TL;DR 太长不看版
语音合成目前主流的路线是「离散语音 tokenizer + LLM」,典型代表有 VALL-E、Tortoise-TTS、Seed-TTS、CosyVoice、Minimax-Speech、Index-TTS、FireRed-TTS 等。但近一年兴起了一股新的技术趋势:直接在 连续表征(continuous token) 空间建模,结合自回归 + 扩散 / 流匹配两种模型方案,代表性工作包括 AR-DiT、MELLE、SALAD、CLEAR、VibeVoice、CALM、MELA-TTS、VoxCPM 等等。离散建模与连续表征建模的总体对比如下:
| 维度 | 离散 Token 路线(VALL-E, CosyVoice, FireRed-TTS 等) | 连续表征路线(AR-DiT, CLEAR, VibeVoice, CALM 等) |
|---|---|---|
| 表示方式 | 语音压缩为离散 token(码本) | 语音直接映射为连续 latent 向量 |
| 优点 | - 工业界方案较成熟(已有大规模落地) - 编码器如 DAC/WavTokenizer 成熟稳健 - 推理速度快,每步直接采样下一个 token |
- 无量化损失,高保真音质 - 架构更简洁,可单阶段端到端 |
| 缺点 | - 码本有限,存在信息损失 - Token 序列长,长语音的推理延迟大 - 训练流程复杂(编码器 + LLM 分阶段) |
- 连续空间建模更难,需扩散/流匹配/特殊设计的 loss - 推理迭代开销大,需要蒸馏/consistency 加速 - 强依赖连续表征的质量(VAE设计) - 需要额外的损失函数来预测 stop token 结束符(比如 eos token) |
| 代表模型 | VALL-E, CosyVoice, Index-TTS, FireRed-TTS | AR-DiT, MELLE, SALAD, Cont-SPT, CLEAR, VibeVoice, CALM, MELA-TTS, VoxCPM |
| 应用现状 | 已在部分场景落地 | 快速迭代中,VibeVoice 可生成 90 分钟播客,VoxCPM 已在 RTX4090 实现实时 |
以下是详细解读版。
最近两年,业界主流的语音合成模型主要是基于「离散语音 tokenizer (Codec) + LLM 建模」方案。其中影响力较大的工作,基本是在 Tortoise-TTS (https://arxiv.org/pdf/2305.07243) 的框架下发展而来,比如:阿里的 CosyVoice 系列、B 站的 Index-TTS 系列、小红书的 FireRed-TTS 系列,以及 Seed-TTS、Minimax-Speech 等未开源的工作,这些工作已经在各公司完成落地应用。
不过,近一年也出现了另外一类方案,试图从依赖离散 token 建模音频走向利用连续表征(continuous token)的新范式,结合自回归 LLM 生成与扩散/流匹配模型,既能保持 LLM 因果建模的优势,又引入扩散/流匹配方法,生成连续语音片段、降低建模的帧率。这一范式已在多篇最新研究工作中得到验证:此类模型普遍展现出更高的语音保真度、更低的生成延迟,主流的离散 tokenizer + LLM 路线可能正在受到挑战。
为避免篇幅过长,本文简要总结一些「连续表征」方案相关的论文/开源工作,主要介绍核心思想。本文第三和第四部分则是自己一些不成熟的想法,欢迎大家交流讨论~
一、相关背景
