- 论文题目:Kimi-Audio Technical Report
- 论文链接:https://arxiv.org/pdf/2504.18425
- 开源链接:https://github.com/MoonshotAI/Kimi-Audio
- base 模型:https://huggingface.co/moonshotai/Kimi-Audio-7B
- Instruct 模型:https://huggingface.co/moonshotai/Kimi-Audio-7B-Instruct
- 评估工具:https://github.com/MoonshotAI/Kimi-Audio-Evalkit
- 作者单位:Kimi Team(月之暗面)
- 发表日期:2025 年 4 月 25 日
- 关键工作:开源首个通用的音频基座模型,统一音频理解、生成、端到端对话的任务,基于 1300 万小时数据训练,提供完整工具与部署方案
语音领域现有模型长期面临 “单任务专攻” 的局限,大多只聚焦理解或生成单一能力。月之暗面提出的 Kimi-Audio,核心贡献在于构建了 “感知-处理-生成” 的统一架构,通过提出连续与离散的混合表征、LLM + 大规模训练数据以及完备的分阶段训练策略,能一站式搞定音频理解、生成和对话任务,并实现多任务的 SOTA 性能。
一、引言:通用音频基座模型
1. 背景:现有方案短板
音频是人类交互的关键形式(含语音、音乐、环境音等),可支撑识别、理解、对话等复杂任务,但当前方案存在三大明显不足:
- 任务割裂:传统模型多针对单一任务优化(如语音理解、生成、对话分开独立建模),缺乏统一框架处理“理解-生成-对话”全链路需求
- 数据与训练不足:部分模型仅依赖下游任务微调,忽视大规模音频预训练,难以捕捉通用音频规律,且数据质量和多样性无法保障
- 开源生态缺失:多数高性能模型闭源,或未提供完整评估工具链,导致社区难以复现结果、开展对比研究。
2. Kimi-Audio 核心设计
为解决上述痛点,实现统一音频模型目标,Kimi-Audio 从架构、数据、训练三大维度推进核心设计,具体工作如下:
- 12.5Hz 音频 Tokenizer:将音频压缩为离散语义 token,同时保留连续声学特征作为输入,平衡模型效率与音频感知能力
- LLM-based 核心架构:以大语言模型(LLM)为核心,输入为“连续声学特征+离散token”,输出为“离散token+文本”双模态,兼顾音频理解与生成能力
- 流式 de-tokenizer:基于流匹配(flow matching)技术实现分块流式解码,解决音频实时生成的核心问题
- 大规模高质量数据支撑:采用 1300 万小时多模态音频(含语音、环境音、音乐)进行预训练,同时搭建高质量微调数据集流水线
- 精细化训练策略:从预训练文本 LLM 初始化,预训练阶段设计“音频+文本”多类任务,再通过微调适配各类具体音频任务
- 全面模型评测:在语音识别、音频理解、语音对话等多个权威基准测试中,均取得当前最优(SOTA)结果
Kimi-Audio 的出发点:音频本质是“序列数据”,且语音与文本存在强对应关系,为“统一音频模型”提供了可行性。
