过去两年,TTS(语音合成)模型的演化速度令人惊叹。从“能说清楚”到“说得自然”,再到如今“实时流式”“对话级拟人能力”,背后不仅体现了大模型方案与语音合成的成功结合,还有整个数据清洗、表征学习和建模范式的革新。
小红书智创音频团队的 FireRedTTS 系列正是其中比较具有代表性的工业级框架,从 FireRedTTS 最初的基础模型出发,一步步扩展到 FireRedTTS-1S 流式生成与 FireRedTTS-2 长对话生成,这也体现了近两年 TTS 大模型的热门课题风向变化。
本文将完整梳理 FireRedTTS、FireRedTTS-1S 和 FireRedTTS-2 三篇论文的核心设计与演进脉络,只针对论文原理,具体代码实践可以参考开源链接。三篇论文题目为:
- FireRedTTS: A Foundation Text-To-Speech Framework for Industry-Level Generative Speech Applications
- FireRedTTS-1S: An Upgraded Streamable Foundation Text-to-Speech System
- FireRedTTS-2: Towards Long Conversational Speech Generation for Podcast and Chatbot
FireRedTTS: A Foundation Text-To-Speech Framework for Industry-Level Generative Speech Applications
论文:HTTPS://arxiv.org/pdf/2409.03283
demo:HTTPS://fireredteam.GitHub.io/demos/firered_tts/
开源:https://github.com/FireRedTeam/FireRedTTS
1. 数据清洗流程 pipeline
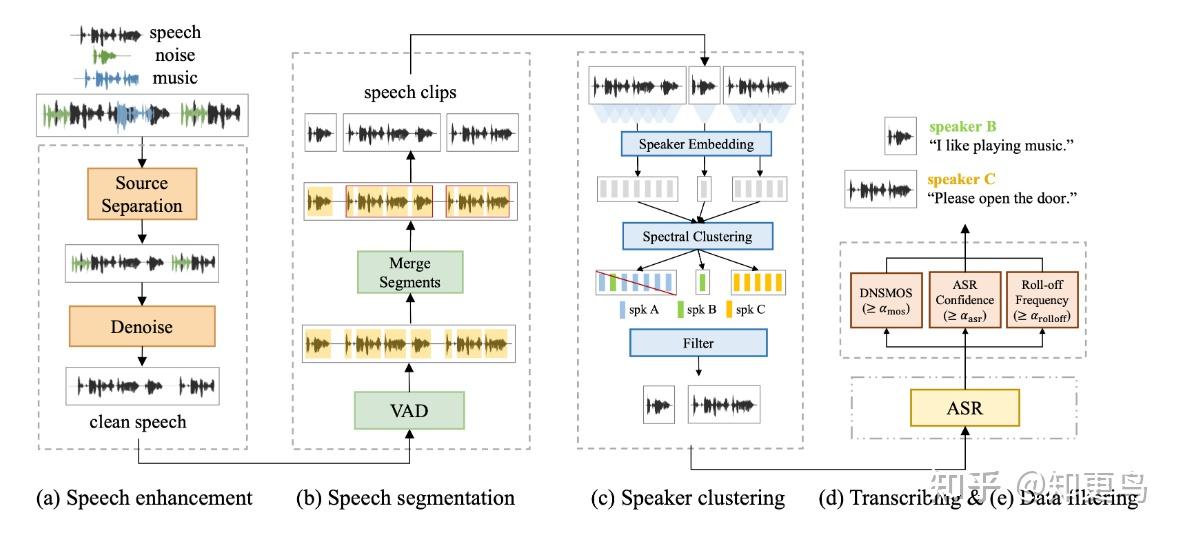
各模块详解:
1.1 Speech Enhancement(语音增强)
Source Separation(声源分离)采用 demucs 工具,主要针对背景音乐
Denoise(降噪)采用 deepfilternet,去除背景噪声(实测效果确实不错)
1.2 Speech Segmentation (语音切分)
- VAD,语音活动性检测,去除静音部分
- 论文自己训练了帧级别的 TDNN VAD 模型,帧移 25ms,切分成 2-20s 的音频片段
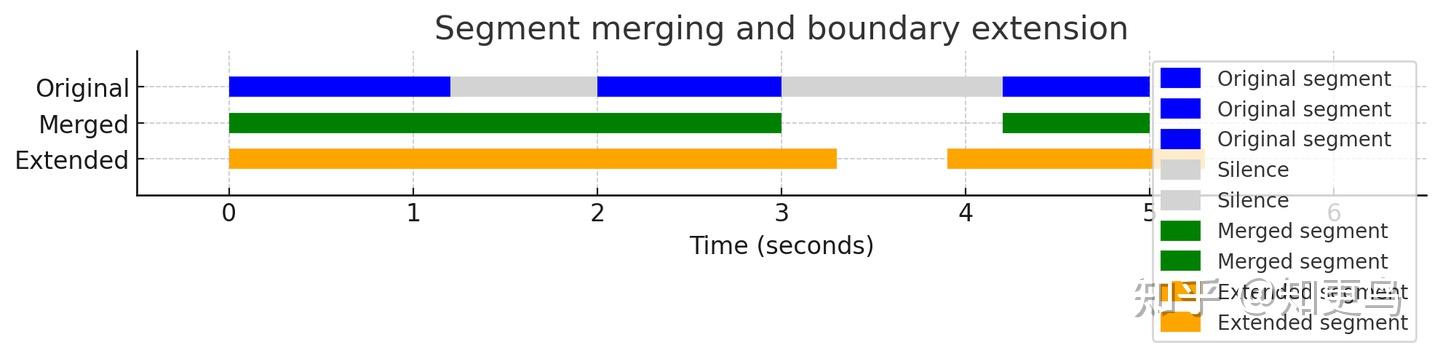
- 细节一:如果两个音频片段之间的静音时间少于 1 秒,就把它们合并成一个整体,避免切断连续的语音
- 细节二:每个音频片段的开头和结尾都额外留出 0.3 秒,保证语音的送气音或尾音不会被截断
1.3 Speaker Clustering(说话人聚类)
在 speaker embedding 的基础上进行谱聚类
- K-means 方案,将聚类中心相似度超过 0.8 的类别再进行二次聚类
提取的speaker embedding 来自 wespeaker
从论文表述理解,虽然论文提到是在 speaker embeddings of all speech segments 上进行的谱聚类,但结合后文说的每个 speech chunk 都会得到一个聚类中心,所以实际上应该是在所有 speech segments 的 chunk 级别 embedding 上进行的聚类,这样就和 pyannote 一类工具是非常类似的方案了
