- Mega-TTS Zero-Shot Text-to-Speech at Scale with Intrinsic Inductive Bias
- https://arxiv.org/abs/2306.03509
论文介绍
目前对于零样本 TTS 任务,扩充训练的数据量能够达到更强的音色和风格泛化性。近期涌现的方案主要是:将语音编码为离散化的 codec 表征,再基于自回归语言模型或者 diffusion 模型作为生成模型,但是这类方法只是将语音数据作为一种普通的数据模态,纯粹是基于神经网络硬训一发,忽略了语音数据的一些内在属性,这些内在属性是语音的归纳偏置(或者理解成语音信号的先验规律)。因此从生成的音频的质量和可控性来看,基于 codec 的建模可能是存在一些固有缺陷的。
本论文认为,语音的内在属性对于语音合成任务的建模是很有帮助的:语音可以分解为 内容+音色+韵律+相位 等维度,每个维度的建模都可以使用一些先验信息帮助更好的建模。
小议:相比于近期比较火爆的 VALL-E 等论文,本文实际上还是传统路线的人工网络设计思想,从不同的维度设计不同功能的模块,使得模型具有更强的可解释性。这类模型的效果一般不差,但是 VALL-E 等大模型似乎在数据量足够时,也能具有很的建模效果。从模型的优势来看,论文主要解决了 VALL-E 这类自回归模型的「重复/漏词」等固有问题。
论文方法介绍:
不使用音频 codec,而是仍然使用 FastSpeech2 等模型的梅尔谱特征作为中间特征;从梅尔谱到波形的转换,仍然采用的是 HiFi-GAN 声码器来恢复,用来还原一种相位下的波形输出,这样声学模型部分就不需要对相位进行建模了,降低了声学模型本身的建模难度;
仍然使用全局的向量作为音色信息的表征,因为音色是具有全局不变特征的;