Kimi-Audio 的目标:复刻 NLP 领域从“单任务模型”到“通用 LLM”的进化路径,让音频模型实现“一个模型搞定所有音频任务”,最终打造开源、通用、强预训练的音频基础模型,实现“理解+生成+对话”全链路统一。
二、架构:Kimi-Audio 结构设计
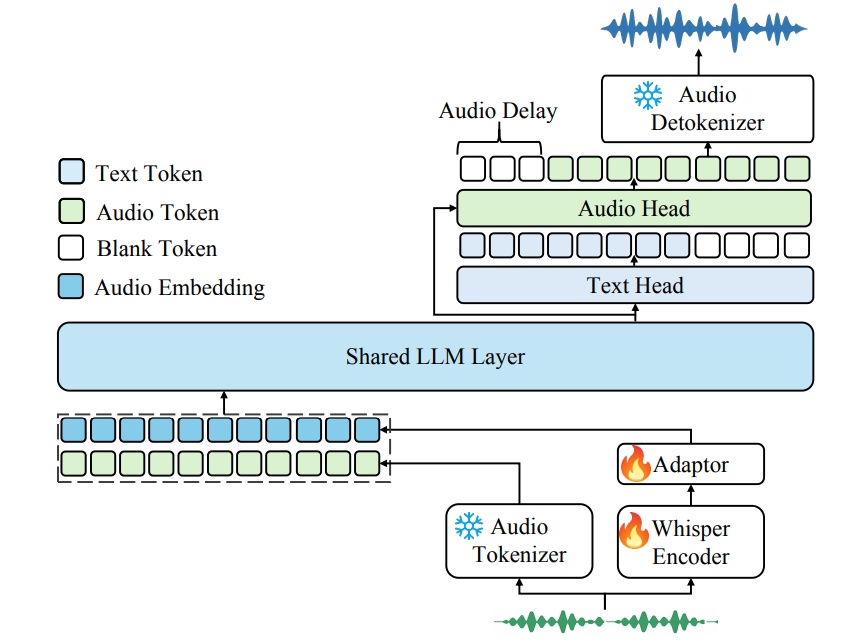
Kimi-Audio 的架构是 “Tokenizer(输入处理)+ Audio LLM(核心架构)+ Detokenizer(输出生成)” 的三段式结构,最终实现 “输入音频→模型处理→输出音频 / 文本” 的端到端能力。
| 模块名称 | 功能 | 核心配置与设计细节 |
|---|---|---|
| 音频编码器 (Audio Tokenizer) |
音频感知与表征 | 采用混合表征策略 → 混合表征平衡语义与声学信息 1. 离散语义 token:基于 GLM-4-Voice 向量量化,12.5Hz 帧率,捕捉核心的语义信息 2. 连续声学向量:Whisper Encoder 输出(50Hz)经 Adapter 下采样至 12.5Hz,保留声学细节 3. 融合方式:将两类表征相加作为 Audio LLM 的输入,能够兼顾语义与声学信息 |
| 音频大语言模型 (Audio LLM) |
核心处理与生成能力 | 基于 Qwen2.5 7B 预训练文本 LLM 初始化: 1. 架构设计:底层共享 Transformer 层处理多模态输入,上层分成两支并行头(文本输出头 + 音频输出头) - 文本输出头:负责语音识别、音频问答等输出为文本模态的任务 - 音频输出头:生成离散语义 token,传给 Detokenizer 生成音频,负责语音合成、对话等输出为音频模态的任务; 2. 初始化策略:共享层与文本输出头复用文本 LLM 的权重,保留语言能力(智力),音频输出头随机初始化来学习音频生成能力; 3. 输出形式:可生成文本 token 或离散语音 token,适配不同的任务需求 |
| 音频解码器 (Audio Detokenizer) |
音频生成与延迟优化 | 基于流匹配(Flow Matching)与 BigVGAN 声码器: 1. 核心流程:先将 12.5Hz 语义令牌上采样至 50Hz 梅尔频谱,再通过声码器转换为波形 2. 低延迟设计:分块自回归流式框架 + Look-ahead 机制,拆分音频为 1 秒 chunks 解码,每个 chunk 拼接后续 4 个 token 来解决边界不连贯的问题 - 举例:解码第 i 块时,先拿第 i+1 块的前 4 个 token(提前看一点未来信息)拼到第 i 块后面,一起解码后,只保留第 i 块的结果(这样边界衔接更自然,且只增加第一块的延迟) |
三、数据:1300 万小时预训练 + 30 万小时微调
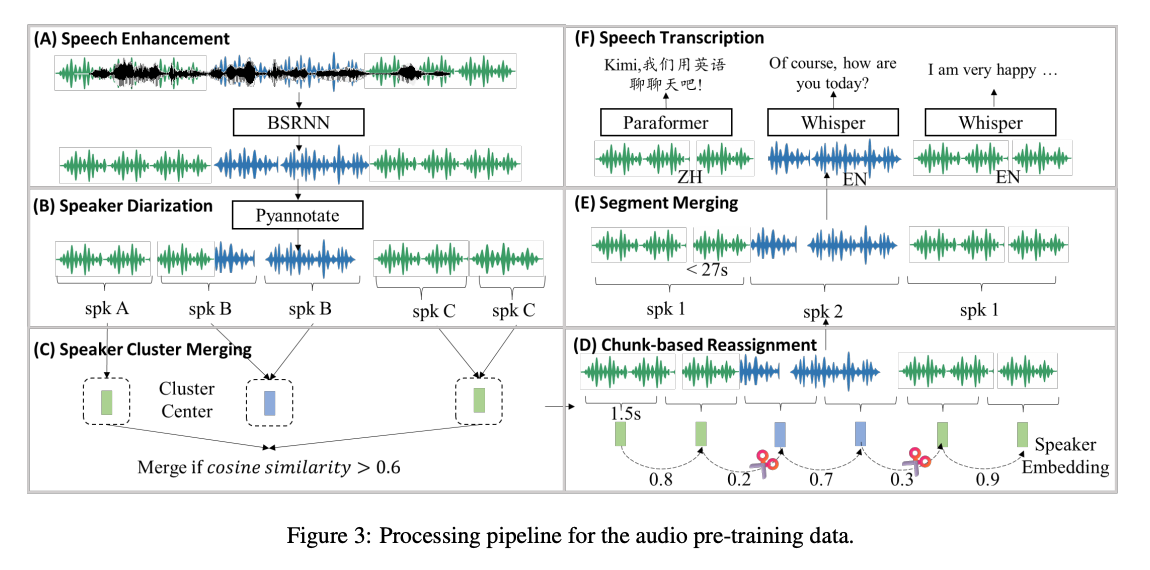
数据是模型的 “石油”,Kimi-Audio 在数据上进行:大规模预训练数据整理和多样化微调数据构建,尽量用开源数据,避免依赖付费资源。
1. 预训练:1300 万小时多模态音频
预训练数据分为三类:文本-only(纯文本)、音频-only(纯音频)、音频-文本 pair 数据。
- 文本-only: kimi-k1.5 的训练数据