- 额外后处理:
- 聚类后包含多个 speaker id 的 segment 被扔掉
- segment speaker embedding 和聚类中心之间差距大的扔掉(大多是低质量或多说话人的情况)
1.4 语音识别和过滤
- ASR 转写文本:只用了一个 two-pass 的 RNN-T 模型
- 数据过滤条件:
- DNSMOS 分数:OVL_MOS > 3.3
- 保留高采样率数据:计算总能量 99.5% 分位数的频率(roll-off frequency),只保留 7kHz 以上的数据
- ASR 只保留了置信分数在 0.8 以上的片段
结论:以上全流程之后,62.4 万小时数据,剩余 24.8 万,论文使用其中 11 万中文 + 4 万英文的子集进行训练
2. Semantic Aware Speech Tokenizer (SAST)
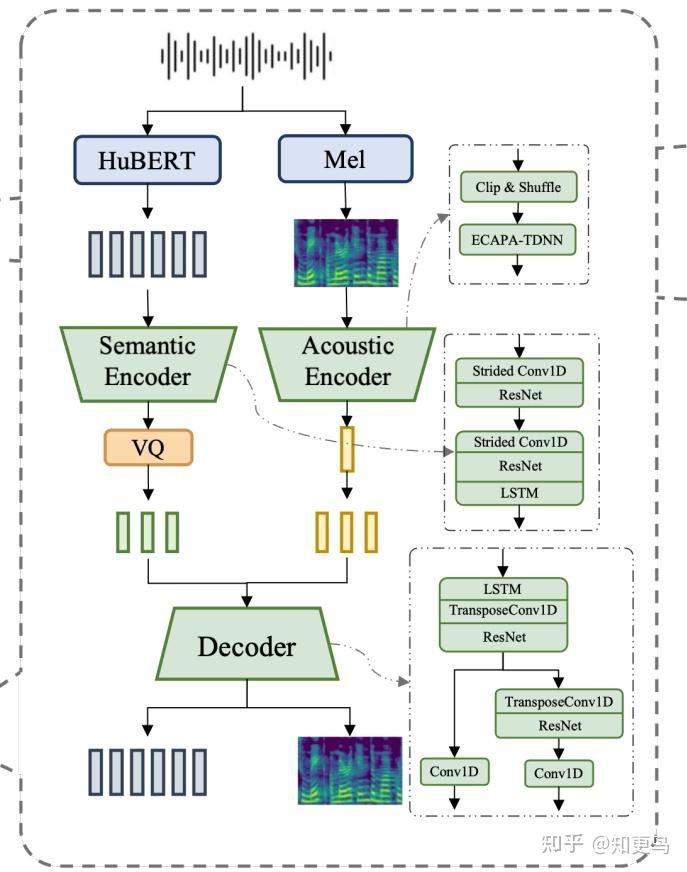
- SAST 模块类似 HTTPS://arxiv.org/pdf/2406.02940 提出的双路 PQ-VAE 方案,借鉴了 dual-decoding PQ-VAE 的思路,但采用“语义 + 声学”双路编码器来实现解耦。
- Semantic Encoder(语义编码器):将 Hubert 提取的 embedding 经过 ResNet + 降采样到目标帧率(25Hz)
- VQ:这里采用了 PQ 即 Product Quantization(乘积量化)的方案
- codebook size: 16384
- Acoustic Encoder(声学编码器):梅尔特征层面的编码
- 网络结构为 ECAPA-TDNN,输出是 pooling 之后的单个全局 embedding 表征
- 关键:为了避免除了音色/风格/声学环境等全局之外的信息泄露,采用了 Clip&Shuffle 的方案来进行解耦
- 具体操作:随机选择 25%-75% 的音频区域,然后切成 1s 片段,再随机拼接
- Decoder + 训练目标:同时重建语义空间的 hubert embedding 和声学空间的 mel 特征
3. 第一阶段:LLM
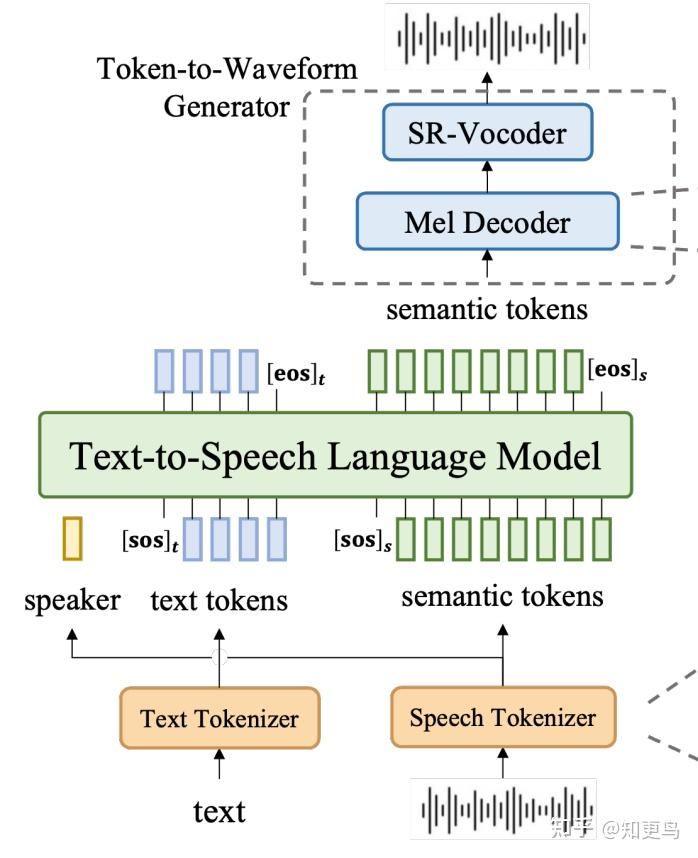
训练方案:
- 单条音频训练,不区分 prompt 和 target
- speaker embedding 就是从 target 音频抽取得到的(经过 SAST 中 ECAPA-TDNN 抽取得到)
- 文本 tokenizer:使用 BPE
推理方案
- LLM 的输入/condition:prompt audio 的 speaker embedding 和文本 Token + 目标待合成文本
LLM 参数量:400M
4. Token 生成波形 (token2mel + vocoder)
- 基本思路:
- Token 先经过 Mel Decoder 还原为 16kHz 的梅尔特征
- 梅尔特征再经过 16kHz → 48kHz 的超分 Vocoder 还原为波形
4.1 Mel Decoder 方案一:Flow Matching
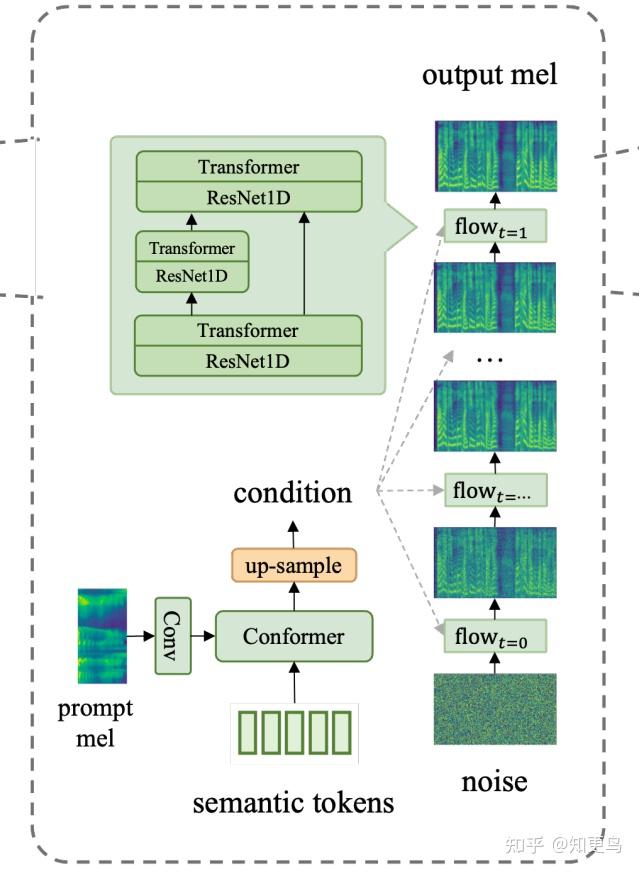
- 25Hz 的 semantic token 先经过 conformer encoder 和上采样,再作为 flow matching 的输入
- 注意:prompt mel 是通过 cross-attn 引入到 conformer encoder 的
- 示意图中 speaker embedding 似乎没有作为额外条件引入
4.2 Mel Decoder 方案二:Streamable Codec Decoder