近年来,语音合成(Text-to-Speech, TTS)领域出现了将大语言模型技术用于音频生成的趋势。早期工作如 VALL-E 等通过离散语音 token(由神经编码器量化后的语音片段)进行自回归生成,在零样本(zero-shot)语音克隆等任务上取得突破。然而离散化也带来了固有问题:
1. 为了降低码率而压缩语音,离散表示需要在码率和保真度间权衡,不可避免损失细节信息。
2. 高质量重建往往意味着更长的 token 序列,与 LLM 模型配合下,导致推理延迟显著增加。
3. 离散 token 的训练通常依赖复杂的多阶段流程(先训练编码器/解码器,再训练语言模型),训练过程中还要克服量化 VQ 带来的一些问题。
最近一年,部分大佬团队开始「回归」连续表征的语音生成范式,希望直接在连续空间中生成语音特征,从根本上避免VQ 的损耗。为了在连续空间建模语音的丰富细节,新的技术方案应运而生,特别是自回归 Transformer 与扩散模型(Diffusion)或流匹配(flow matching)的结合——在这一新范式下,模型以连续表征(如梅尔频谱或编码器隐向量、VAE Latents)为基本单元进行生成,通过扩散模型或流匹配方法处理连续概率分布,从而既保留高保真度又保证生成效率。
下面按照大致时间顺序介绍本方向最新的一系列研究工作,以及这种连续表征范式相较传统离散 token + LLM 方法的优缺点及未来展望。
二、「自回归 × 扩散/流匹配」在 TTS 中的应用
1. [AR-DiT] Autoregressive Diffusion Transformer for Text-to-Speech Synthesis
- 论文链接:HTTPS://arxiv.org/pdf/2406.05551
- demo:https://ardit-tts.github.io/
- 时间及机构:2024 年 6 月,香港中文大学(深圳)
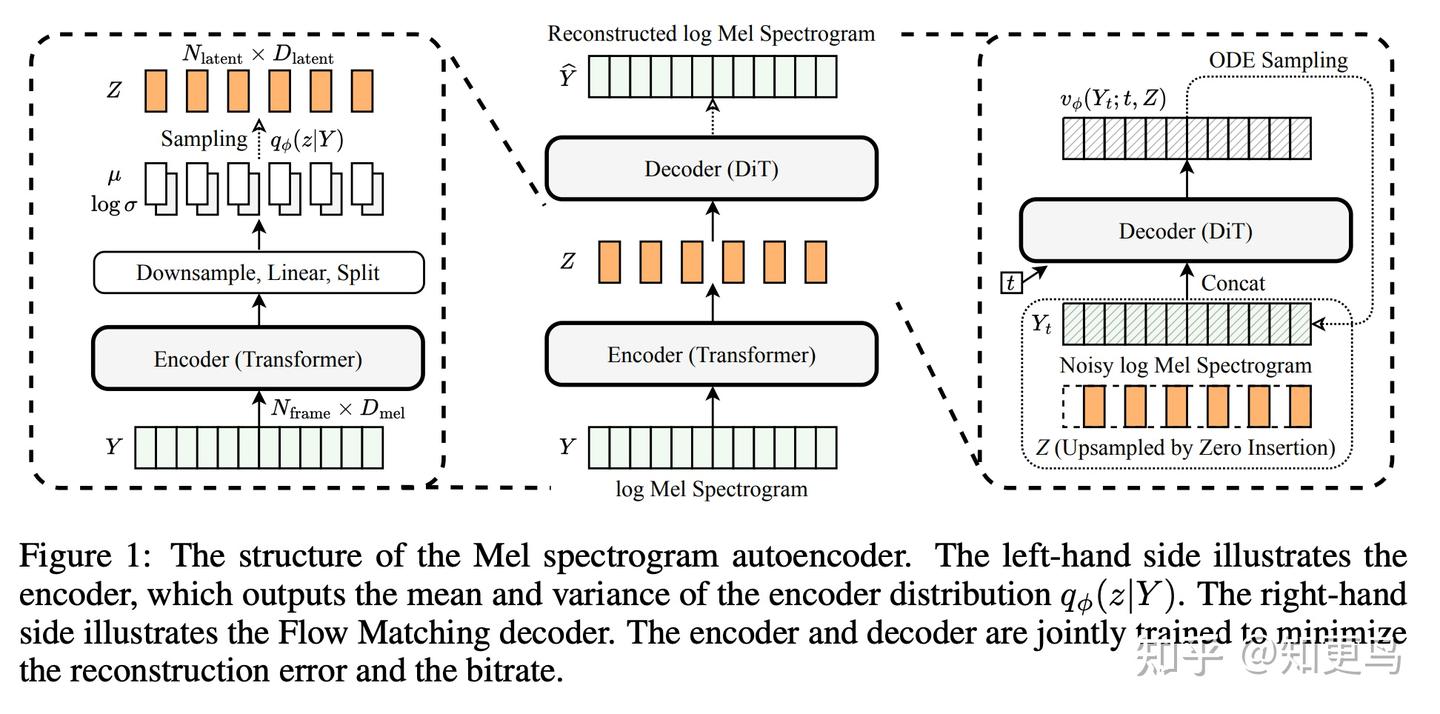
连续表征方式:如上图所示,论文在 24kHz 语音的对数梅尔特征 log_mel 基础上,使用 Transfomer Encoder + 4 倍下采样网络,将特征降低至 23.5Hz 帧率(24000/256/4≈23.5,其中 256 是梅尔特征计算时的 hop size),将压缩后的表征称为 continuous token。值得注意的是,Decoder 采用的是 DiT 结构配合 Flow Matching 学习目标,在解码阶段,即可使用 ODE Sampler,逐步从预测得到的 latent z 来恢复出梅尔特征。
核心方法: AR-DiT (Autoregressive Diffusion Transformer )提出了自回归的DiT架构,直接在连续空间(continuous token)生成语音,避免了离散 token 的信息损耗,相比于传统离散 token 的 LLM 建模,主要区别在于模型预测的目标(损失函数的设计)——基于文本 text 和历史的 continuous token,来预测下一个 block 的 continous token 的分布。
概念区分
在 AR-DiT(自回归 + Diffusion/Flow Matching)包括下文的所有模型中,“时间”有两个不同层次的含义:
1. 序列层面的时间步(Sequence-level time step)
这是 LLM 模式下常说的“next token / next step”,也就是在时间上生成 token 的过程。它决定了模型在“序列维度”上的生成节奏——比如第一个帧、第二个帧,或第一个语音 patch、第二个 patch。