- 音频-only: 1300 万小时的纯音频数据(覆盖有声书、播客、访谈等场景,包含丰富的声学事件、音乐、环境声音、人声以及多语言信息)
- 音频-文本 pair 数据:从「音频-only」的数据中清洗 & 处理得到
1.1 音频-文本 pair 数据的清洗流程
- 核心问题:原始的纯音频数据有很多问题(比如没字幕、有噪音、 speaker 标注混乱),所以搭建了一套自动化处理 pipeline
- 语音增强:用 BSRNN 模型去除背景噪音和混响,但为了不丢环境音(对音频理解重要),最终随机选 50% 原始音频、50% 增强后音频
- 基于说话人分割(Diarization):用 PyAnnote 工具做说话人分割,但做了三点优化:
o speaker 聚类合并:解决 “同一人被标多个 label” 的问题(余弦相似度 > 0.6 就合并);
o 分块重分配:把长片段切成 1.5 秒的小块,相似度 < 0.5 就归到不同 speaker,将每个块重新分配到相似度最高的说话人簇;
o 片段合并:把过短(<1 秒)的片段合并,最终保留 27 秒以内的片段 - 转录(Transcription):
o 语种识别:用 Whisper-large-v3 识别语言(只保留中英文)
o 英文直接用 Whisper-Large v3 的文本和标点
o 中文用 Paraformer-Zh 识别文本,再按字符的静音间隔加标点(0.5-1 秒加逗号,>1 秒加句号) - 处理效率:用 30 台云服务器(每台 128 vCore、1TB 内存、8 张 L20 GPU),每天能处理 20 万小时音频,保证数据处理效率
2. SFT:三大任务共 30 万小时
预训练后要做监督微调 SFT,让模型适配具体任务,SFT 数据分以下三类:
| SFT 数据类型 | 核心用途 | 数据构成 |
|---|---|---|
| 音频理解 | 强化识别、分类、问答能力 | - 6 类开源数据集(语音识别ASR、音频问答 AQA、音频描述 AAC、情感识别 SER、声音事件分类 SEC、音频场景分类 ASC) - 5.5 万小时内部 ASR 数据 + 5200 小时音频描述 AAC & 音频问答 AQA 数据 |
| 语音对话 | 支撑多轮语音交互的能力 | TTS & VC 构造的数据:基于 Kimi-TTS(零样本 TTS,支持 12.5 万种音色)与 Kimi-VC(语音转换,保留风格情绪)构建,含 20+ 风格/情绪的多轮对话 - 【用户 Query 音频】先指导文本 LLM 编写 Query 文本,然后通过 Kimi-TTS 转换为语音 o prompt 音频:从包含超过 12.5 万种音色的大音色集中随机选择的 o Kimi-TTS:根据 prompt 音频和输入文本生成语音 token,然后基于流匹配生成高质量的语音波形。使用大约 1 M 小时的数据上训练 Kimi-TTS,并应用强化学习进一步提高生成语音的鲁棒性和质量 - 【助手回复音频】选择一位语音配音演员,作为 Kimi-Audio 目标音色 o 在专业录音棚中仔细录制该演员的数据集,预先定义了超过 20 种风格和情感进行录制 -每种情感进一步分为 5 个等级,以表示不同的情感强度 -对于每种风格和情感等级,需要录制一段音频作为参考,保证录音时的一致性 o 语音演员很难以任何风格、情绪和口音录制语音,所以开发了一个 Kimi-VC 模型 -目标:将不同说话人/音色的语音转换为目标音色,同时保留风格、情绪和口音 -Kimi-VC 基于 Seed-VC 框架,在训练期间引入 source 音色扰动 -为了保证 Kimi-VC 高质量,使用目标音色的语音数据对模型进行微调 |