声学模型采用 VQ-GAN 的主体结构,输入 condition 是文本,用于生成目标文本的梅尔特征,但是同时 VQ 可以将韵律表征进行离散化,使用 LM 可以对韵律进行自回归形式的建模。LM 具有很强的局部和长时表征能力;
论文使用的数据量也是 2 万量级的中文+英文语音数据;
论文的应用场景:零样本语音合成、语音编辑以及跨语言的语音合成任务。
论文方法
论文思想
语音的内在属性,可以分为以下四方面:
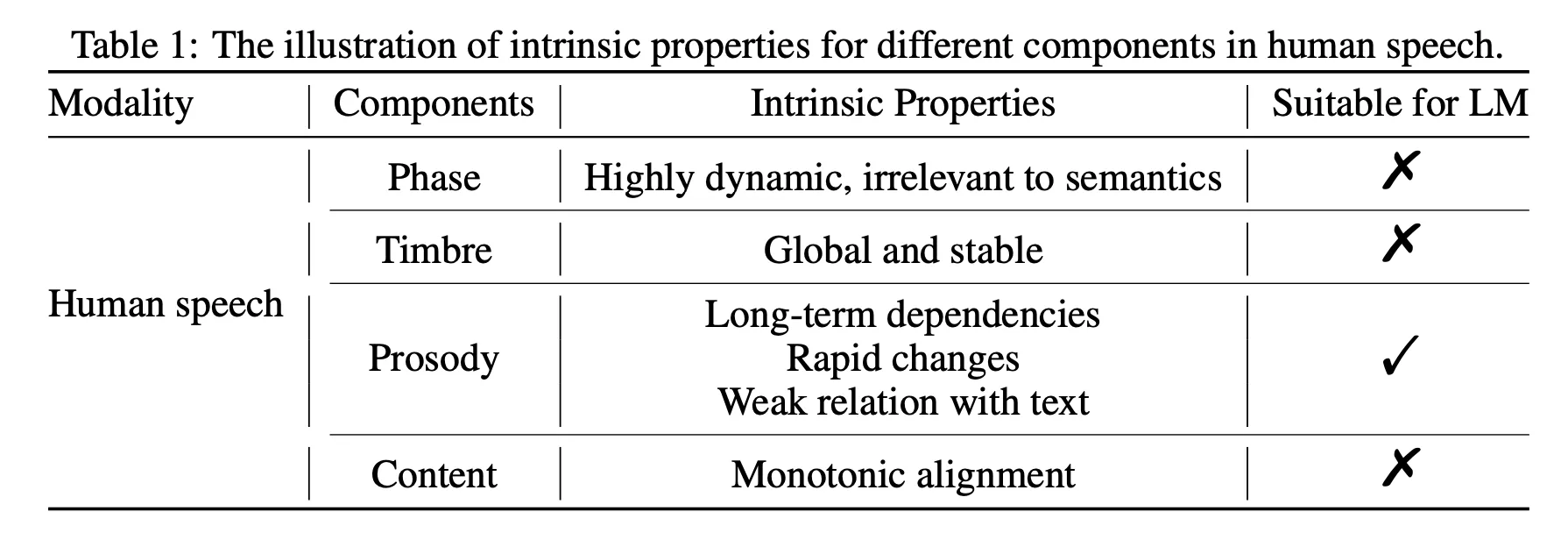
一、语音的相位 phase 信息是高度动态变化、与语义内容无关的,人耳对相位信息的感知不如韵律/音色更加直接(尤其是单声道音频),所以对于合成出来的波形,只要能够给出某一种还不错的相位,就已经能够满足应用需求了,而不需要建模所有可能的相位情况的能力。因此,论文选择梅尔特征作为声学模型的目标,声码器仍然采用的是 GAN,也能够恢复足够的相位信息。
小议:论文此处的意思是,直接使用波形提取出来的 codec 信息,里面是包含了对相对的过度建模的,这部分使用 LM 或者 diffusion 来建模,不会对合成的音质带来明显的提高,反而会提高语音合成任务的难度、进而浪费模型的部分参数。
二、音色在一段音频(句子级)内是稳定的,所以不需要建模随时间变化的成分,也就意味着用一个全局的表征就能够满足建模需求。为了将文本和音色信息解耦,本文抽取音色 embedding 时使用的是与训练目标同属一个说话人的不同语音数据(这个操作确实可以解耦参考音频是目标音频本身所带来的内容耦合问题,但是同属一个人的不同语音,音色差异可能也比较大,这种操作对于 unseen 的 speaker,是否真的能够将音色建模得很像呢?可能还需要实验的一些验证)。