2. 连续层面的时间变量(Continuous-time variable)
这是扩散或流匹配模型中引入的连续时间变量,一般,用于建模从噪声到真实数据的分布变化,推理时往往需要多次采样来得到更好的效果。 以上两个概念实际上一般不会搞混,但此处提到这个差异,主要是因为二者的优化思路是完全不同的。比如从加快推理速度的角度来考虑两种方案:
- 连续时间维度的采样次数 → 可通过蒸馏或采样策略优化;
- 序列维度的生成步数 → 则是通过降低帧率(如 25Hz→12.5Hz)或采用 chunk/patch-level 建模来压缩。
训练策略:在训练方法上,通过设计下图中 block 之间和 block 内的 attention mask,使得模型可以并行训练,保证了训练的高效性。此外,模型还采用 Distribution Matching Distillation(DMD,分布匹配蒸馏法),将多步采样过程压缩为单步,从而极大加速了推理速度。AR-DiT 可以在单步内预测多个 continuous token,进一步降低生成时延。
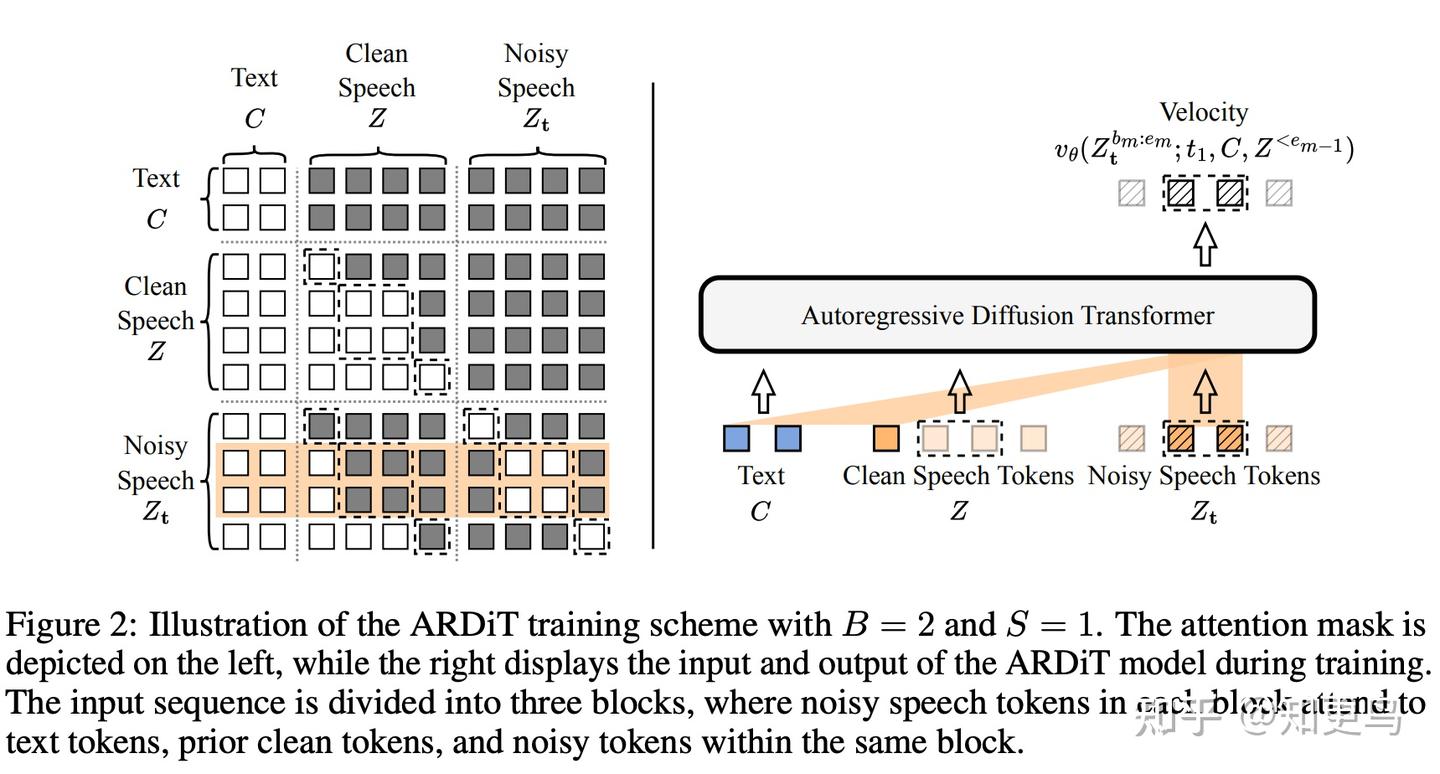
关键创新: 1)高比特率的连续表征:使用高保真度的连续特征,使模型几乎能够无损重建原始语音,实现了近乎完美的语音编辑能力;2)扩散模型蒸馏:将迭代扩散采样简化为单步,显著提升了生成质量和效率;3)多向量并行预测:一次生成多个帧的特征,显著降低推理延迟。AR-DiT 在零样本 TTS 任务中表现出色,语音自然度和相似度达到或超过当时的最新模型。连续高码率表示带来了近乎完美的重构能力,实验中模型在语音编辑等场景下取得了几乎无可挑剔的效果。
目标应用: AR-DiT 针对零样本语音克隆、语音编辑等高要求应用,提供了高保真且高效的生成范式,为无需离散 token 的通用语音语言模型奠定了基础。
2. [MELLE] Autoregressive Speech Synthesis without Vector Quantization
- 论文链接:HTTPS://arxiv.org/pdf/2407.08551
- demo:https://www.microsoft.com/en-us/research/project/vall-e-x/melle/
- 时间及机构:2024 年 7 月,香港中文大学 & 微软
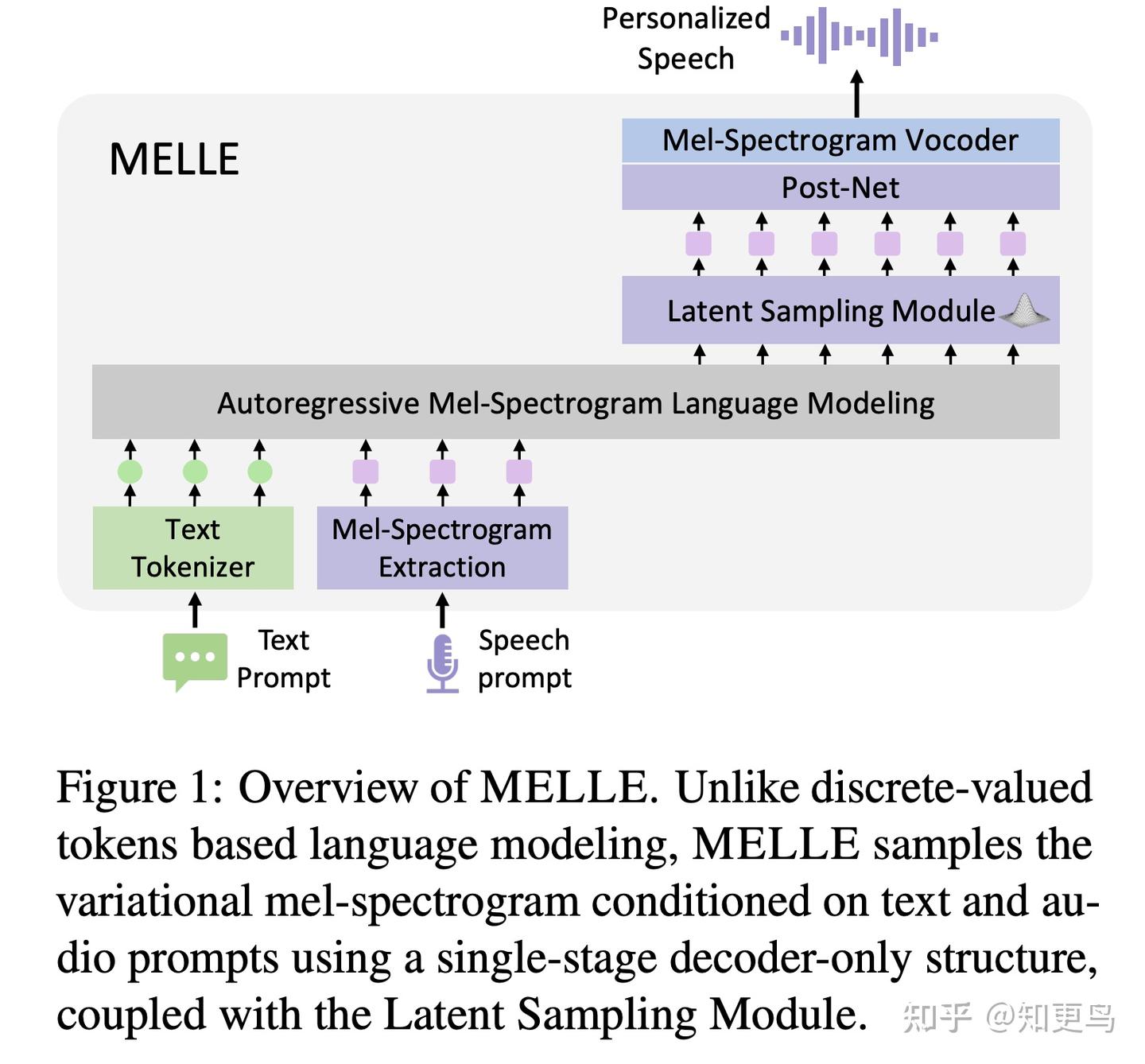
核心方法: MELLE 提出了一种无向量量化的自回归语音合成框架,此处直接以连续梅尔频谱帧作为语言模型的建模单位。它摒弃了为压缩音频而设计的离散 VQ,注意并没有使用 VAE Latents 表征,而是“一次性”地自回归生成高质量梅尔谱,直接从文本到语音、无需两阶段预测流程,非常简洁。
训练策略:在训练目标上,MELLE 除了最基础的 L1 + L2 + KL 散度三种损失函数外,还额外设计了光谱通量回归损失(spectrogram flux loss)来直接拟合连续值梅尔谱的分布。同时,引入变分推断(VI)机制来增强采样的多样性和模型鲁棒性,可以理解成类似于 LLM 离散建模方案下的某种采样策略。
关键改进: MELLE 一方面简化了 TTS 范式——从以往“先码本离散再语言模型”改为单阶段连续生成,避免了离散采样的缺陷;另一方面,通过新损失函数和变分推断,使模型兼顾稳定性与多样性。论文在实验中将 MELLE 与两阶段的离散 codec 模型(如 VALL-E 系列)对比,发现 MELLE 有效避免了离散码采样的固有问题,显著提升了多项评测指标上的性能,在自然度和鲁棒性上均优于 VALL-E 及其变体。