| 音频到文本对话 | 适配口语化对话场景 | 开源文本对话数据(如 Infinity-Instruct、OpenHermes)转换而来 - 将 Query 从文本转换为音频 - 预处理:过滤复杂内容、口语化改写、复杂指令的单轮数据转换为简洁指令的多轮数据 |
- 总结:数据构建的优势:不依赖付费数据,通过自动化工具链实现高质量数据规模化生产,兼顾多样性与场景覆盖度。
四、模型的多阶段训练
Kimi-Audio 的训练分两个核心阶段,每个阶段又包含多个子任务的设计。
1. 预训练:音频和文本模态对齐
1.1 核心目标
- 学习音频与文本领域知识,实现两种模态的对齐,为音频理解、音频到文本聊天、语音对话等复杂任务奠定基础。
1.2 数据说明
- 原始音频,经数据预处理的 pipeline 之后,分割为多个片段 {S₁, S₂, …, Sₙ},每个片段含音频 aᵢ 及对应转录的文本 tᵢ
- 对每个音频片段提取两类特征:连续声学向量 aᶜᵢ、离散语义 token aᵈᵢ
- 特别说明:aᶜᵢ+aᵈᵢ 表征连续声学向量和离散语音 token embedding token 之后的结果,用「不带上标」的 aᵢ 来表示
- 构建训练序列 {aᶜ₁/aᵈ₁/t₁, …, aᶜₙ/aᵈₙ/tₙ},通过补空白 token 使音频与文本序列长度一致,训练时可灵活选用序列组合(如仅 aᵈᵢ、仅 tᵢ、aᶜᵢ+aᵈᵢ 等)
1.3 三类预训练任务(7 个子任务)
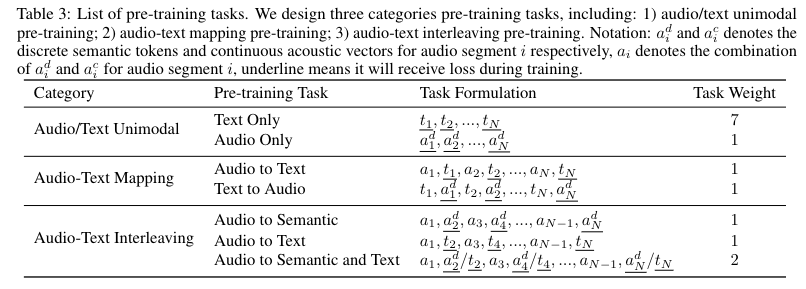
类别一:单模态预训练(独立学习单领域知识)
- 子任务 1 - 文本单模态:基于高质量文本数据,仅对文本 token 做 next-token prediction
- 子任务 2 - 语义 token 单模态:对每个片段的离散语义 token 序列 aᵈᵢ 做 next-token prediction
类别二:语音&文本映射预训练(建立模态间的映射关系)
- 子任务 3 - 「音频完整表征」到文本(ASR):训练序列 {a₁,t₁,…,aₙ,tₙ},仅对文本 token 计算损失
- 子任务 4 - 文本到语义 token(TTS):训练序列 {t₁,aᵈ₁,…,tₙ,aᵈₙ},仅对音频语义 token 计算损失
类别三:语音文本的 interleave 预训练(缩小模态之间的 gap)
- 子任务 5 -「音频完整表征」和「语义 token」interleave:序列 {a₁,aᵈ₂,…,aₙ₋₁,aᵈₙ},仅对 aᵈᵢ 计算损失,代表端到端的语音生成
- 子任务 6 -「音频完整表征」和文本 interleave:序列 {a₁,t₂,…,aₙ₋₁,tₙ},仅对文本 token tᵢ 计算损失,代表语音输入&文本输出的 QA 任务