小议:实际上论文此处增加了一个脚注:大部分的音色信息只用一个时间维度 pooling 后的表征,但 prosody encoder 这部分也是可以保留一定的时变的音色信息的。这实际上也是给后续的工作留下了一点接入点,在 Mega-TTS 2 的工作,就已经修改为:时变的音色信息也很重要,需要一个 phone-level 的模块进行提取建模。在 Mega-TTS 2 的论文中会着重介绍。
三、韵律是具有局部和长期的关联性的,而且随着时间变化较快,但同时又和文本信息弱相关(韵律真的与文本之间关联性较小吗?)这种既有局部建模又有长期时序依赖的建模任务,非常适合使用自回归的结构来建模,论文是在 VQ 的基础上,在离散的 latent code 上进行语言模型建模。
小议:在 prosody encoder 韵律建模模块使用 VQ 有两点优势:一是 VQ-GAN 的结构适合吸取噪声数据,个人认为:此处的噪声数据不是指带有底噪的音频,而是指分布规律与平均分布差异相差较大的训练数据(类似数据分布中的野点,这类数据可能是一些噪声/背景音乐/对齐效果不好的数据,本来使用传统的网络是有可能造成建模的问题,但是使用 VQ 之后,encoder 端相当于对这类数据进行了吸收)。第二点,VQ 离散化之后,非常适合 LM 的建模,这比用自回归模型直接对 prosody 输出的 embedding 进行回归式建模更简单和可控。
四、对于内容 content 来说,是与语音信号单调对齐的,但是自回归的模型会造成一些「重复/漏词」的现象,这一点也是 VALL-E 等完全基于 LM 的方案的一个固有缺陷。
小议:对于 TTS,早期的 Tacotron 模型使用的就是自回归结构,同样也有「重复/漏词」的问题,所以后期有了 FastSpeech 系列非自回归模型;但是现在 VALL-E 的 Codec + LM 模型实际上回到了自回归的结构上,所以还是难以规避自回归模型本身的缺陷。