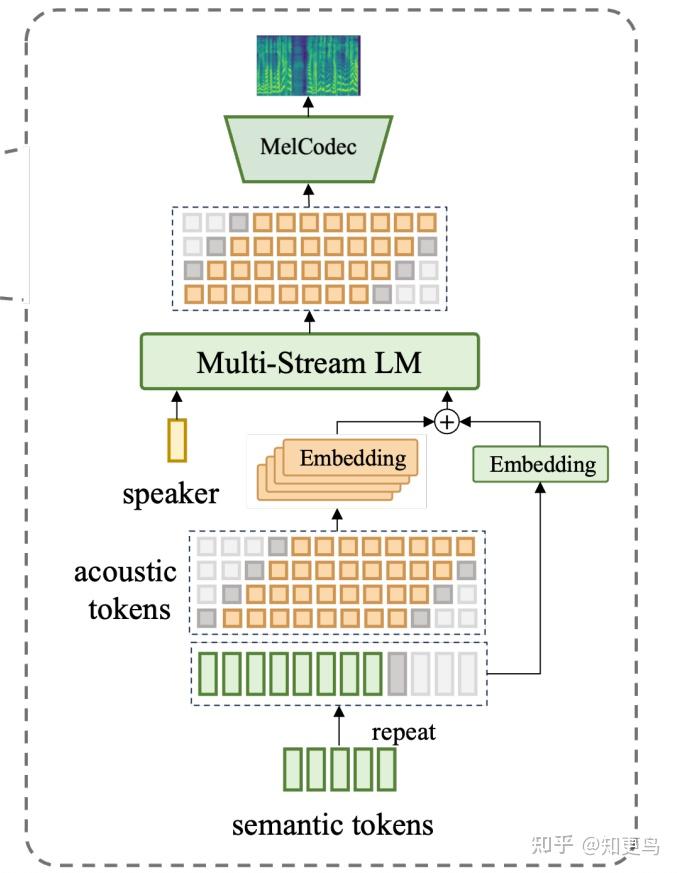
动机:Flow Matching 推理太慢,而且不好做流式实现
Mel Codec:声学表征的 mel codec
- 将 100Hz 的梅尔特征,量化为 4 层 50Hz 的离散化表征,每层 codebook size 都是 16384
使用 Multi stream LLM 进行预测:
- 25Hz 的 semantic token 直接作为输入,上采样到匹配的 50Hz
- 采用 delay pattern 的方式训练(以图中的 delay 参数 d=1 为例)
- 第一层 Codec 比 semantic token delay 一个 token,每层 codec 再分别比上一层 delay 一个
- 第一个 semantic token 预测出来,到对应全部 4 个 codec token 预测完,需要额外多等 4 个 token
- 50Hz 每个 token 20ms,相当于额外会有 100ms 的延迟
补充:Vocoder 训练的是 48kHz 超分声码器,采用 BigVGAN-v2 结构
5. 模型应用
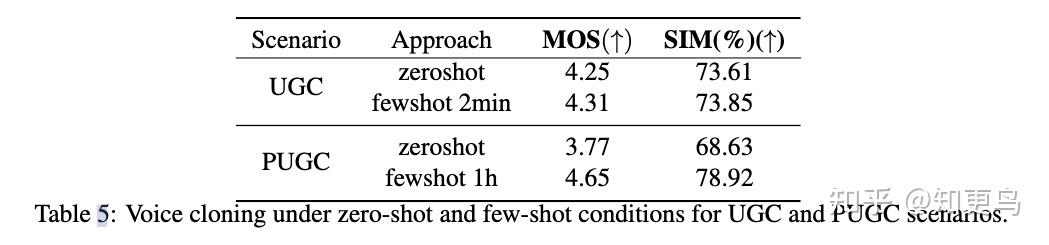
5.1 Voice Cloning (UGC) 和 Speaker Finetuning (PUGC)
- UGC 场景采用常规的 one-shot 推理,prompt 需要额外经过降噪处理
- PUGC 采用 SFT 方案训练模型,该部分没有额外特殊说明
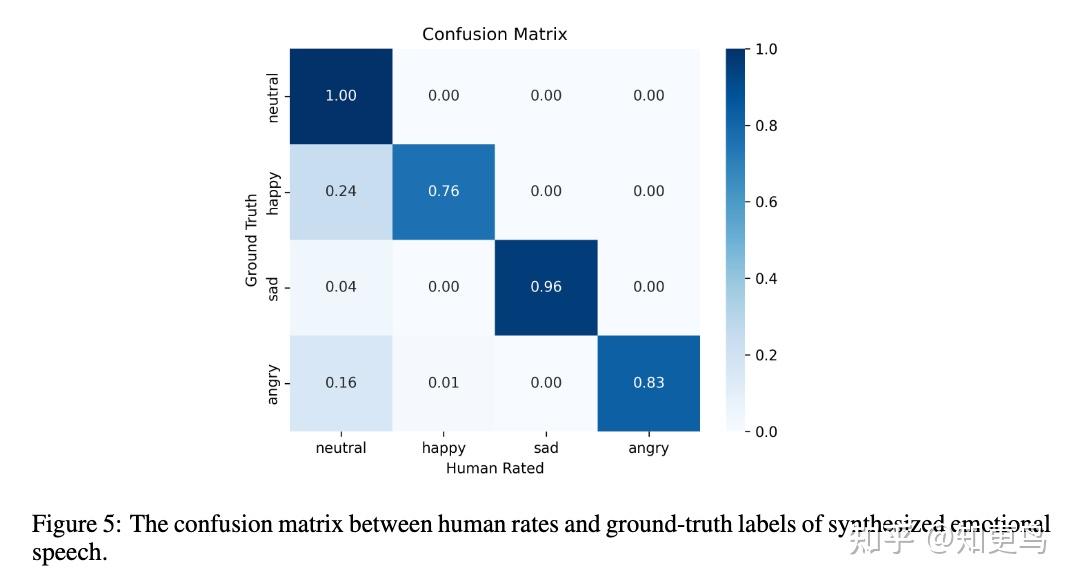
5.2 Instruct Tuning 指令微调,支持副语言合成和情感化 TTS
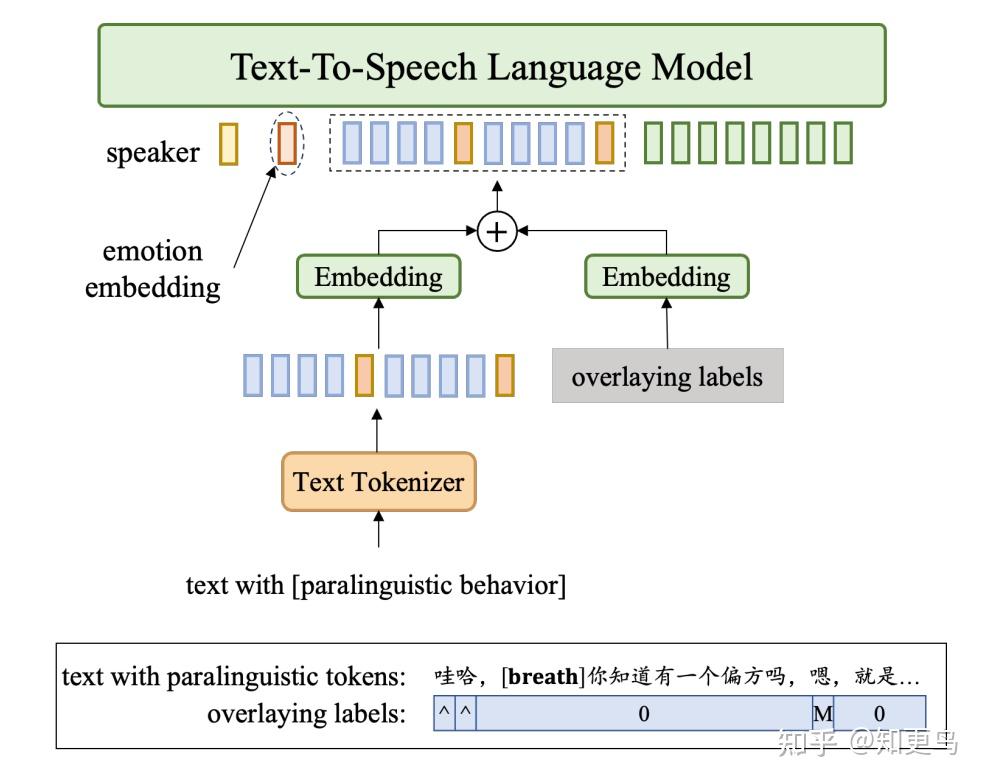
- 50 小时数据集,支持情感和副语言信息标注
- 情感合成设计:
- LLM 增加了 emotion embedding 作为条件输入(使用的 embedding 层,不是额外模型抽取)
- 情感:中性、开心、悲伤、生气
- 注意:在训练时,额外从同一说话人的音频中提取独立的说话人嵌入,以实现说话人与情感的解耦
应该是 SAST 中 ECAPA-TDNN 的 clip&shuffle 训练方式,虽然提取音色的同时避免语义的泄露,但无法保证解耦出情感
完成解耦,相当于具备 zero-shot emotional tts 的能力,即使推理时的 prompt audio 不是对应情感
也可以通过控制 emotion embedding 来实现目标情感的合成
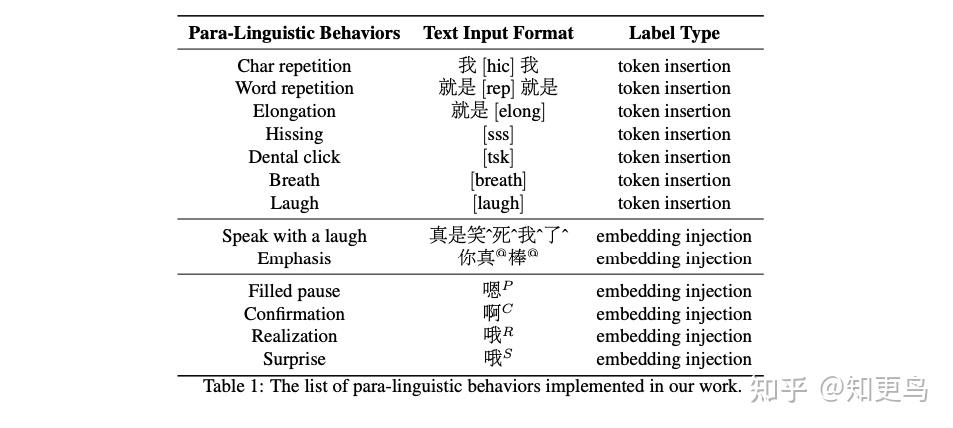
- 副语言合成设计:
- 插入额外 token:呼吸声、笑声、停顿、拖长音…
- 对应文本插入 embedding:边笑边说、重读…
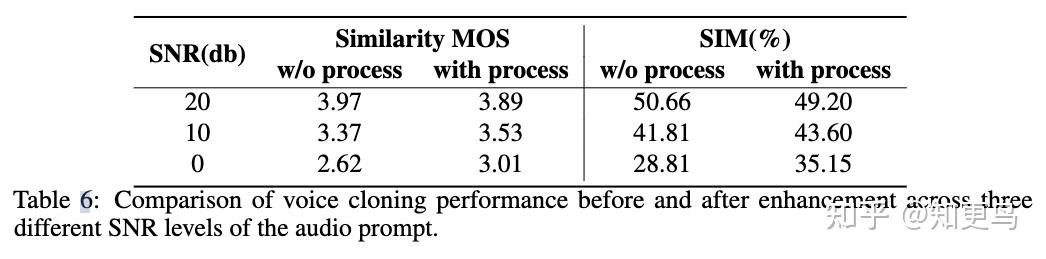
6. 实验评估


FireRedTTS-1S: An Upgraded Streamable Foundation Text-to-Speech System
论文:HTTPS://arxiv.org/pdf/2503.20499
demo:HTTPS://fireredteam.GitHub.io/demos/firered_tts_1s/
开源:https://github.com/FireRedTeam/FireRedTTS/tree/fireredtts-1s