创新点: 1)连续 token 语言模型: 不生成离散 token,直接生成梅尔谱帧,保留了完整的频谱细节;2)光谱通量损失: 用于连续回归的定制损失,更准确刻画梅尔谱变化,提高合成质量;3)变分采样机制: 提升输出的多样性与稳健性;4)单阶段架构: 避免了离散两阶段带来的复杂度和错误传播,提供了更流畅的合成流程。
3. [SALAD] Continuous Speech Synthesis using per-token Latent Diffusion
- 论文链接:HTTPS://arxiv.org/pdf/2410.16048
- demo:https://s3.us-south.objectstorage.softlayer.net/zk-wav-data/Webpages/ICLR2025PerTokenLatentDiffusion/index.html
- 时间及机构:2024 年 10 月,IBM 研究院
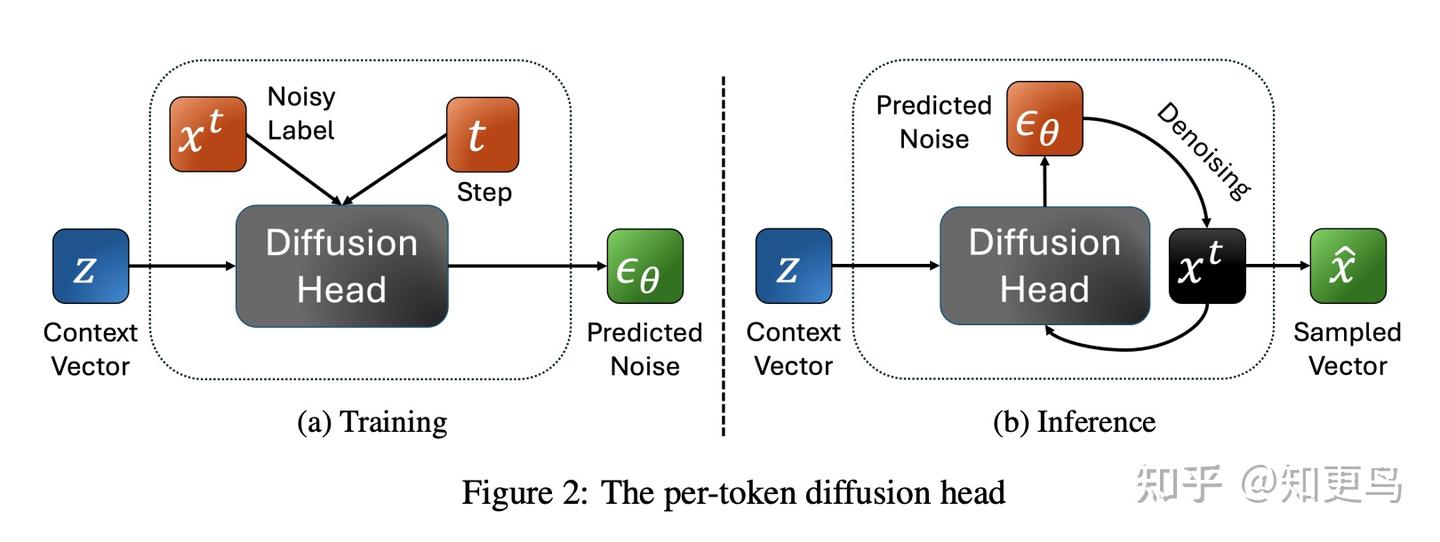
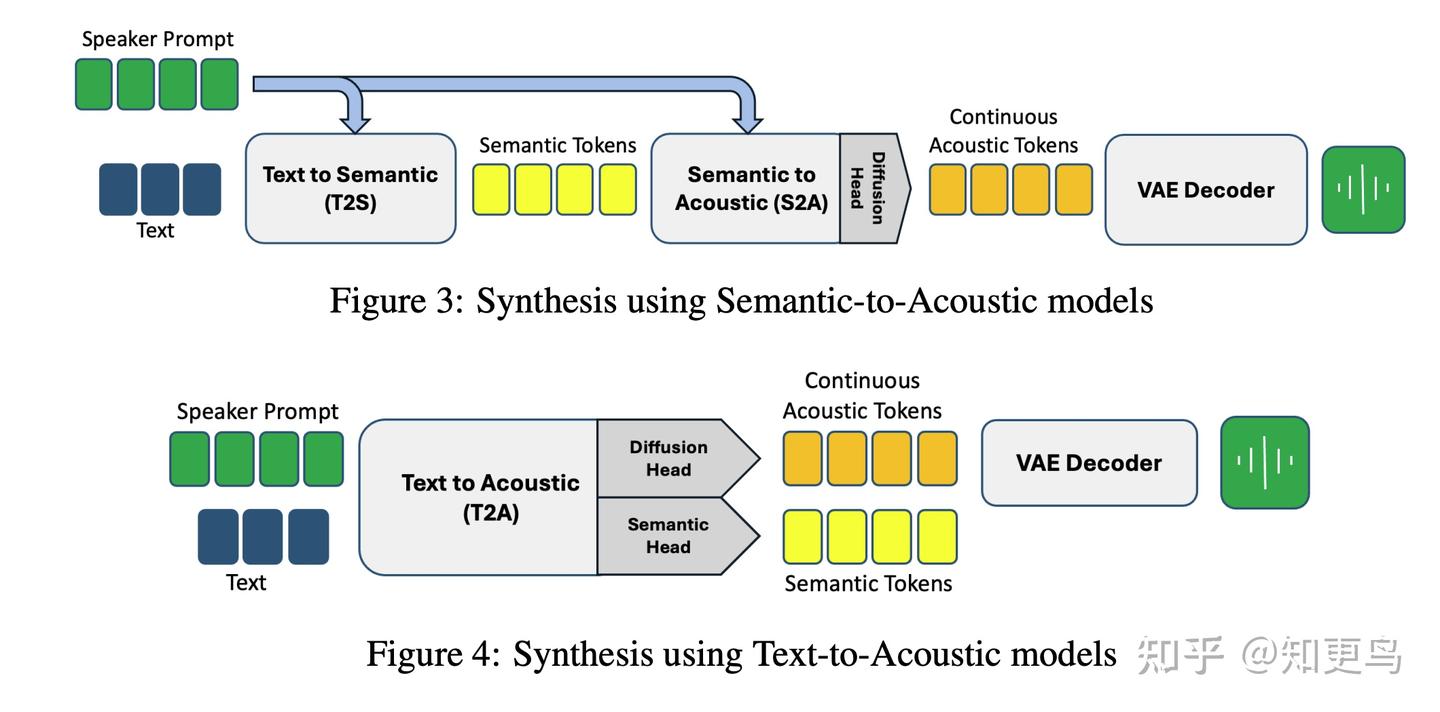
核心方法: SALAD 的灵感来自何凯明大佬在图像生成论文(https://arxiv.org/pdf/2406.11838)中的“per token diffusion head”技术,引入了逐 token 的 LDM 扩散模型用于零样本语音合成。不同于以离散 token 序列建模,SALAD 直接对连续语音表征进行扩散生成,SALAD 将其扩展用于可变长度的语音序列生成。
具体做法是:首先使用语义 token(来自预训练音频模型的高层表示)为 TTS 提供语义条件和终止判断;然后设计了三种变体方法,将现有离散 TTS 技巧扩展到连续表征情况,并分别实现对应的离散基线进行对比。
关键工作: SALAD 在同一框架下对比了连续和离散语音建模,对每种连续方案都设计了对应的离散 baseline。实验结果表明,两种方案都能生成高质量语音,但连续方案在可懂度(intelligibility)上略胜一筹,同时语音质量和说话人相似度等指标与原声基本持平。这说明在保证音质的前提下,连续表示可以带来更好的内容保真度。
创新点: 1)逐 token 扩散(per token diffusion):粒度达到每个语音隐 token,用扩散模型捕捉细粒度变化;2)语义引导:利用高层语义 token 指导生成,解决纯连续生成缺乏文本关联的问题;3)连续-离散对比分析:首次全面比较连续/离散 TTS 方案性能,这也是语音生成经常讨论的技术要点之一,也算是提供了一些参考经验。
4. [Cont-SPT] Continuous Speech Tokenizer in Text To Speech
- 论文链接:HTTPS://arxiv.org/pdf/2410.17081
- 开源:https://github.com/Yixing-Li/Continuous-Speech-Tokenizer
- 时间及机构:2024 年 10 月,腾讯 & 香港中文大学
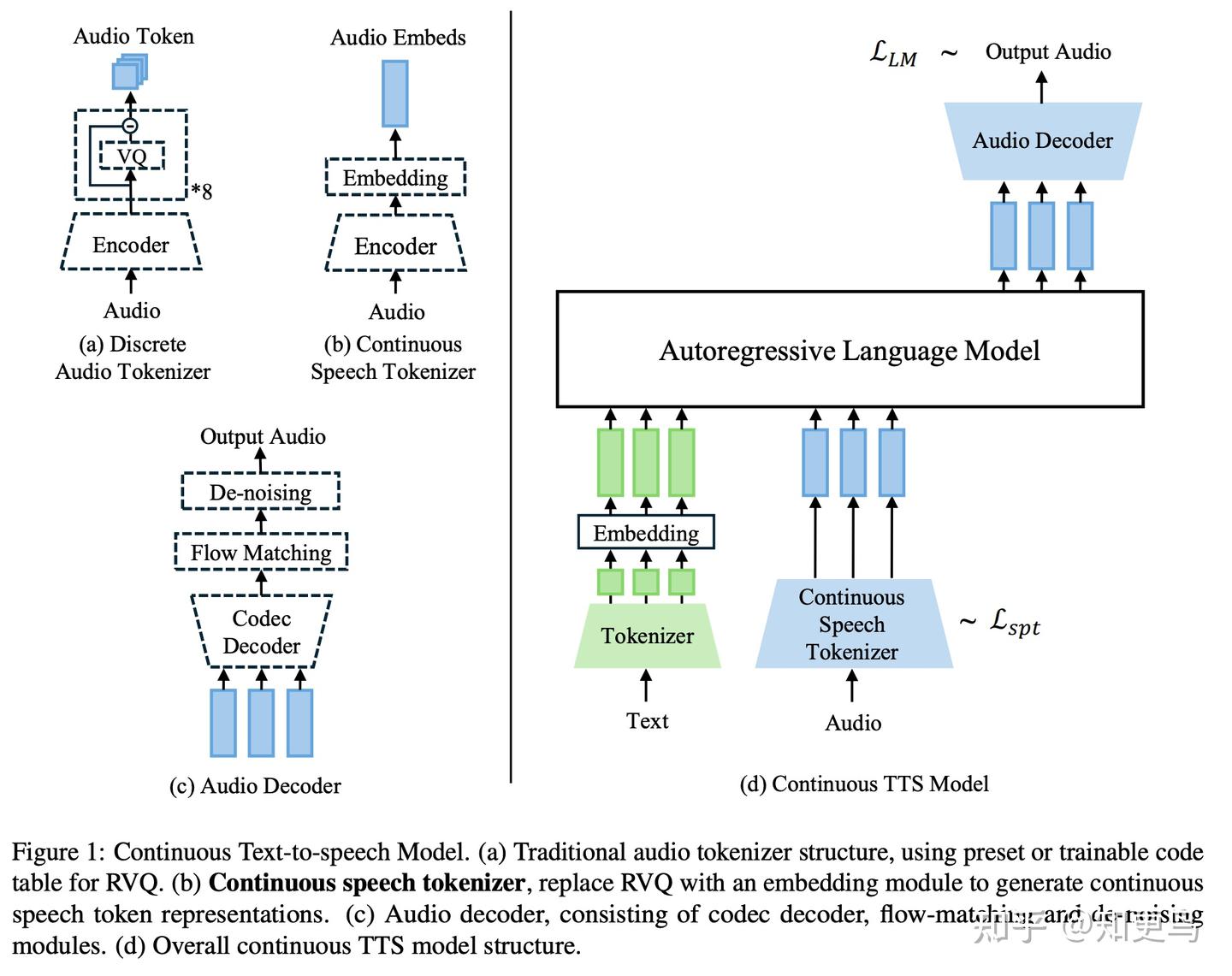