同时也可以看到,目前 ChatGPT(自回归结构)的可用率还是很强的。所以目前可能有两类思路:一是如何在语音场景上,达到和 chatgpt 类似的可用率;二是改进建模的方法,比如用 Diffusion 等方式规避到自回归模型的缺陷。本文提出的 VQ-GAN 韵律 LLM 实际上也是一种自回归和非自回归结合的建模方法,后文的实验中可以发现,Mega-TTS 也是解决掉了重复/漏词的现象。
模型主体结构
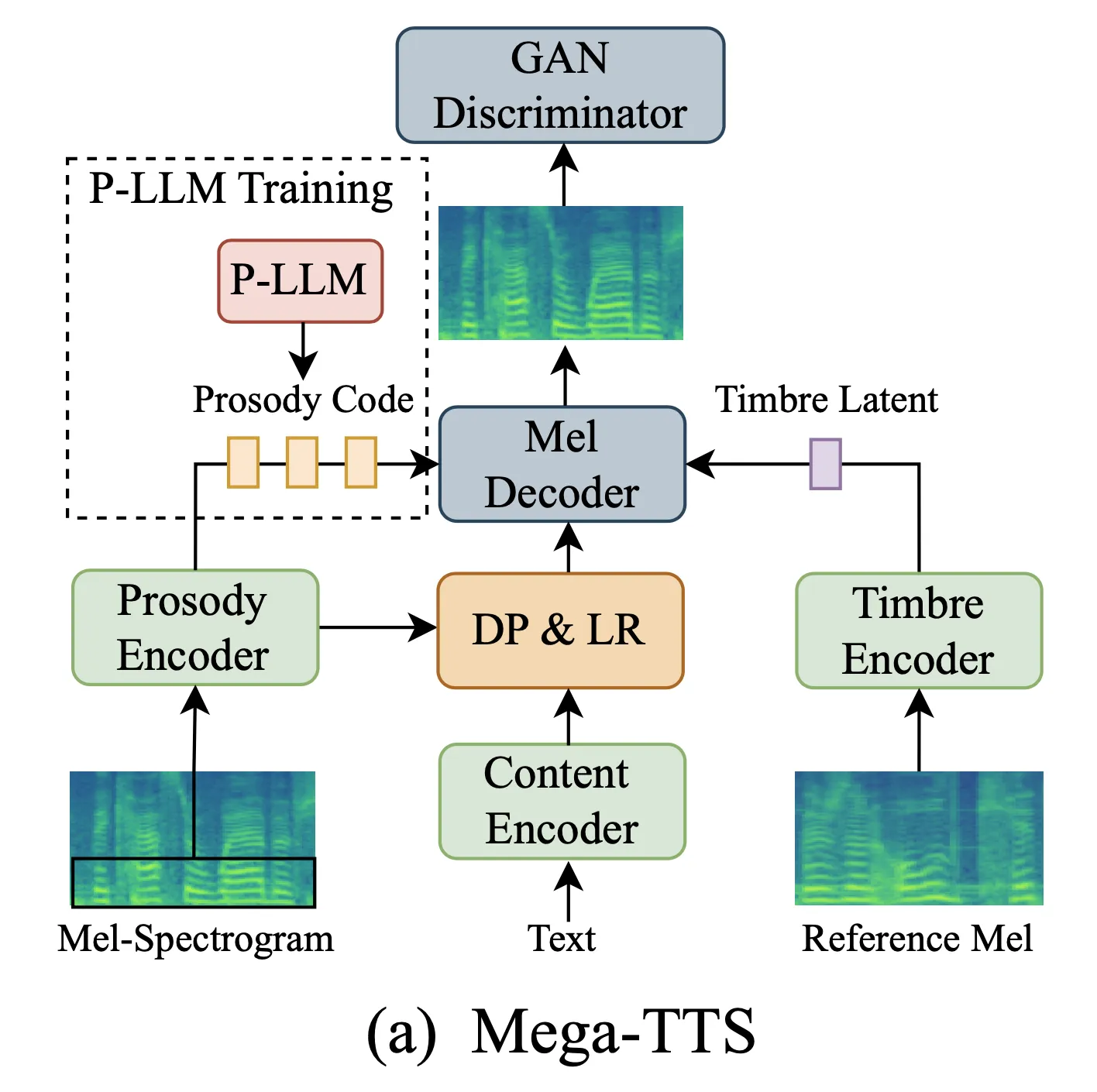
模型整体包含三个 Encoder,分别对应语音的三大特性:
Content Encoder 就是普通的 FastSpeech 系列中的 Phoneme-Encoder,结构是普通的 Transformer-Encoder,输入是音素序列,输出是音素级别的 embedding;
Timbre Encoder 是一个 global embedding 的提取模块,输入是参考音频(训练阶段使用和目标音频不一样但是同属一个说话人的音频;推理阶段使用 prompt 音频即可),输出是一个 speaker embedding。具体网络结构是卷积+时间维度的 average-pooling。
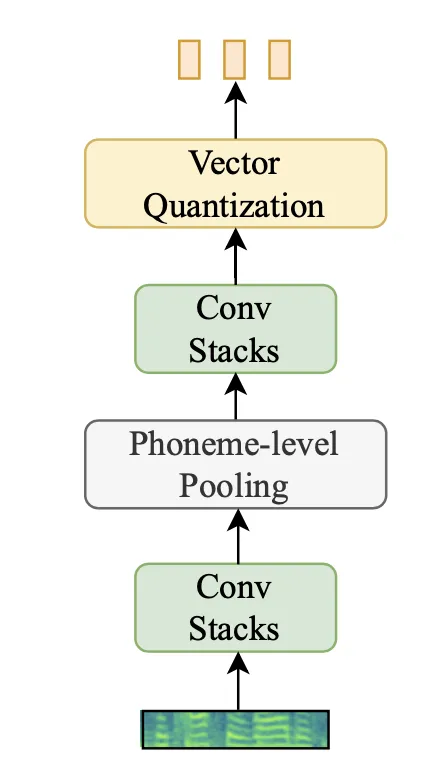
Prosody Encoder 输入是目标音频的低频梅尔特征(论文认为韵律只需要低频的梅尔部分【前20维梅尔】就可以抽取出来,不需要全部的特征信息,这样一定程度上也能解耦掉 Prosody Encoder 这部分建模的东西),在输出的 embedding 基础上进行 VQ,增加 VQ-GAN 的 loss 来指导声学模型的训练。论文对 VQ 部分的参数进行了细致的实验选择。