FireRedTTS-1S 是在 FireRedTTS-1 (为了更好区分,FireRedTTS 下文称为 FireRedTTS-1)基础上进行的升级,针对高质量流式 TTS 进行的补充和加强。一部分工作,比如 SAST Tokenizer、LLM 的结构和 FireRedTTS-1 基本一样,不予赘述,只记录一些新的值得关注的内容。
- 中英文训练数据量从 15 万小时扩充至 50 万小时,数据处理流程与 FireRedTTS 相同
- 流式 TTS 方案分为两种:
- 输出是梅尔特征的 chunk 级的流式 flow matching 方案
- RTF = 0.1,latency = 300ms
- 输出是多层 codec 的 multi-stream LM 方案(与 FireRedTTS-1 中设计基本相同)
- RTF = 0.3,latency = 150ms
1. 流式方案一:流式 Flow Matching
- 方案简述:Flow Matching 预测梅尔特征,加上 Vocoder 恢复波形
- 梅尔预测的是 16kHz,使用 BigVGAN 超分的声码器,转换为 24kHz 波形
- 注意:超分声码器采用的是伪流式的推理方式
1.1 CFM 模型结构细节
(a) Token Encoder
Semantic Token 的 Encoder 模块采用了 look-ahead 结构,不是完全因果的,而是卷积的感受野增加了额外未来的 3 个 token 长度(25Hz 帧率情况下,对应 100ms)。因为梅尔特征是 100Hz 的,所以需要四倍上采样(两个上采样层)。
(b) Flow Matching 的速度场 estimator
采用 DiT 结构,每个 self-attn 层之后增加了两层因果的卷积层。DiT 的设计中,为了获取更好的效果:
(1) 训练阶段使用梅尔的前 30%(随机 0-30%) 作为额外的 prompt mel 特征
FireRedTTS-1 用的是 prompt mel 作为 cross-attention 的 key/value
(2) 补充增加了 speaker embedding,从 SAST tokenizer 中抽取得到
FireRedTTS-1 没有提到使用了 speaker embedding
(3) 流式方案主要在于设计合理的 mask 策略:
参考 CosyVoice2,对于每个样本,随机可能有以下 mask 方案
- 训练阶段:先训练 80w steps 使用方案 A mask,然后训练额外 10w steps 随机用 A-D 中的 mask 方案
- 推理阶段:选择方案 D,缓解了方案 B 在推理阶段 CFM 对于 K-V Cache 的显存需求,同时也比只看 1s 的方案 C 效果更好(方案 A 不具备流式能力)
- 总之,训练的 CFM 同时具备流式/非流式/不同 chunk 大小的推理能力
- 补充说明:DiT 使用 160M 参数
1.2 伪流式的 BigVGAN 声码器
(a) 伪流式处理思路
- 之所以称为伪流式,是因为声码器并不是专门训练的因果的声码器
- Mel 频谱是按照 Flow Matching 预测的 chunk 进行波形恢复的
- 在对第 i+1 块梅尔 chunk 恢复波形的时候,会把前面 8 帧拼接在一起输入到超分的声码器(SR-Vocoder)
- 目的:给梅尔 chunk 的起始帧提供足够的上下文,避免声音不连续或不自然
(b) 音频拼接
- 不同 chunk 的音频之间有 8 帧的重叠
- 通过 fade-in / fade-out 淡入淡出 方式进行交叉拼接
- 减少块与块之间拼接时产生的“咔嗒声”或不连续感
(C) 流式与非流式的对比
- 非流式(一次性生成):可以并行处理,吞吐量高,但延迟大