核心方法: Cont-SPT 提出了一种 Continuous Speech Tokenizer,通过一个语音编码器将音频表示为连续向量序列,此处设计和 AR-DiT 基本一致,Decoder 通过 Flow Matching 恢复语音,尽可能保留原始信息,
自回归LM 则基于这些连续表征进行训练和推断,实验结果显示,基于连续 token 在合成语音的连贯性和平均意见得分(MOS)上均优于离散 token 方案。论文分析认为,连续表示在低频和高频细节上都有更好的信息保留度,从而提高了音质和自然度。
关键工作: 1)提出 Cont-SPT 连续 tokenizer,以简单高效的方式获得连续语音表示,解决离散 token 信息缺失的问题;2)构建了连续 token 的 TTS 模型,并提供完整的训练框架,验证其可行性;3)通过频域分析,证明连续分词器在全频段上信息保留率更高,使生成的语音在不同采样率下都更具鲁棒性。
创新点: 1) 信息无损压缩:Cont-SPT 编码器在压缩语音长度的同时尽量减少失真,使语言模型获得更完整的声学信息;2) 端到端训练:模型可直接以连续向量为桥梁联合优化,实现文本到语音的端到端映射;3) 简单高效:连续 tokenzier 结构更简洁(据论文所述参数量小),为后续大模型融合语音提供了便利。
5. [KALL-E] Autoregressive Speech Synthesis with Next-Distribution Prediction
- 论文链接:HTTPS://arxiv.org/pdf/2412.16846
- 开源:https://github.com/xkx-hub/KALL-E
- 时间及机构:2024 年 12 月,西北工业大学
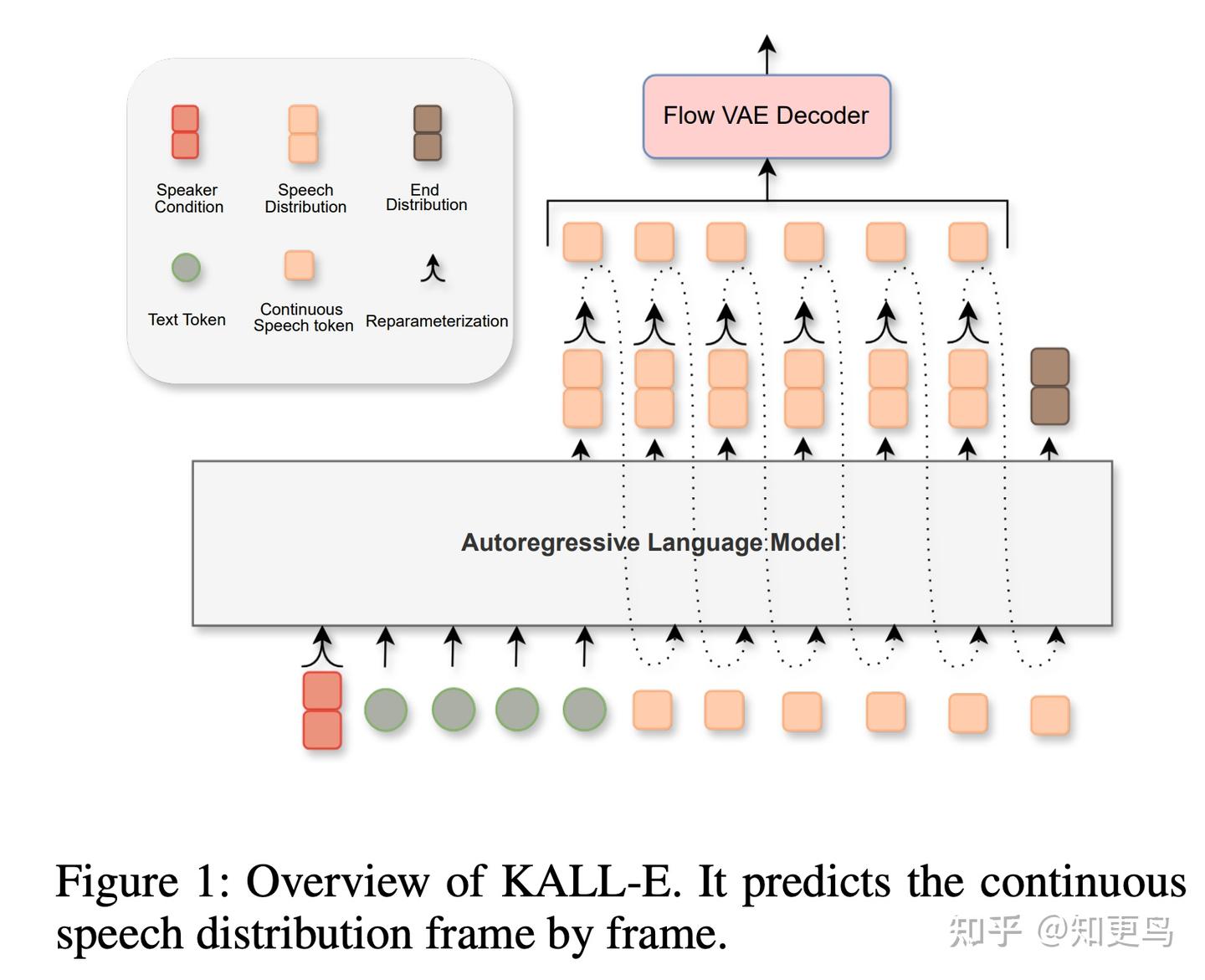
核心方法: KALL-E 是一款新的自回归语音合成模型,其显著特点在于预测下一个连续分布(而非确定的下一个帧值)。论文使用 Flow-VAE 对音频训练出连续表征(替代离散 token),然后训练单一 AR Transformer 根据文本预测下一帧的概率分布。
具体来说,Flow-VAE 编码器将波形映射为高斯分布参数(均值和方差),解码器能从该分布重构波形;AR Transformer 则以 KL 散度为损失函数,逐步预测下一个连续潜向量的分布。这种方法通过LM直接建模连续语音表征。由于每一步输出的是分布,采样时可通过重参数化获得多样化的输出。
关键工作: KALL-E 取消了 VQ 和扩散模型,以更直接有效的方式利用连续表示进行 TTS。它引入的 WaveVAE 模块能够自适应地提取语音分布,结合 Transformer 的自回归预测,实现了扩散模型蒸馏到 AR 模型的效果。实验表明,KALL-E 在语音合成质量上优于诸多现有模型。
模型创新点: 1)下一分布预测:相较传统预测下一个具体值,预测分布能表达不确定性,利于提升自然度和多样性;2)Flow-VAE 连续编码:通过流式 VAE 高效压缩语音至连续潜在空间,并保留可控的分布信息;3)单阶段训练:将 VAE 编码与 AR 预测融合训练,简化了流水线,提升一致性。4)KL 散度损失:以 KL 散度替代交叉熵,使模型直接学得连续分布,训练更稳定。
6. [DiTAR] Diffusion Transformer Autoregressive Modeling for Speech Generation
- 论文链接:HTTPS://arxiv.org/pdf/2502.03930
- demo:Demo page of DiTAR
- 时间及机构:2025 年 2 月,字节跳动-豆包 ⭐️ (重点论文)