Prosody Encoder 的结构是两个卷积 block+ phone-level pooling,其中 phoneme-level 的 pooling 在两层卷积之间,第一个卷积模块是为了学习梅尔局部信息、并通过 pooling 得到 phone-level 的表征,第二个卷积模块则是建模 phone-level 信息的局部相关性。VQ 模块是将 phone-level 的表征进行量化,得到量化后的韵律编码 latent code。
其他的 duration predictor 和 length regulator 的配置和普通的 FastSpeech2 完全一样,duration predictor 使用的仍然是非自回归结构。
此外,对于整个模型来说,除了普通的 TTS 训练相关的loss,还增加了 GAN 的对抗损失函数,增加了 HiFi-Singer 中的 multi-length discriminator 判别器,进行类似 GANSpeech 的训练(HiFi-GAN 是对波形进行判别,本文的判别器的任务是判别梅尔是否是真实的梅尔特征)。
模型训练
模型训练采用两阶段训练方法。
第一阶段:训练 VQ-GAN。不训练韵律 LLM(P-LLM)这两部分,而是只训练 VQ + GAN,训练目标是从文本+参考音频的信息中恢复出梅尔特征。
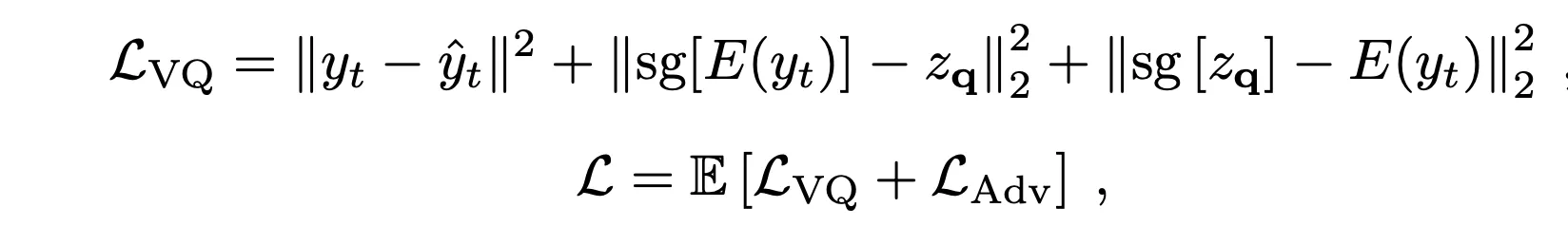
除了 GAN 训练的对抗 loss(本文使用的是 LS-GAN),还有 VQ 部分的损失函数。其中,第一项是梅尔重建的损失函数,使用的是 L2,后两项是在 prosody encoder 的输出上,进行 codebook 的训练。