- 流式(逐块生成):延迟小,能实时应用,但牺牲了吞吐率
- 伪流式方法就是在两者之间做折中。
(d) 延迟公式
文中给出了理论延迟上界:
其中,
表示 semantic LLM 预测一个 token 的时间 代表 flow matching 预测 chunk 梅尔所需的时间 代表声码器恢复波形的时间
中 表示一个 chunk 中的 semantic token 个数,额外 +3 是因为在 Flow Matching 预测时,卷积的感受野增加了额外未来的 3 个 token 长度(前文提到),因此需要等到未来的 3 个 token 生成之后,一并作为 Flow Matching 预测梅尔特征时候的输入。
当 chunk 是 1 秒时,
2. 流式方案二:Acoustic LM
2.1 Acoustic Codec 设计
模型结构:
- Codec 训练时,输入是 16kHz 波形,还原的是 24kHz 波形,所以属于超分类型的 codec,主要是考虑了训练 LLM 时 16kHz 的数据更容易获取
- 训练方案:100w steps 全参数训练 + 30w steps 只微调 decoder 的参数
2.2 Acoustic LM 方案
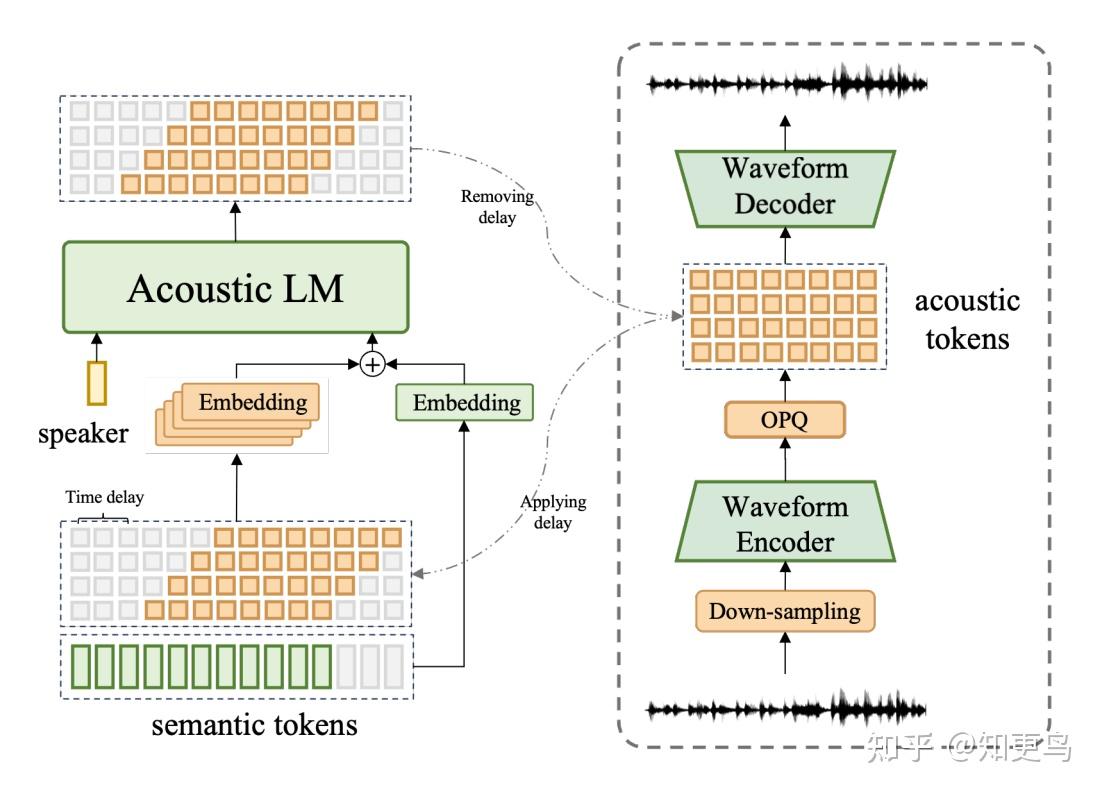
模型结构上,与 FireRedTTS 类比,semantic token 和 acoustic codec 之间存在 time delay d,各层 acoustic codec 之间也 delay=1。LM 的输入,是错位后的各类 embedding 之和,输出是 8 层 acoustic codec 的预测结果。
这套方案的理论延迟 latency 为:
- $latency \leq (d-1)t_s + m(t_s+t_a) + t_c$
$(d-1)t_s
m(t_s+t_a)$ 代表开始生成 acoustic codec,包含 semantic llm 生成 semantic token 和 acoustic llm 生成 acoustic codec 的时间,m 应该代表的是 codec 的层数。
通俗理解,就是生成 semantic token 和 acoustic token 的时间之和,再加上 codec decoder 还原波形的时间。论文工程优化之后,需要 150ms 的首包延迟。
3. 实验结论
- 客观评测整体效果指标上和 cosyvoice2 差异性不大(尤其是训练数据量扩大到 50 万小时)
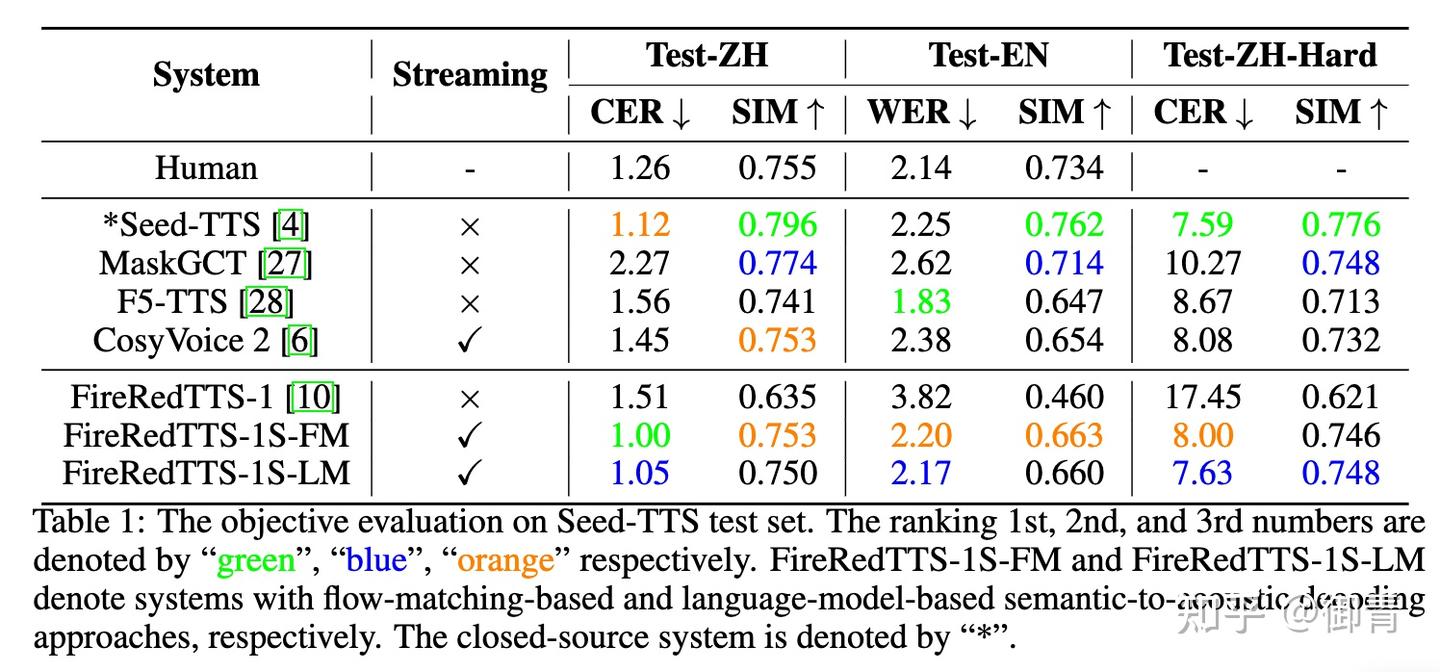
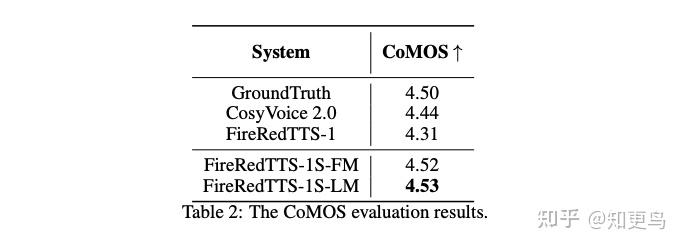
- 主观评测效果也不错(和 GroundTruth真实音频不分上下)
FireRedTTS-2: Towards Long Conversational Speech Generation for Podcast and Chatbot
论文:HTTPS://arxiv.org/pdf/2509.02020
demo:HTTPS://fireredteam.GitHub.io/demos/firered_tts_2
开源:https://github.com/FireRedTeam/FireRedTTS2
FireRedTTS-2 在 FireRedTTS 和 FireRedTTS-1S 的基础上,进行了功能的升级和扩充,着重针对多人对话的长语音流式生成任务进行了升级。