- 子任务 7 -「音频完整表征」和「语义 token + 文本」interleave:序列 {a₁,aᵈ₂/t₂,…,aₙ₋₁,aᵈₙ/tₙ}
-【说明】该任务才是最贴合 Kimi-Audio 的预训练任务
-【难点问题】前若干个语义 token 的预测任务难度较高,因为模型需要同时预测下一个文本 token 及其对应的语义 token
-【解决方案】在语义 token 序列前添加 6 个特殊空白 token 方式(此处的 6 是根据前期实验,在生成质量与延迟之间权衡后确定的最优值)
-相当于在语义 token 的预测上,相比于文本 token 增加了 6 个 token 的 delay(delay-pattern 的策略)
1.4 预训练关键策略
| 配置维度 | 具体内容 |
|---|---|
| 模型初始化 | - 参数初始化:基于预训练 Qwen2.5 7B 模型初始化 - 词汇表扩展:新增语义 token + special token - 连续语音表征提取模块:基于 Whisper large-v3 初始化,用于捕捉细粒度声学特征 |
| 预训练任务权重 | 7 类预训练任务权重配比为 1:7:1:1:1:1:2(对应单模态、语音文本映射、Interleave 三类任务下的 7 个子任务) |
| 训练数据与轮次 | - 数据规模:585B 语音 token + 585B 文本 token - 训练轮次:1 个 epoch |
| 优化器与学习率策略 | 优化器:AdamW;学习率调度:前 1% 的 token 用于热身,之后从 2e-5 余弦衰减到 2e-6 |
| 连续语音表征模块训练 | - 冻结阶段:预训练初期(约 20% token 训练量),冻结模块参数,避免破坏已学能力 - 联合微调阶段:冻结期结束后解冻,与模型其他部分联合微调,适配训练数据与目标任务 |
2. 监督微调(SFT)
2.1 核心目标
- 在大规模预训练的基础上,让模型具备指令跟随能力,适配音频理解、生成、对话等多样化下游任务。
- 微调数据规模:构建约 30 万小时的多任务标注数据,支撑全链路能力优化。
2.2 数据设计
- 设计一:下游任务过于丰富,用自然语言指令替代传统的 task 标记 → 提升任务适配的灵活性
- 设计二:Instruct 指令包含文本&音频两种模式,音频指令由 Kimi-TTS 基于文本指令生成(随机音色)→ 增强模型对音频指令的理解能力
- 设计三:针对 ASR 任务生成 200 条指令,其他任务生成 30 条指令(指令由 LLM 生成),训练时为每个样本随机选择 1 条
o 目的:避免模型过拟合单一指令表述,提升指令跟随的泛化性
2.3 LLM 训练策略
- 优化器:AdamW;学习率调度:前 10% 的 token 用于热身,之后从 1e-5 余弦衰减到 1e-6
o 不同数据源,训练 2-4 个 epoch
2.4 Detokenizer 训练
- 目标:将模型生成的离散 token 转换为高保真音频波形,采用三阶段递进式训练策略,兼顾多样性、流式生成能力与音质
| 训练阶段 | 核心做法 | 目标 |
|---|---|---|
| 阶段 1:通用音频预训练 | 采用 100 万小时预训练音频数据,同时预训练流匹配模型和声码器 | 学习多样化的音色、韵律和音质特征,夯实基础生成能力 |