对于 Mega-TTS 来说,第一阶段是否联合训练 duration predictor 似乎不太重要,因为非自回归结构不会用到 prompt 信息;但是对于 Mega-TTS 2 论文来说,第一阶段 Length Regulator 是根据 MFA 对齐抽取的 Ground-Truth 对齐结果进行扩帧的,不需要 duration 模块的预测 loss,只在第二阶段才训练自回归的 duration predictor。
第二阶段:训练 P-LLM。第一阶段已经将 VQ-GAN 训练好了,对于输入的语音,都可以从 prosody-encoder + vq 模块抽取出对应的 latent code,用来训练 LLM,所以第二阶段固定声学模型参数不变,只需要训练新增的 P-LLM 那部分的参数即可。
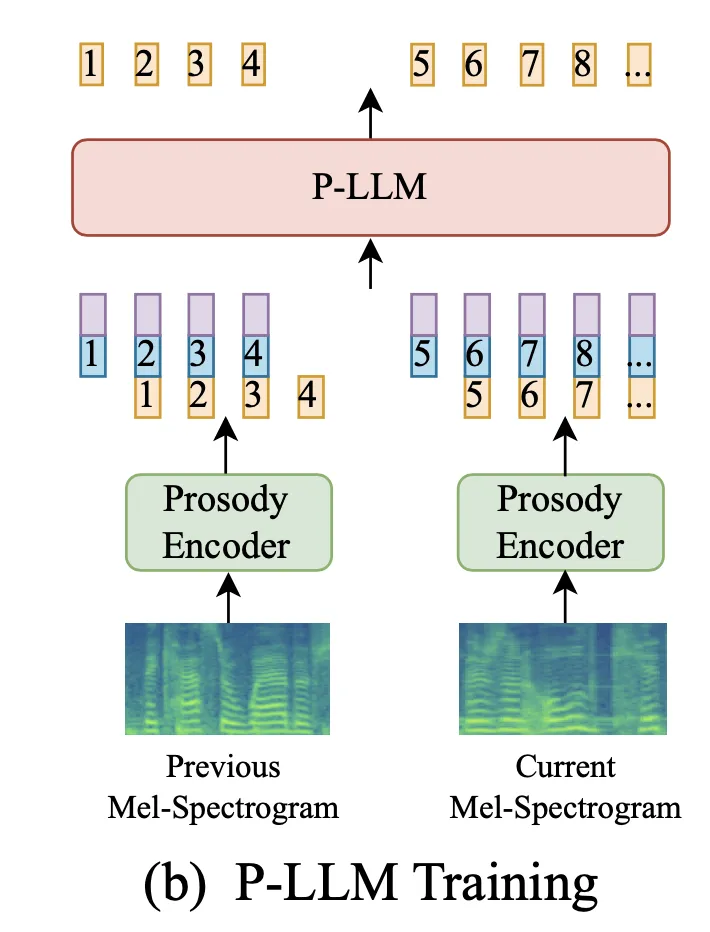
训练阶段就只需要准备好:content encoder 输出的蓝色 content latent,timbre encoder 输出的紫色timbre latent,然后 LLM 的输入和输出都是 VQ 提取出来的 prosody code,按照 decoder-only transformer 的结构,采用 teacher-forcing 的方式训练 LLM 即可。
模型推理(零样本 TTS)
在推理阶段,是需要 prompt 作为参考的。prompt 需要同时输入文本和音频,分别提取出来 prompt 音频对应的 content timbre 和 prosody:
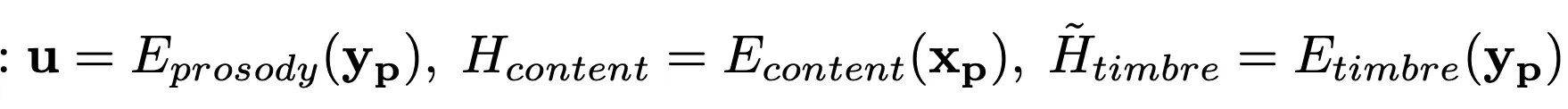
对于待合成的音频,抽取好的
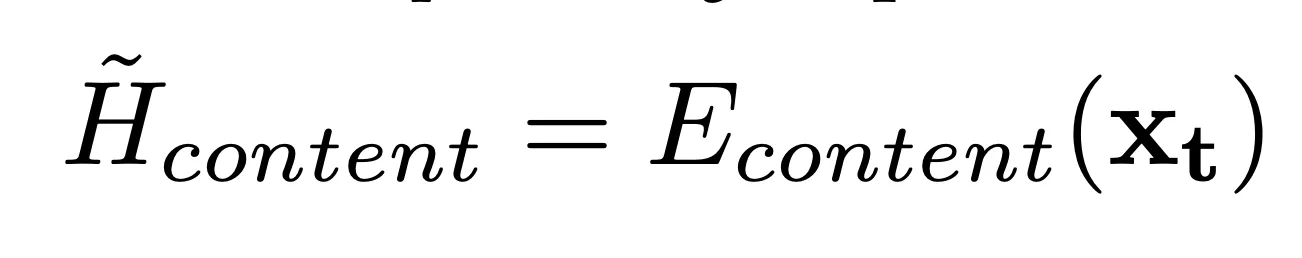
那么剩下的 prosody,则是需要从 prompt 的 content + timbre + prosody code 作为前缀,使用 P-LLM 模型,采用自回归的方式预测出来: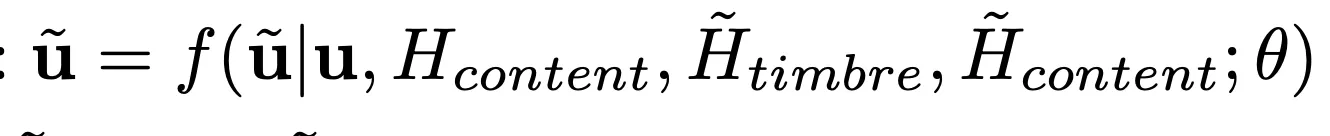