主要改动:新训练了 12.5Hz 的流式多层 Speech Tokenizer;文本与语音 token 按照时间顺序,采用 interleave 交叠的格式训练,并且建立双路 dual-transformer:第一层 token 采用大参数 transformer 训练;小参数模型补充生成后续层的 token。
1. 12.5Hz 的 Speech Tokenizer
- 为了适配长语音合成的任务,设计采用更低的帧率,同时采用的是多层 codec 的形式
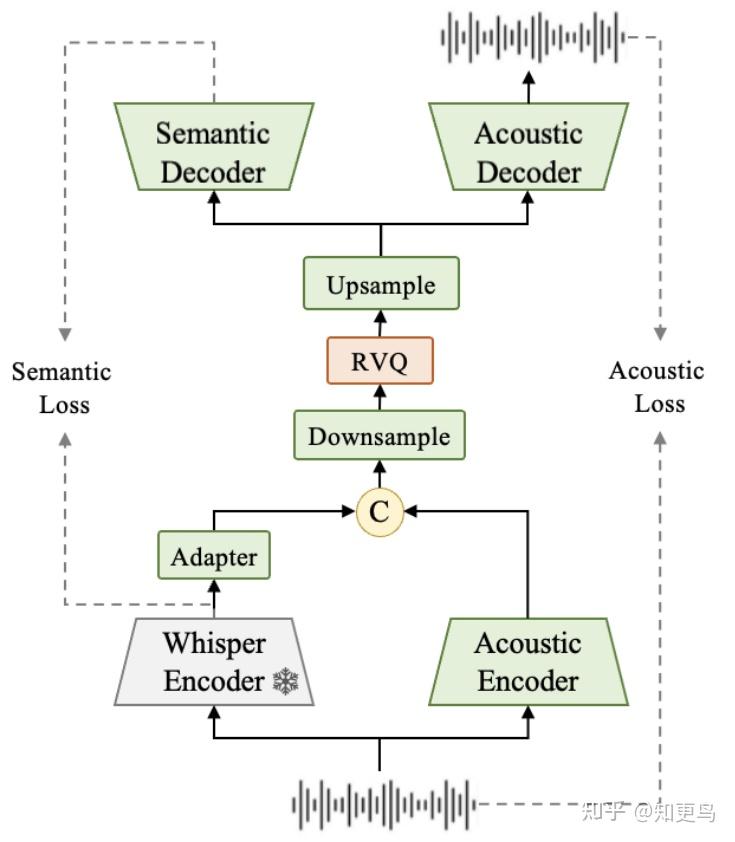
Encoder
- Whisper Encoder 从 16kHz 音频中,抽取预训练的语音 embedding,增加 adapter 可学习的参数
- Acoustic Encoder 与 Whisper Encoder 结构相同
- Whisper Encoder 和 Acoustic Encoder 的帧率都是 50Hz
Concat 之后
- 下采样 4 倍到 12.5Hz
- 通过 RVQ 多层量化得到 16 层 token,每层 codebook size 2048
- 再上采样 4 倍到 50Hz
Decoder
- Semantic Decoder 预测 whisper embedding 语音表征 → semantic loss
- Acoustic Decoder 采用 vocos 网络结构恢复原始波形 → acoustic loss
- 推理阶段,Acoustic Decoder 之后直接从预测的 16 层 token 来恢复波形的 codec decoder
- Vocos 中的卷积和 attention 层,可以设计为因果结果来保证流式/非流式效果
训练策略分为两阶段:
第一阶段(非流式,注重语音质量与语义细节):
- 声学解码器使用非流式结构,目标是预测 16kHz 语音。
- 使用 约 50 万小时语音数据,在 32 张 H800 GPU 上训练 32 万步,每个样本随机裁剪为 6 秒。
- 在最后 3.5 万步 中,引入 感知损失(perceptual loss)以进一步提升语义细节的保真度。
第二阶段(流式,注重实时性与高保真):
- 固定编码器参数,将解码器替换为 全流式结构,预测 24kHz 高保真语音。
- 使用 6 万小时高保真语音数据,继续训练 8 万步。
整体思路是:先用海量数据和非流式模型学习强泛化能力和高质量表示,再通过流式解码器和高保真数据微调,实现实时性与音质的平衡。
2. TTS 模型结构
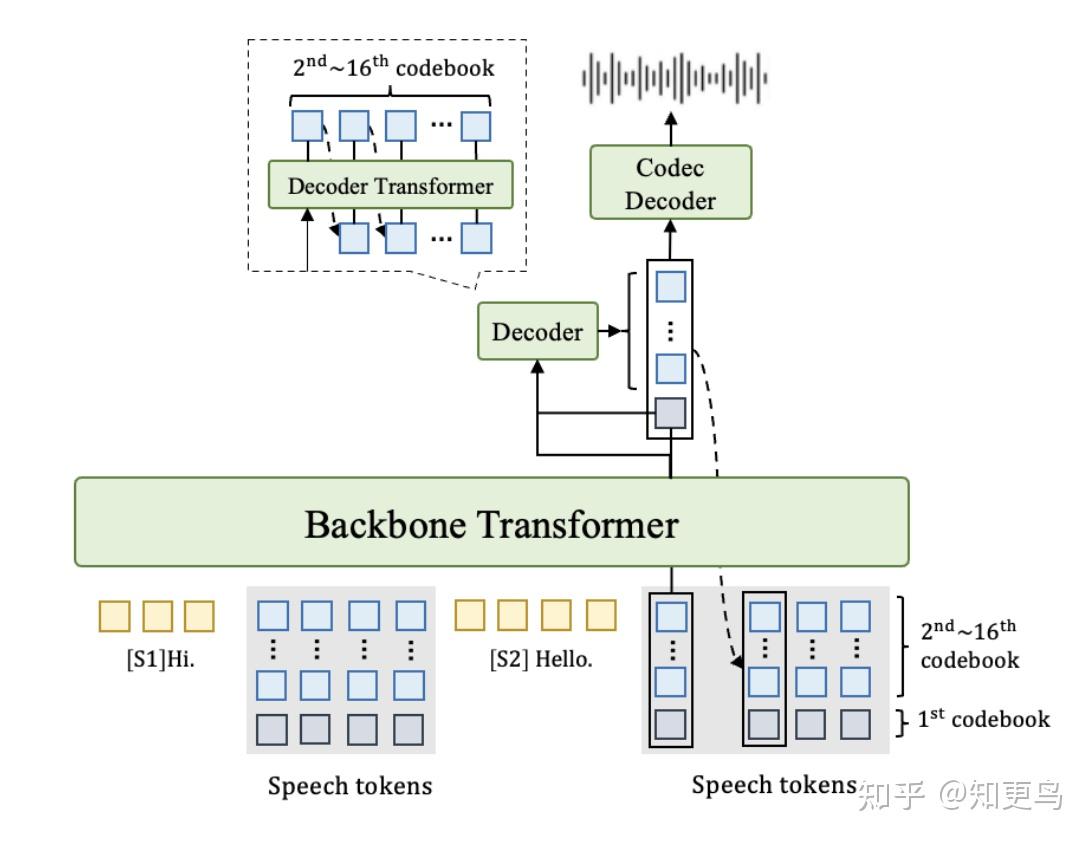
2.1 模型结构
采用双 Transformer 架构,输入是交错的文本–语音序列(text–speech interleaved sequence)
- 与 Moshi 这类模型结构类似,把第一层 token 作为主要的 token 来看待的话,相当于先在时间维度的 temporal transformer 上预测第一层 token,再用 depth transformer 小 decoder 预测后续层的 token
主干 Transformer(称为 backbone):处理交错序列,负责预测第一层语音 token
解码 Transformer(称为 decoder):在 backbone 隐状态以及第一层 token 的基础上,生成剩余层的语音 token
本文的两个 Transformer 都基于 Qwen2.5 架构
2.2 改进动机
现有方法通常采用 delay-pattern(第 i 层 token 向右偏移 i–1 步),存在两个缺点:
- 每一步预测,只能看到前一层的部分语音上下文,削弱了条件建模能力
- 比如:delay-pattern d=1 时,预测 t=2 的第一层 token 只能看到 t=1 的第一层 token,看不到 t=1 时刻所有层的信息
