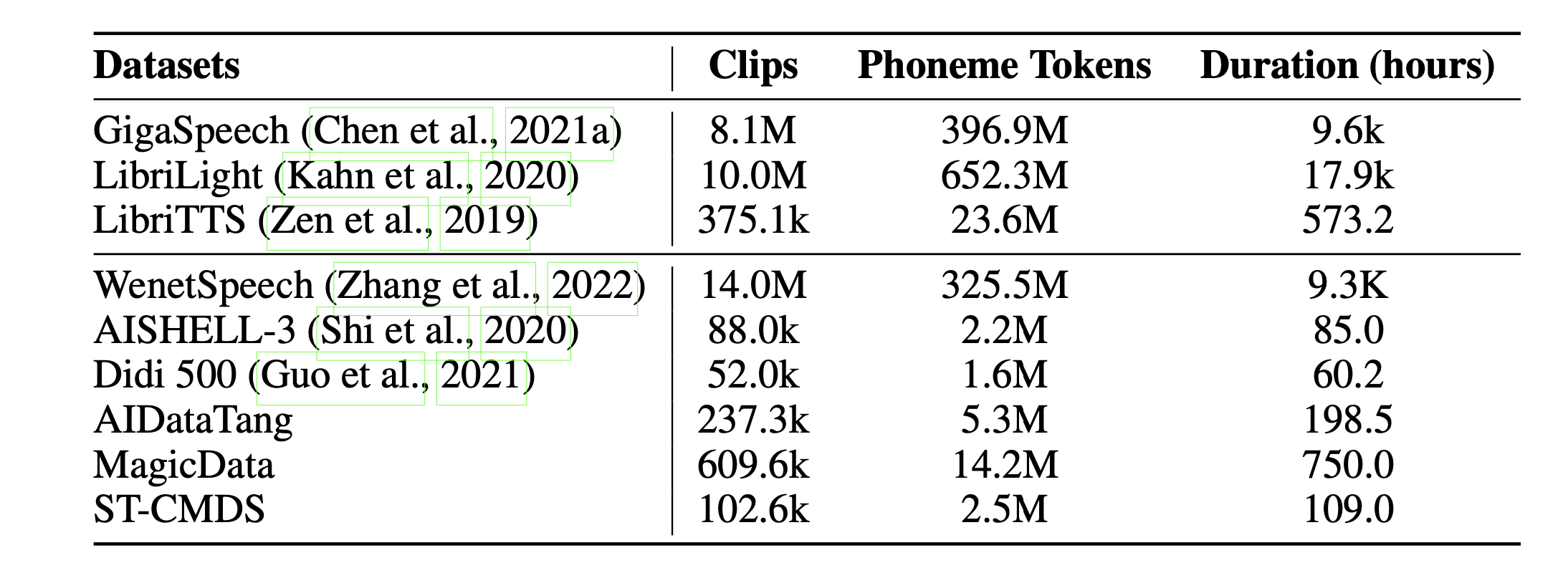
参数量:P-LLM 使用的 24 层的 decoder-only 的模型,参数量高达 1.2B;duration predictor 的自回归采用 decoder-only Transformer 8 层的结构。
训练和推理的流程和 Mega-TTS 基本没有区别,只是支持了多条参考音频进行推理;推理阶段采用 top-1 的采样策略。
对比实验的配置信息
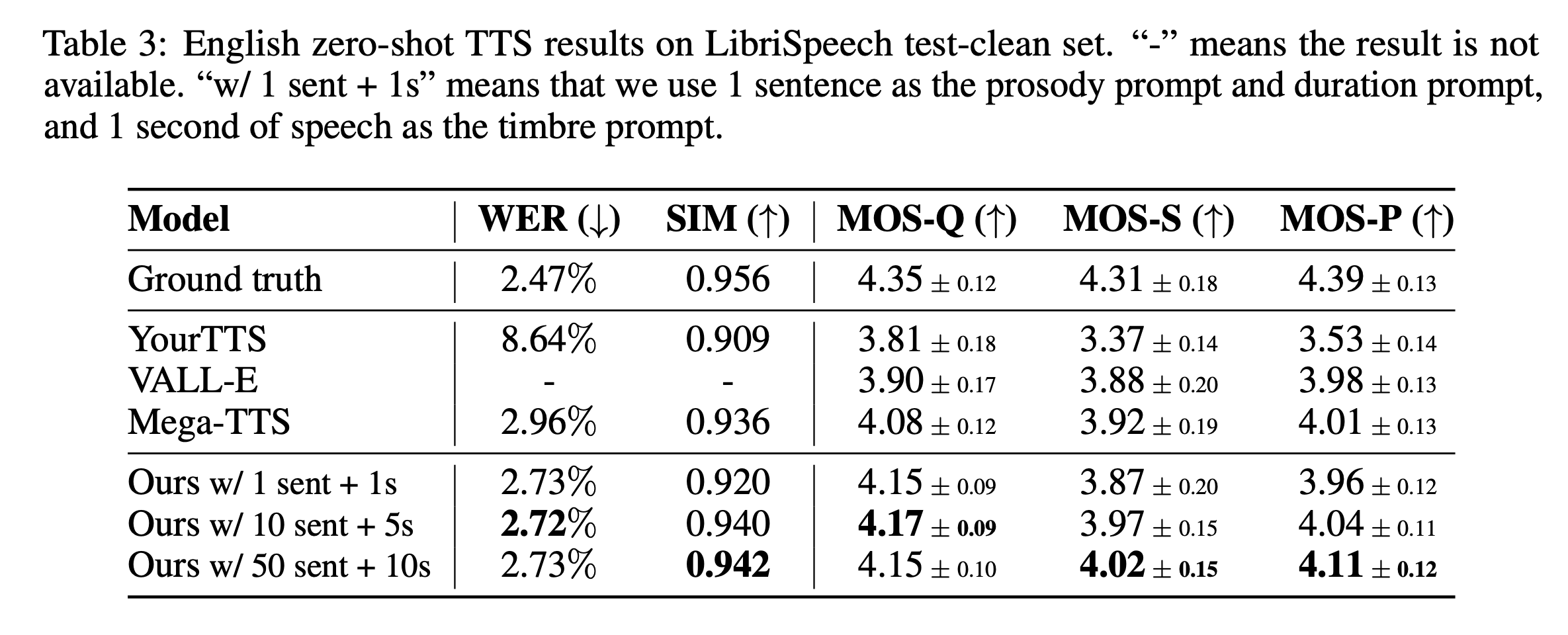
在上表的实验中,Mega-TTS 使用不同的句子数作为 prosody 和 duration 两个模块的参考音频个数,1秒或5秒或10秒的音频作为音色的 prompt。这个三个对比实验,证明了更长的 prompt 能够给音色、合成的音质及韵律都带来持续的提升。
消融实验
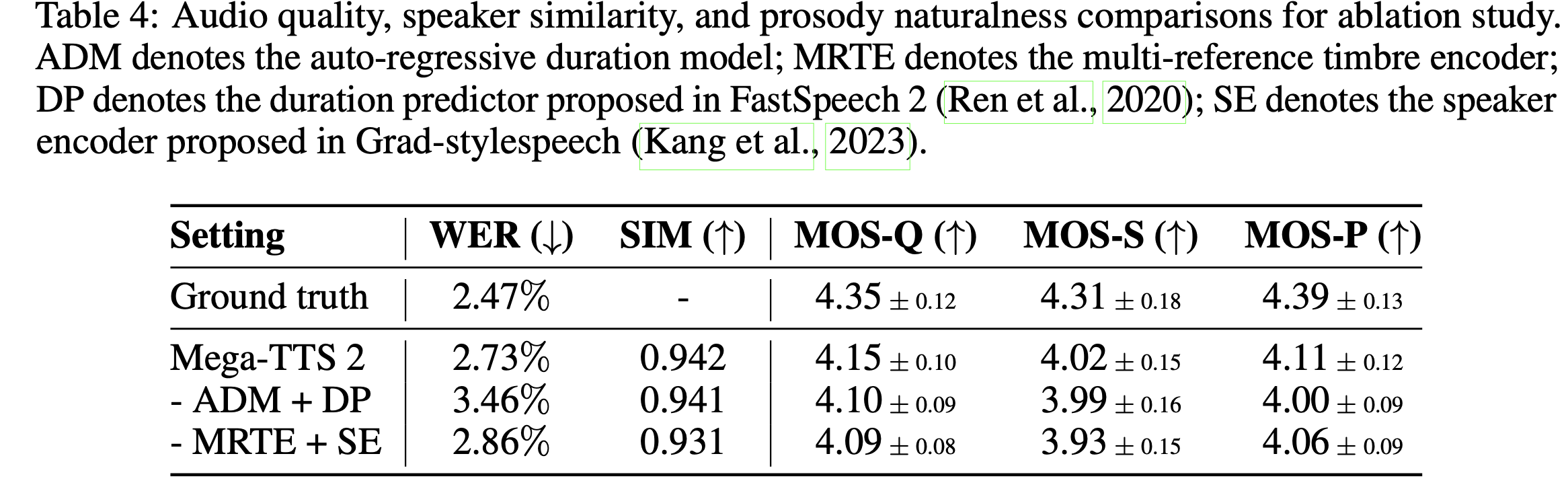
MRTE 对音色相似度有提升、ADM 对合成准确度有提升。
该实验使用的是 50 句作为 prosody/duration 的 prompt,10 秒的音频作为音色的参考音频。
总结
Mega-TTS 2 在 Mega-TTS 1 的基础上,进行了三大扩充:
- 参考音频长度/数量的扩充
- 模型参数量的扩充(P-LLM 可以算是真的大模型了)
- 数据量的扩充,38k 小时的训练数据
同时,将时长预测改为了具备 in-context learning 的自回归结构。都是值得借鉴的。
- 本文标题:语音合成 | Mega-TTS 2:基于任意长度 prompt 的零样本复刻
- 创建时间:2023-09-16
- 本文链接:2023/09/16/2023-09-16_megatts_2/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!