细节的自回归解码生成 prosody latent code 的数学表达式: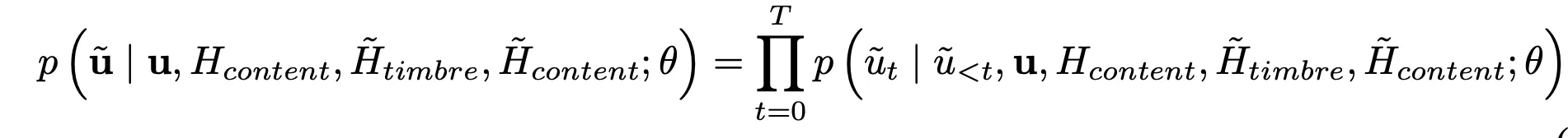
对于待合成的音频,当 prosody, content 和 timbre 全部 ready 之后,即可使用 mel-decoder 自回归的方式生成得到目标的梅尔特征。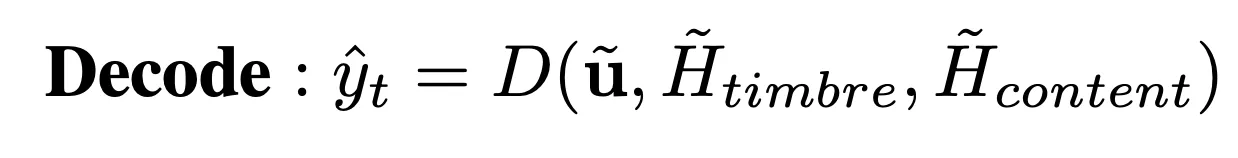
注意一:对于 P-LLM 这种自回归模型的解码,可以使用 top-k 随机采样的方法,生成更多样的语音。
注意二:对于 cross-lingual 任务的零样本 TTS,比如输入的 prompt 是英文,待合成的是中文,那么:
- 音色 timbre
来自英文 prompt 来自待合成的中文文本 和 来自英文 prompt
模型推理(语音编辑)
对于语音编辑任务:左右两边都是真实的音频,只有中间区域是待编辑的语音。
本文将左边的真实音频作为 prompt,使用 top-k 随机采样策略生成 N 条候选路径;然后 N 条候选路径分别作为 prompt,计算右侧真实音频对应的概率。对于每个候选路径,将各步解码的对数概率值相加(实际上是概率之积)。最后从所有 N 条候选路径中,选择对数概率和最大的那条路径,作为 prosody code 序列,与 timbre + content 一起生成最终的梅尔特征。
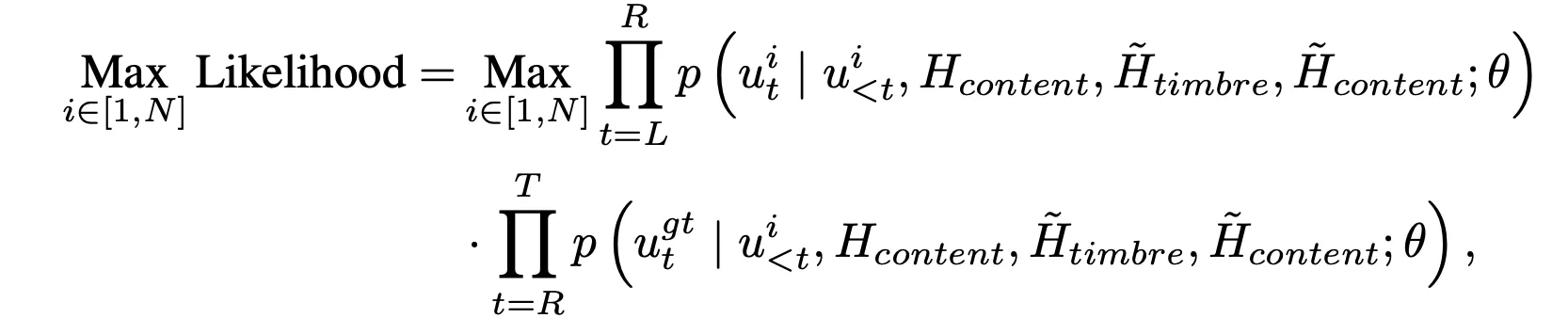