- t=1 时全部层的 token,预测需要 N 次 backbone transformer 的自回归推理,延迟高
FireRedTTS-2 是通过 backbone + decoder 分工,减少计算量和首包延迟
2.3 加权多任务损失函数
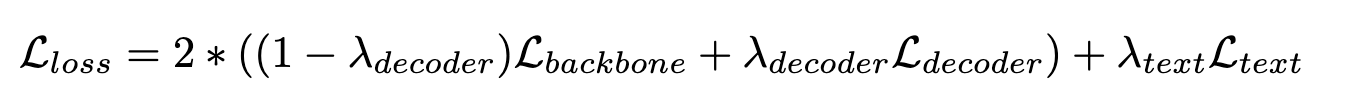
- 文本模块采用类似 base-tts 的方式,在输入文本上也加入自回归的预测 loss,但是权重很小
- decoder 模块的 loss,只在 1⁄8 的 speech 片段上计算(论文说是为了提高训练效率)
2.4 三训练策略
预训练(Pretraining)
- 使用 110 万小时单人语音数据,训练 2 个 epoch,建立基础的 TTS 能力
后训练(Post-training)
- 在 30 万小时多说话人对话数据上训练 5 个 epoch,每个对话包含 2–5 位说话人
- 目标是增强模型的多说话人对话生成能力
有监督微调(Supervised Fine-Tuning, SFT)
- 使用少量特定语音数据,进行微调,使模型适配特定音色/目标场景
2.5 推理过程
- 每一步解码时,decoder 同时使用 backbone 的隐状态和已预测的第一层 token,从而具备完整上下文
- 与 delay-pattern 相比,只需一次自回归推理 + N–1 次小 decoder 的步骤,相比于原本 N 次自回归推理,延迟能够大幅降低
- 直接生成语音 codec,无需额外 token-to-speech 模块,codec decoder 直接还原波形,支持流式输出
3. 模型应用
3.1 应用一:支持常规的 Voice Cloning
论文里推理方式有点奇怪,LLM 预测生成的 token 还会和 prompt 的 token 拼接再使用 speech tokenizer 的 decoder 还原出波形,还原之后再将 prompt 部分剥离出去
3.2 应用二:基于上下文历史的交互式对话
传统方案:ASR + LLM + TTS,TTS 不具备控制能力时,可能合成不恰当的情感/韵律
传统方案进阶:仍然是 ASR + LLM + TTS,但文本 LLM 生成控制 TTS 的情感标签,同时 TTS 可以接受情感标签输入,达到更好的显式控制效果
- 缺点:文本 LLM 需要 finetune 才能更适配,增加了级联系统的复杂性
论文提出了下面的更理想/更智能的方案:
思想:根据对话上文的信息,推测出应该用什么样的情感和韵律,达到 context-tts 的效果
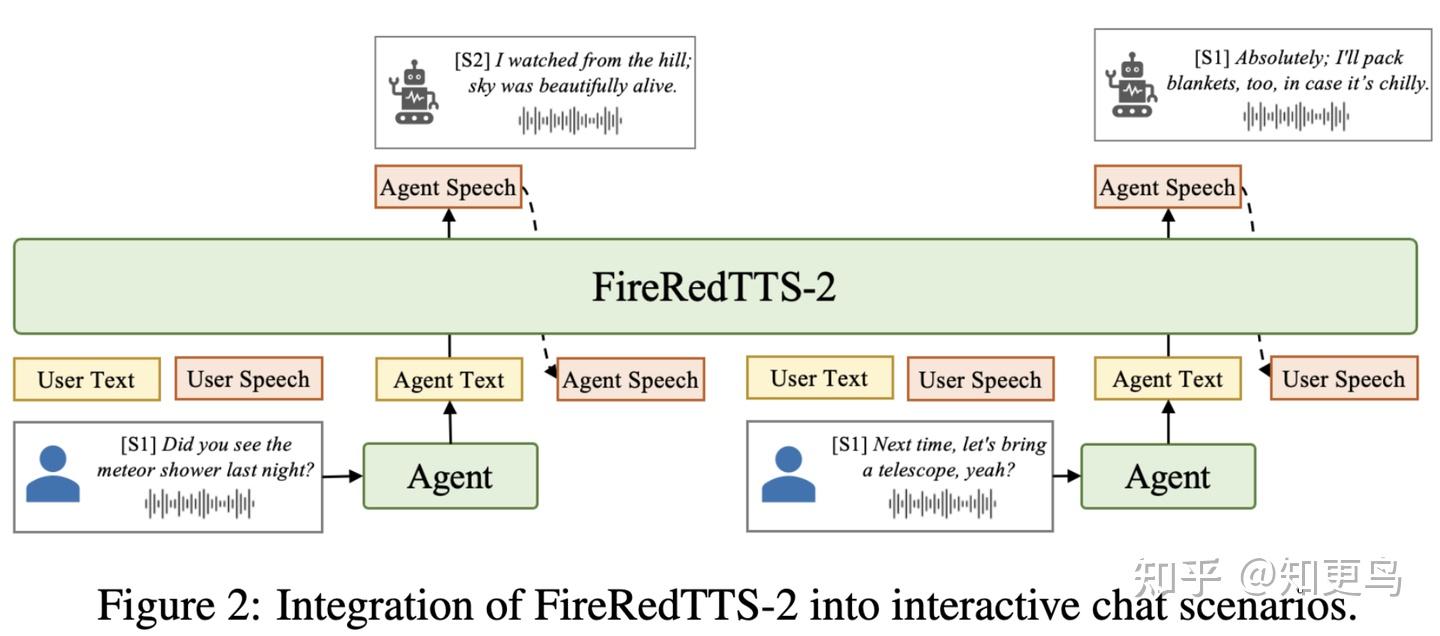
- 论文具体操作
- 设计了单个人 15 小时的语音数据,包含 6 种情感
- 根据录制的语音数据,使用文本 LLM 构造上文,并通过 TTS 合成得到上文的语音数据
- 基于上述构建的对话类型的数据,对 FireRedTTS-2 进行微调,就能根据对话历史来合成更拟人的效果了
- 注意:User 的信息对应 [S1],Agent 的信息对应 [S2]
【此处的对话能力疑问】
一般来说,要具备真正的对话式语音合成能力,需要【真实对话数据】来支撑。论文中使用的数据却是由 TTS 模拟生成的,这带来了一些局限。在这种模拟数据里,所谓的对话语音(例如 U1 表示前一句,U2 表示后一句),最大的问题是:额外生成的上文语音 U1 并不能在情感和韵律上与真实语音 U2 建立自然的关联。由于生成顺序的关系,大模型至多能保证 U1 的文本内容与 U2 有关联,但其声学特征只是普通 TTS 输出,和 U2 的真实表达往往不匹配。