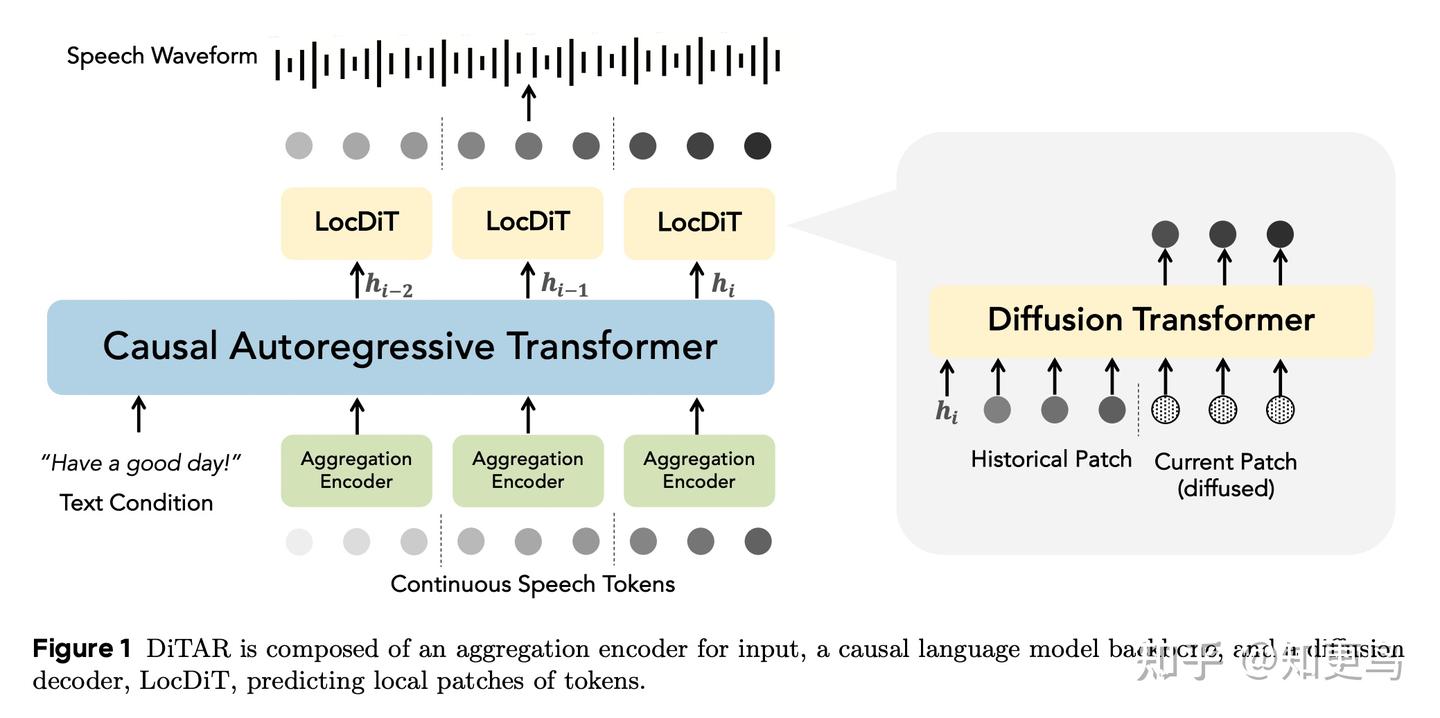
核心方法: DiTAR 提出了 LocDiT + LLM 的自回归建模框架,以分块序列的方式生成连续语音。模型由语言模型 和 LocDiT 组成,采用“分而治之”策略:将语音表示序列划分为若干 patch,语言模型先对前面已生成的 patch 通过 Aggregation Encoder 降低帧率(实际功能就是合并 token 进行下采样),并输出 patch embedding;DiT 接着基于该 embedding 生成下一个 patch。
这种设计使每个 patch 内部可通过扩散并行生成多个帧,而 patch 与 patch 之间通过 AR 顺序保证全局连贯。为平衡生成多样性和确定性,论文还在推理时还引入了一个“温度”参数,控制输出随机性。此外,论文通过大规模实验展示了 DiTAR 在模型规模扩展上的卓越效果。
关键工作: 1)分块+扩散:把长语音序列拆成 patch 处理,每块内部用 LocDiT 生成,高效且保真;2)AR+并行结合:patch 间自回归确保整体一致性,patch 内并行扩散提高速度;3)温度控制:通过调整扩散噪声注入时刻,允许用户在音质稳定和生成多样之间调节。实验表明,在零样本语音生成中,DiTAR 的鲁棒性、说话人相似度和自然度等指标达到当前最佳。该模型已被 ICML 2025 接收,可见其技术路线已经获得了学界认可,已经在实践落地中。
模型创新点:Patch 级别自回归:将长序列预测转化为较短单元的预测任务,使 Transformer 对长上下文处理更高效;块内扩散:在每个 patch 内用扩散模型处理细节,实现快慢过程分离、各擅其长;可扩展性:论文对模型进行了规模扩展的实验,结果证明 DiTAR 在更大模型/数据下表现持续提升,没有明显瓶颈。
目标应用: DiTAR 特别适合长内容语音合成(如有声书、播客)和多说话人场景。其 patch 机制支持极长上下文(论文提及 64k 长度的对话情景),可一次生成数十分钟的多轮对话内容而保持角色音色和对话语气连贯。此外,通过温度调整,它也能用于可控风格合成:在需要更保守或更创造性的语音输出时进行平衡。
7. [[FELLE] Autoregressive Speech Synthesis with Token-Wise Coarse-to-Fine Flow Matching
- 论文链接:HTTPS://arxiv.org/pdf/2502.11128
- demo:https://felle-demo.github.io/
- 时间及机构:2025 年 2 月,南开大学 & 微软
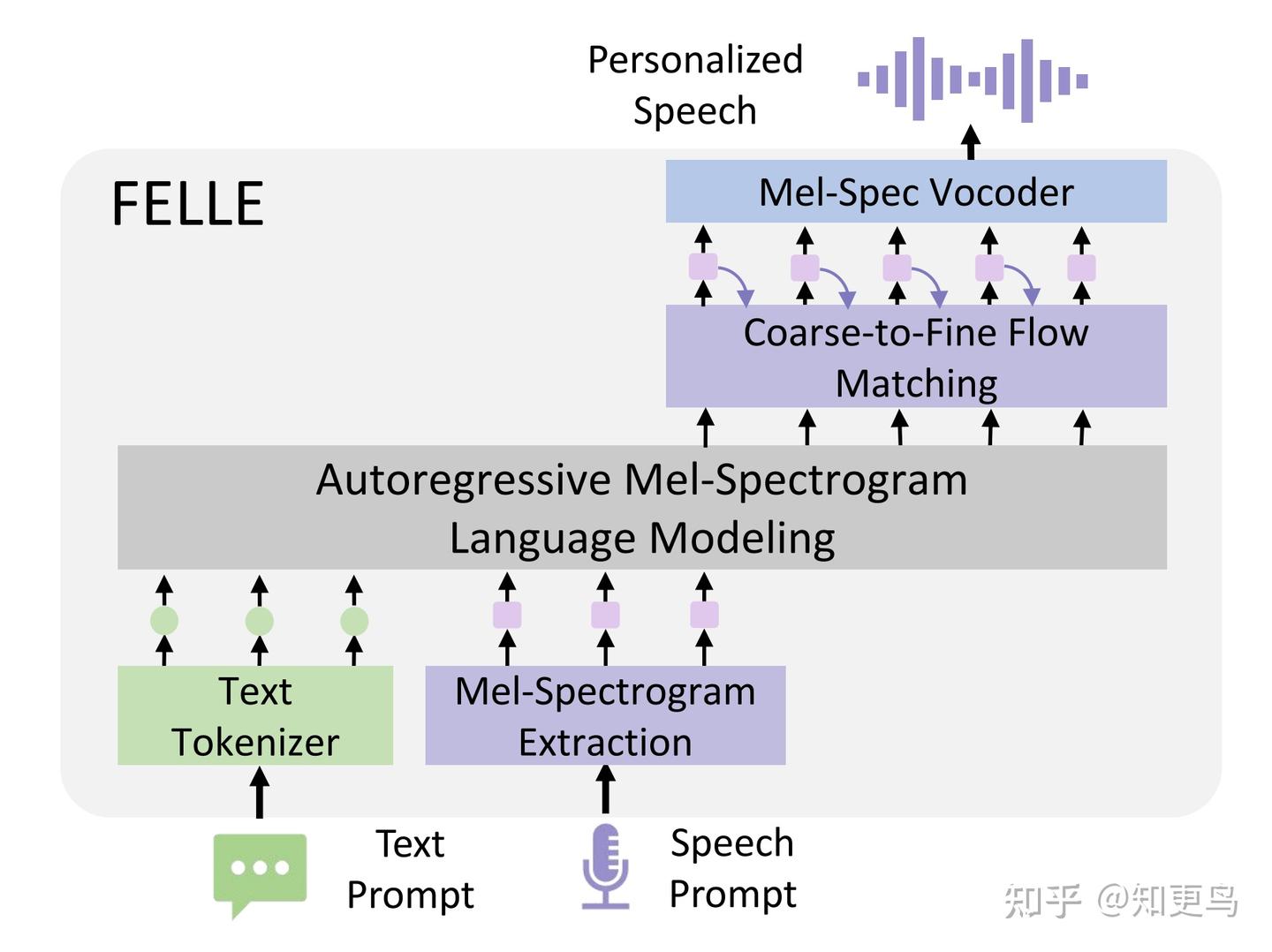
核心方法: FELLE 和 MELLE 方案非常相似,自回归逐帧预测梅尔特征。不同的是,为了提升时序一致性和生成质量,FELLE 针对每个连续 token 引入动态先验机制:即在流匹配过程中,将前一步已生成的谱帧作为当前帧的高斯先验分布的中心。这样每一步生成都参考了上一步结果,保证了谱帧之间的平滑衔接和稳定性。
进一步地,FELLE 提出了从粗粒度到细粒度的流匹配(C2F-FM)模块,将每帧的生成分成粗略和精细两个阶段:先低分辨率粗生成,再进行精细化的还原。这一两阶段机制帮助模型捕捉梅尔谱的时频相关结构,提高了合成音频的细节保真度。