注意:个人理解论文中提到的 probability matrix 的计算,是因为在计算右侧的对数概率和时,因为前面的候选路径的不同,导致右侧每一步的对数概率都是变化的(需要模拟自回归的方式来解码),右侧算概率时,当前时刻使用 prosody code 不是 GT 的,而是上一步预测的最大 code(并不一定是 GT 的 prosody code),这一点和最开始读这篇论文的时候存在一点偏差。
实验细节
训练数据:GigaSpeech 1 万小时 + WenetSpeech 1 万小时。
使用 pyannote 进行句子级别的说话人聚类。
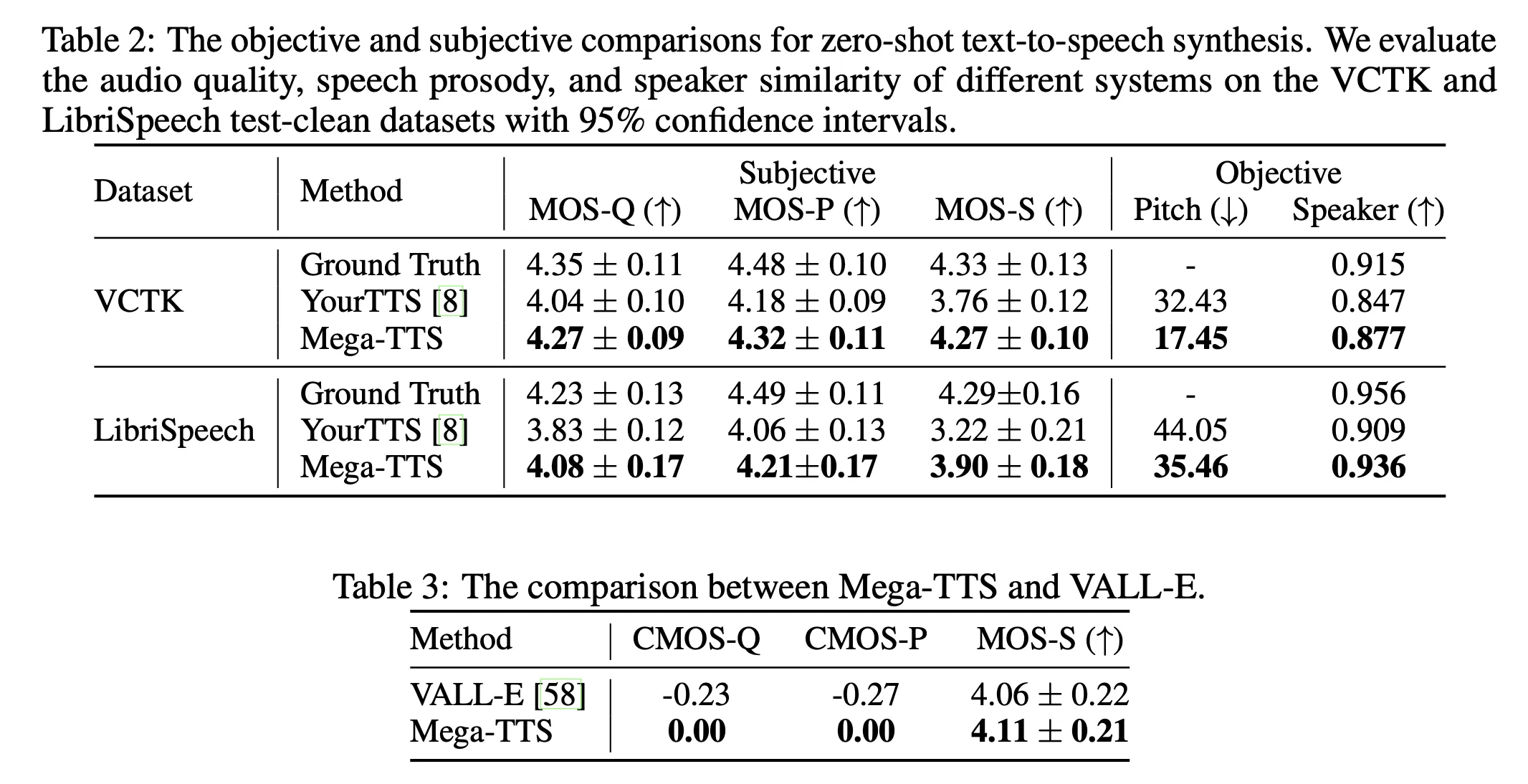
评测数据:VCTK + LibriSpeech,评测的都是 unseen speaerk。
模型参数配置

实验结果
零样本 TTS
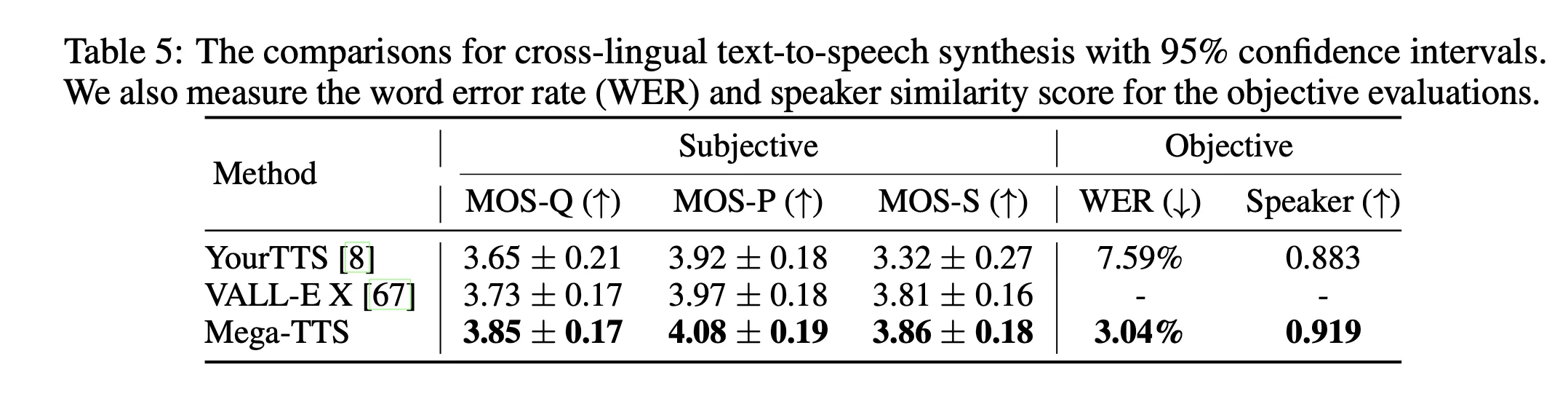
语音编辑任务
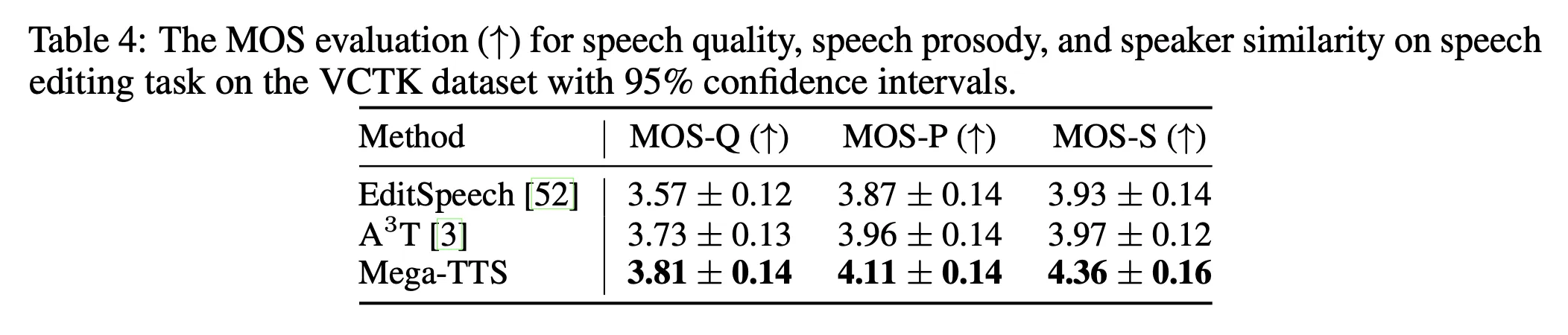
跨语言 TTS
解决了自回归模型的重复/漏词问题

参数选择

Prosody Encoder 中 VQ 的结构,此处的 VQ Embedding Size 的意思应该是 codebook size,也就是 2048 个 VQ 之后的 token,embedding channel 代表 VQ 后每个向量的维度为 256 维。下面是做了参数选择的对比实验:
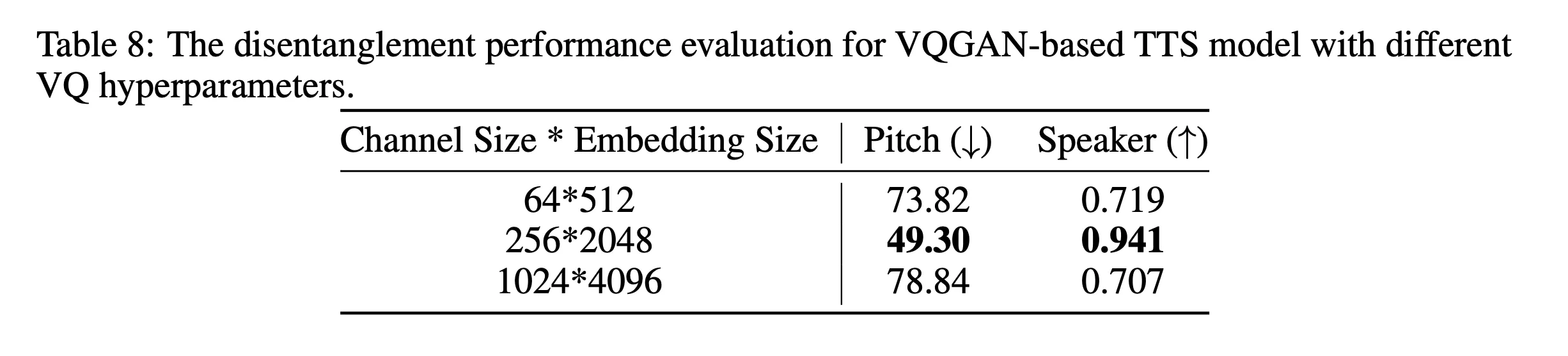
注意:P-LLM 中,实际应该还加入了类似 和 开始符和结束符两个 token(2048+2=2050)

- 本文标题:语音合成 | Mega-TTS:引入先验偏置的 TTS 方案
- 创建时间:2023-08-08
- 本文链接:2023/2023-09-08_megatts/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!