因此,在 TTS 模拟对话数据的条件下,FireRed-TTS2 的对话语音合成主要能利用以下几类信息:
- 上下文文本(User 与 Agent 的对话内容):提供语义关联,帮助模型理解对话逻辑。
- Agent 的历史语音:保证合成的 Agent 回复在情感和韵律上的一致性。
- User 的语音:作用相对有限。如果有真实的对话语音,模型才能更好地捕捉并利用用户语音的情感/韵律,从而影响 Agent 的回复。举例来说,同一句话“你怎么来了?”,在实际场景中,如果用户用“惊讶”的情感说和用“生气”的情感说,Agent 的理想回复应在文本内容和语音表达上都有所差异。但如果训练数据的对话语音不真实,就学不到这层关联。
- 更匹配的文本回复:依赖文本 LLM 的对话生成能力(类似 Qwen-Audio 这类“语音输入+文本回复”的模式)。
- 更匹配的语音表达:需要 Agent 在生成时根据 User 的语音情感做出相应调整,类似 Contextual-TTS 的能力。
3.3 应用三:播客/对话生成
相比于两个音色单独合成,韵律效果一致性更好。支持提供两个音色的 prompt(文本 + 音频)合成对话音频。支持 3 分钟长的语音合成,最多支持 4 个音色。也支持使用定制音色的数据进行后训练(比如 50 小时对话数据)额外微调 15 epoch。
4. 实验结果
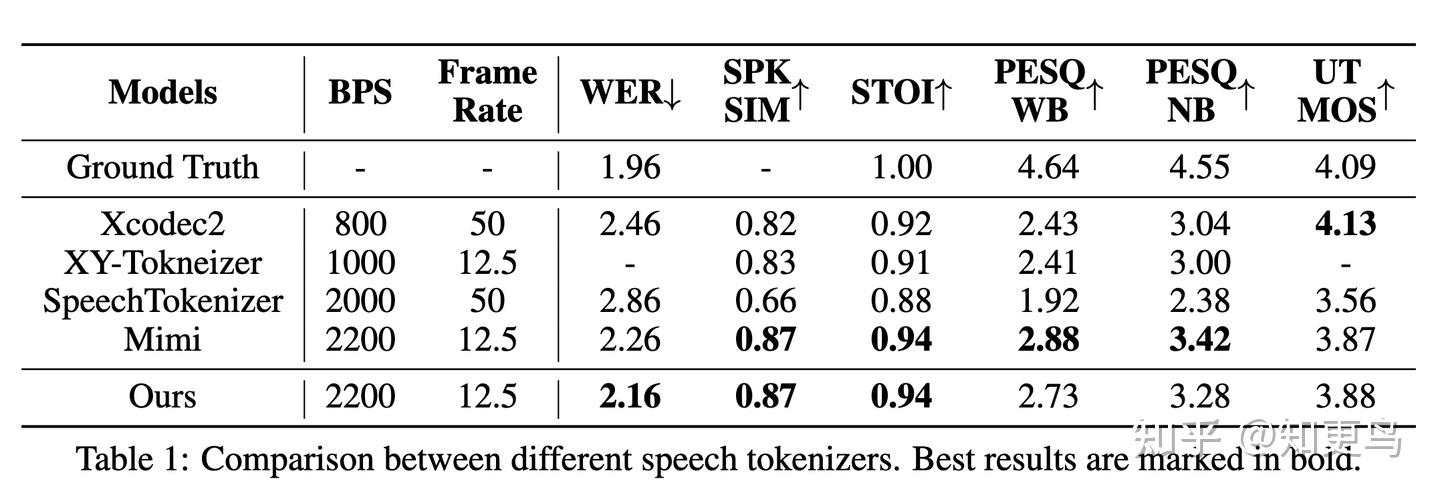
Speech Tokenizer 对比
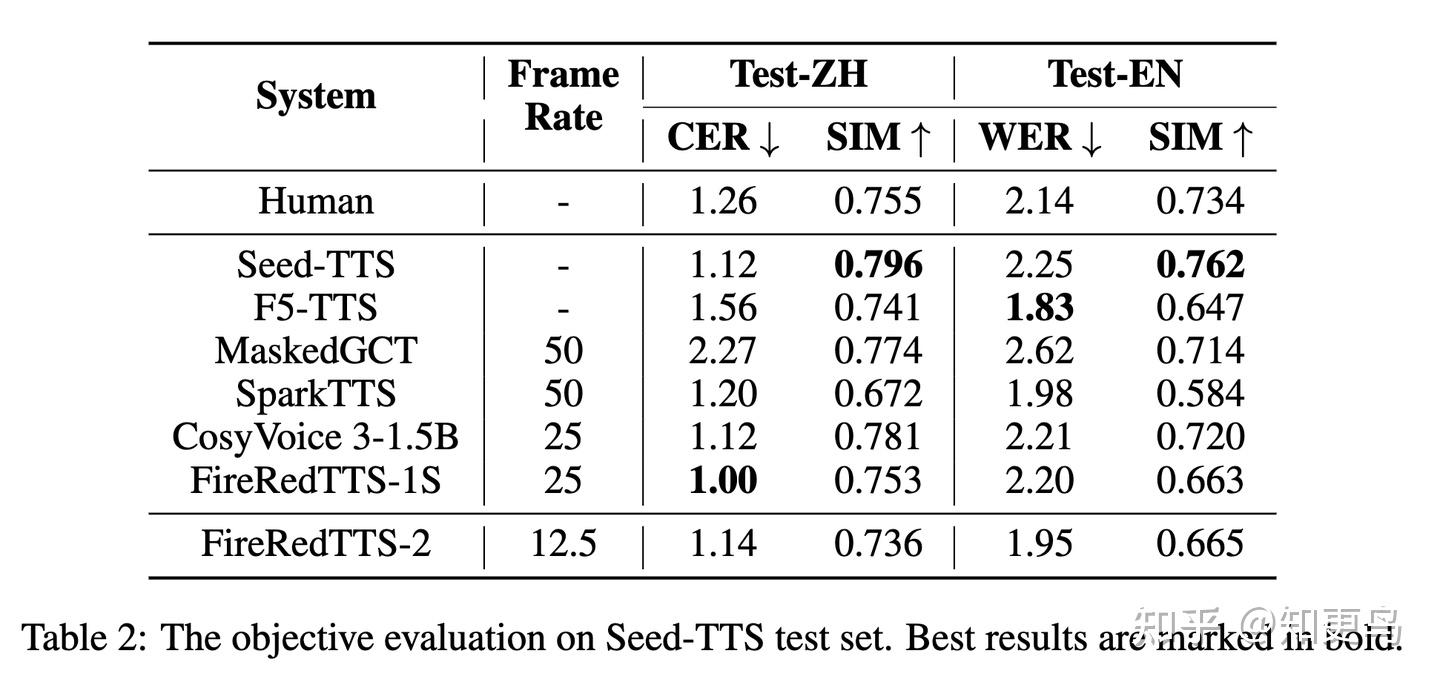
Voice Cloning 评测
交互式对话的情感表达能力
下表的结果表明,FireRedTTS-2 能够通过利用前文的文本和语音上下文,从隐含的上下文线索中推断出合适的情感,从而实现更拟人的对话体验。
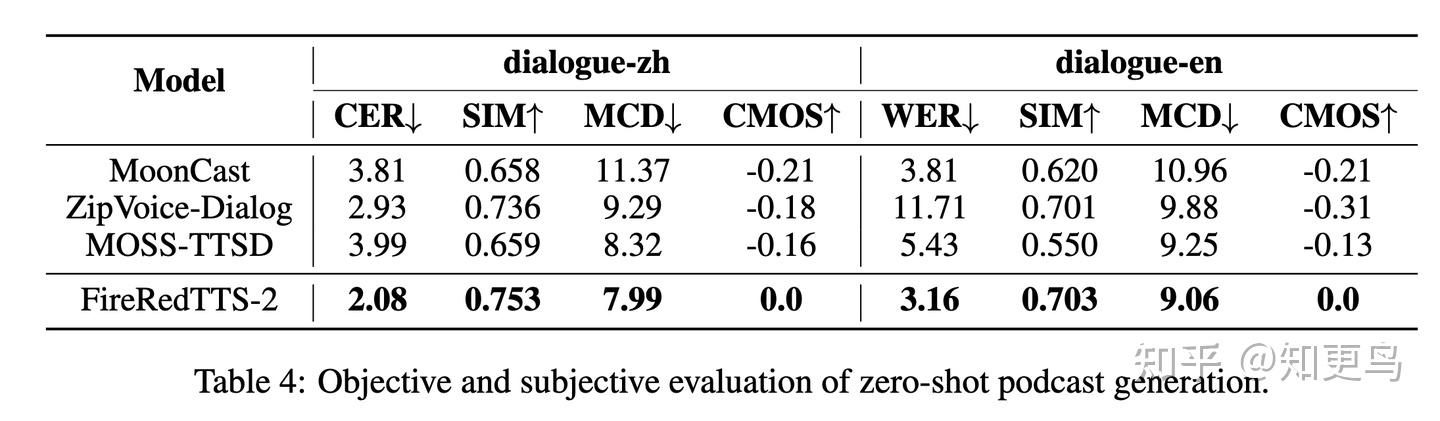
播客/对话生成能力

总结与启发
回顾 FireRedTTS → FireRedTTS-1S → FireRedTTS-2,可以清晰看到工业级 TTS 的演进路线:
FireRedTTS:打好基础
- 大规模数据清洗
- 语义感知 Tokenizer(SAST)
- 统一的 LLM + Vocoder 框架
FireRedTTS-1S:强化流式能力
- 扩充数据规模
- CFM + 因果 Codec
- 伪流式 Vocoder,在延迟与质量间找到平衡
FireRedTTS-2:迈向拟人化对话
- 12.5Hz 多层 Tokenizer 支撑长语音
- 双 Transformer 架构降低延迟
- Context-TTS 与播客生成,走向多说话人、长时交互
同时,系列论文的具体实践也表明:
- 高质量数据依旧是第一生产力,高质量效果目前仍需复杂的清洗流程来保证;
- 流式生成离不开算法和工程双向优化,mask 策略到流式声码器都是关键;
- TTS 的未来是对话和多模态交互,不仅要“说得正确”,更要“符合真人对话感”。
可以说,FireRedTTS 系列只是完整展示了一条可能的路径:从基础合成能力,到实时流式生成,再到多说话人对话生成。不仅让 TTS “能用”,更让 TTS 真正“好用”、适合更多落地应用的场景。
- 本文标题:专题分享 | 小红书 FireRedTTS 系列:从基础合成能力到长对话生成的演进
- 创建时间:2025-09-14
- 本文链接:2025/2025-09-14-FireRedTTS-series/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!