| 阶段 2:动态分块微调 | 在相同预训练数据上,采用分块训练策略,块大小动态设置为 0.5~3 秒 | 适配流式生成场景,降低实时解码延迟 |
| 阶段 3:单说话人高质量微调 | 使用 Kimi-Audio 目标说话人的高质量单说话人录音数据微调 | 提升生成音频的清晰度与一致性,优化主观听感 |
五、评估方案及测评结果
1. Kimi-Audio-Evalkit 工具
评估工具:https://github.com/MoonshotAI/Kimi-Audio-Evalkit
- 指标标准化:实现统一的 WER(词错误率)计算,用 GPT-4o-mini 做 “智能裁判”(比如音频问答任务,不只用字符串匹配,还看语义正确性)
- 推理配置统一:提供标准化的推理参数(温度、指令模板),避免 “调参出 SOTA”
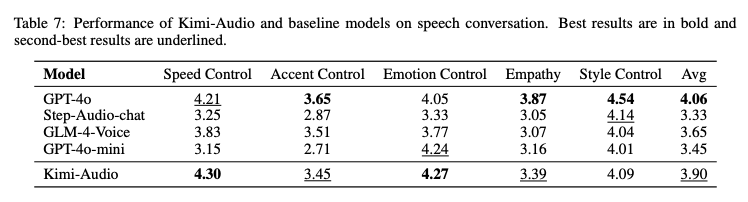
- 生成质量评估:专门做了语音对话基准,从 “情感 / 语速 / 口音控制”“共情能力”“风格多样性(讲故事、绕口令)” 三个维度评估
- 支持 Kimi-Audio 和其他主流音频模型(Qwen2-Audio、Baichuan-Audio 等)的对比
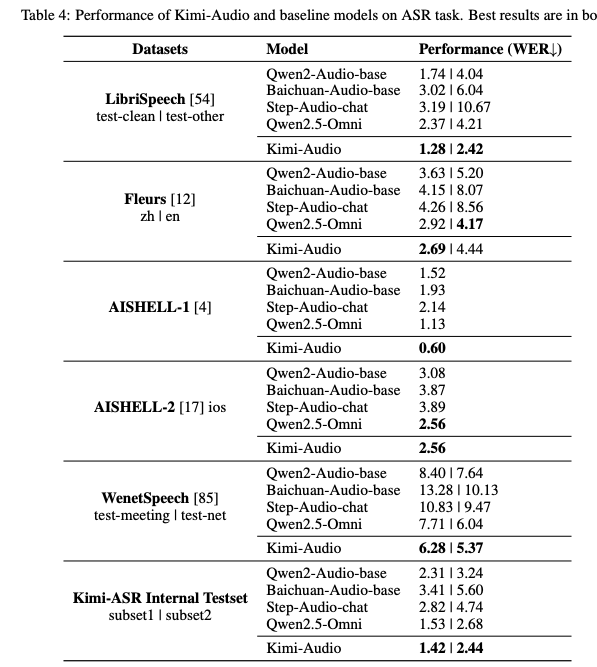
2. Kimi-Audio 评估结论
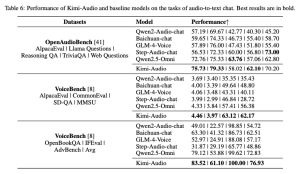
- 四类任务上全都超越 Qwen2-Audio、Baichuan-Audio、Qwen2.5-Omni 等基线
o 语音识别、音频理解分类、音频到文本对话、端到端语音对话
| 语音识别 ASR | 音频理解 Audio Understanding |
|---|---|
 |
 |
| 音频到文本 Audio-to-Text Chat | 语音对话 Speech Conversation (人工评测) |
 |
 |
六、总结与未来方向
Kimi-Audio 的核心价值是开源、通用、强性能—— 它是首个能同时搞定 “理解 + 生成 + 对话” 的开源音频基础模型,1300 万小时预训练数据、混合架构设计、模块化部署,让它在多个任务上达到 SOTA,且对社区开放代码和工具,能推动音频领域的发展。
未来还有三个问题:
- 从 “音频转录” 到 “音频描述”:现在预训练只用 ASR 转录文本(只包含 “说什么”),未来要加 “音频描述”(比如 “一个男人在嘈杂的咖啡馆里开心地说话”),让模型理解更多声学细节;
- 更好的音频表示:现在的离散 token 偏语义、连续特征偏声学,未来要融合两者,同时捕捉 “语义 + 声学 + 情感 + 场景” 信息;
- 摆脱 ASR/TTS 依赖:现在训练数据靠 ASR 转文本、TTS 合成语音,模型上限受限于 ASR/TTS 质量,未来要直接用 “原生音频数据” 训练,突破现有上限。
- 本文标题:语音对话 | Kimi-Audio 端到端语音大模型
- 创建时间:2025-06-26
- 本文链接:2025/2025-06-30-Kimi-Audio/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!