关键工作: 1)token 级流匹配:不同于以往全局流,FELLE 在每个自回归步使用流匹配生成当前帧,使分布预测更灵活准确;2)动态先验:每帧的生成先验由前一帧输出确定,实现了时序信息的显式建模,增强了长时依赖的保持;3)粗到细生成:先粗后细的分层生成策略确保既有全局结构又有局部细节;4)多重损失设计:包含条件损失、粗细分辨率损失和停止符预测损失等,保障模型从各方面优化。
实验在 LibriSpeech 数据集上显示,与同时期的 MELLE 等模型相比,FELLE 在字词错误率(WER)降低、相似度提升等多个指标上都有显著优势。特别是在语音连贯性和跨句一致性方面,FELLE 表现优秀,凸显其高保真长文本合成潜力。
模型创新点: 动态先验融入上下文:每步根据上一帧调整先验,使模型生成更稳定不发散;C2F 分阶段:借鉴图像领域粗到细思想,提升声谱细节品质。
8. [SMLLE] Zero-Shot Streaming Text to Speech Synthesis with Transducer and Auto-Regressive Modeling
- 论文链接:HTTPS://arxiv.org/pdf/2505.19669
- demo:SMLLE Demos
- 时间及机构:2025 年 5 月,微软 & 上海交通大学
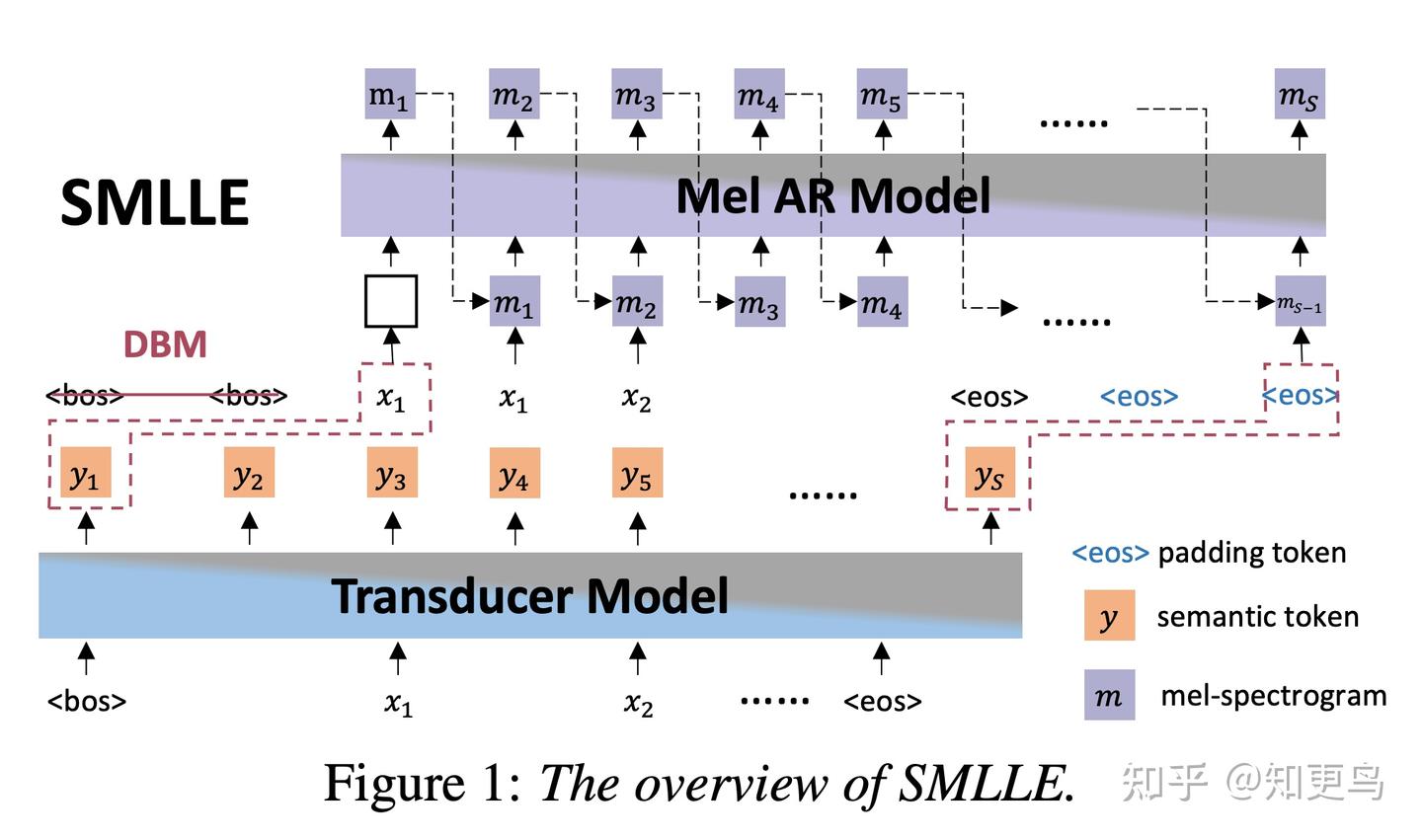
核心方法: SMLLE 提出了一种针对实时流式零样本 TTS 的解决方案,将 RNNT(Transducer)模型与自回归 TTS 结合,做到逐字流式生成高质量语音。系统分两部分:第一部分,Transducer 根据输入文本实时输出语义 token 流并同步获得对齐的发音持续时间信息,这些语义 token 类似于高层次的内容表示。
第二部分是一个完全自回归的模型逐帧生成梅尔谱,这部分类似于本文讨论的连续表征的自回归模型,建模采用的是 MELLE 相同的损失函数,输入条件是 Transducer 输出的语义 token。为了解决严格流式下看不到未来文本的问题,论文设计了“Delete
关键工作: SMLLE 克服了传统流式 TTS 需要 look-ahead 造成高延迟的难题。Transducer 模块的引入使系统在不牺牲未来文本的情况下获得语速和停顿信息;同时 Delete
模型创新点: 1)Transducer+AR 组合:Transducer 负责即时字符到语义转换,AR 模型负责语音生成,两者无缝衔接保证实时性和高质;2)显式对齐:Transducer 输出对齐信息,让 AR 模型准确把握每个语音帧应对应的文本长度,避免播放时长与文本错配;3)Delete
9. [StreamMel] Real-Time Zero-shot Text-to-Speech via Interleaved Continuous Autoregressive Modeling
- 论文链接:HTTPS://arxiv.org/pdf/2506.12570
- demo:StreamMel
- 时间及机构:2025 年 6 月,微软 & 上海交通大学
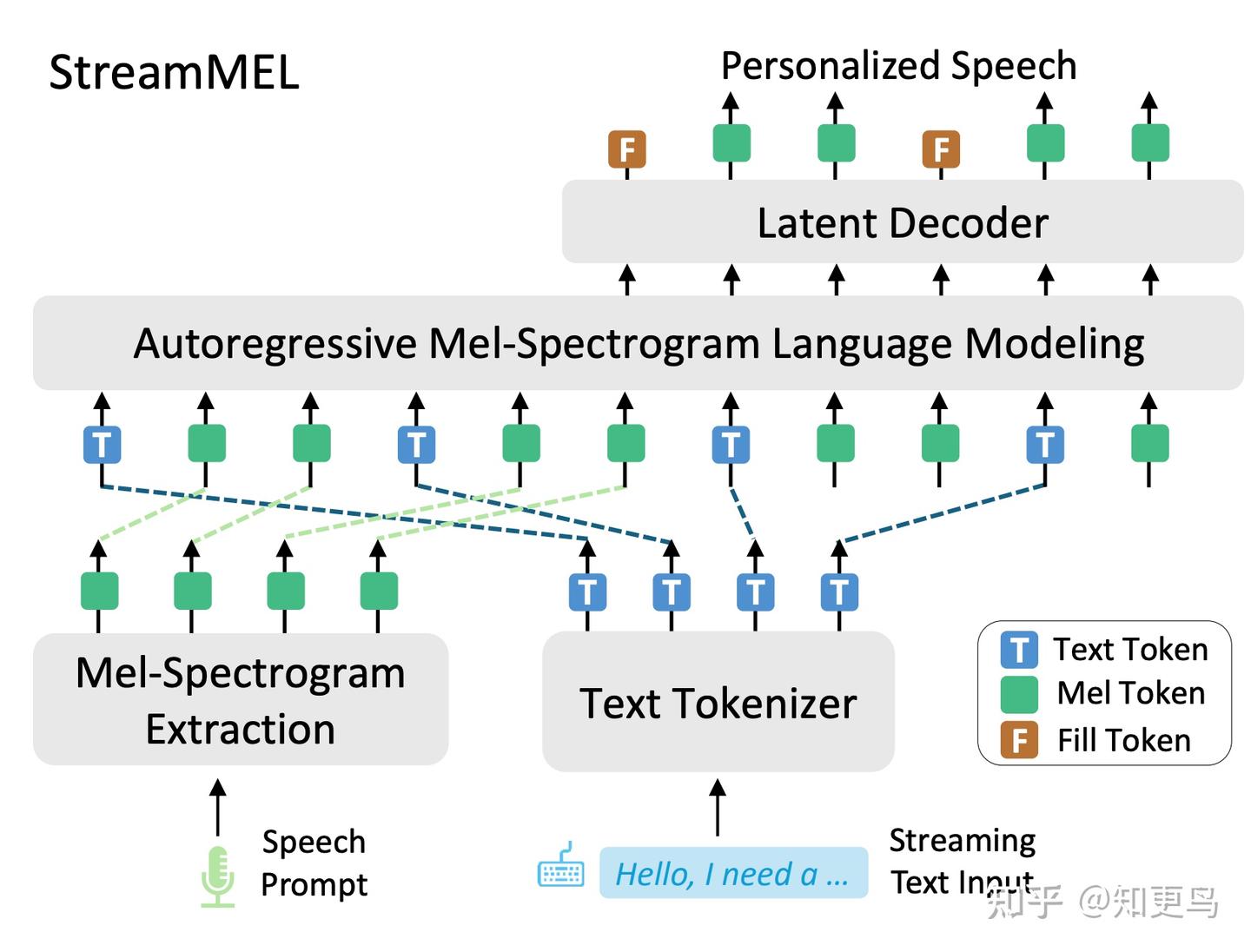
核心方法: StreamMel 是一种单阶段的流式零样本 TTS 框架,特点在于采用了文本和 Mel 特征进行 Interleave 交替输入的连续自回归建模的新范式。与 SMLLE 的两阶段方案不同,StreamMel 将文本 token 和声学梅尔特征交替地插入同一序列,由一个大型 Transformer 在同一时间步同时处理文本和语音信息。
模型在每个时间步输出下一帧的梅尔,同时接受一部分新的文本 token,实现文本和语音的同步生成。这种交叉序列设计使得模型天然具备流式能力:文本一边输入一边被转换为语音帧,不需要等待整个句子结束。此外,论文让模型直接生成连续梅尔谱特征,避免了离散表示和多阶段流水线,从而降低计算开销和延迟。
关键工作: StreamMel 在低时延和高质量之间取得了新的平衡。通过 Interleave 序列的方法,它实现了单阶段端到端生成,使多余的中间步骤和不同模块间通信统统省去。实验表明,StreamMel 在 LibriSpeech 数据集上的延迟和语音质量均优于已有流式 TTS 基线,且性能可以媲美一些离线系统。
特别地,模型在说话人相似度和自然度方面,与离线模型不相上下,同时支持高效实时合成。论文还强调,StreamMel 有希望与实时语音大语言模型对接融合,为将来更强大的语音对话 AI 打下基础。
模型创新点: 1)交替序列 AR:将文本和语音帧融为一个序列交替生成,避免单独对齐步骤,实现真正的端到端同步合成;2)单模型单阶段:不再需要语音编码器或 Transducer,直接由一个 Transformer 完成所有工作,结构简洁高效;3)零样本:保留微软系列模型零样本克隆优势,一套模型应对多说话人场景无需专门调优;4)扩展性:在支持低时延的同时,依然可以拓展长文本场景(论文称达离线系统可比性能),未来可应用于长段播报甚至多轮对话。
10. [CLEAR] Continuous Latent Autoregressive Modeling for High-quality and Low-latency Speech Synthesis
- 论文链接:HTTPS://arxiv.org/pdf/2508.19098
- 时间及机构:2025 年 8 月,香港中文大学 & 华为
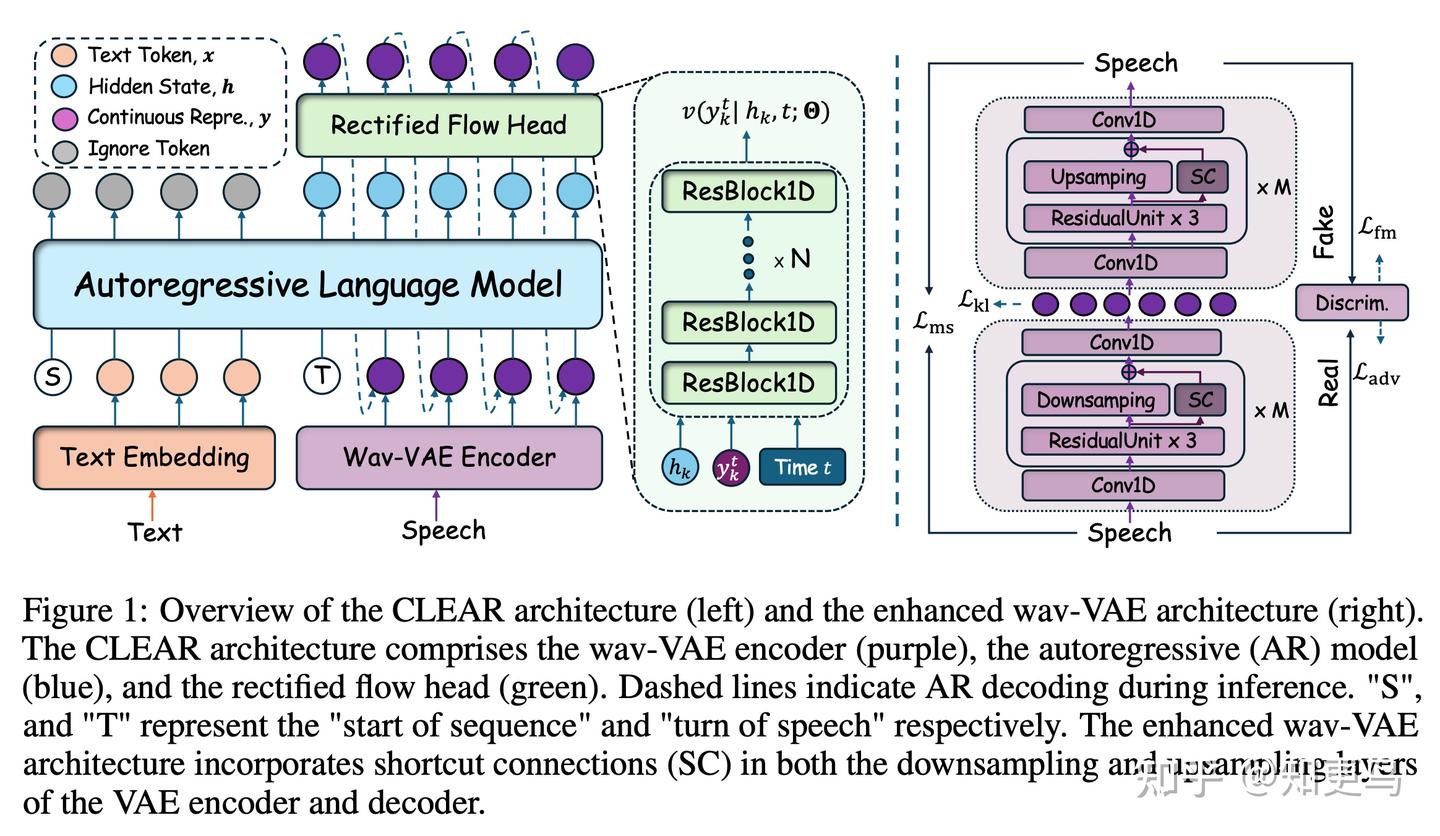
核心方法: CLEAR 提出了一种统一的连续表征的自回归零样本 TTS 框架。同样为了摆脱离散 token 压缩损失,CLEAR 首先设计了一个高压缩率的变分自编码器(VAE),带有 shortcut 的 skip-connection结构,可将原始波形映射为紧凑的连续 latents表示,这种 VAE 能在保持音质的前提下极大地降低序列长度(提升压缩比)。
论文同样使用 LLM 直接预测下一个连续表征,同时引入一个轻量级 MLP rectified-flow head 对每个 Transformer 的隐状态进行独立的分布建模,能够逐步生成音频 VAE 的连续表征。换言之,CLEAR 将一个大型 Transformer 与每步的小型 MLP 生成器结合,避免了对离散 token 的依赖。
关键工作: CLEAR 证明了不经离散压缩也能实现高质量、低延迟的 TTS。实验表明,相比类似规模的离散音频语言模型,CLEAR 在效率和保真度上都有提升。在 LibriSpeech 标准测试集上,CLEAR 达到了仅 1.88% 的字错误率(WER)和 0.29 的实时因子(RTF),远优于此前 SOTA 模型。同时,CLEAR 天生支持流式合成,首帧延迟仅 96 毫秒,且后续持续生成时保持高音质。这些成绩表明连续潜变量 AR 建模在 TTS 中具有极大潜力。
模型创新点: 1)高效连续表示:优化设计的 VAE 确保极高压缩比(官方称 80 倍于 EnCodec)同时音质几乎无损;2)rectified-flow head:独立作用于每个时间步隐状态的 MLP,进行一小步一致性变换,弥补 Transformer 直接输出连续值的不足;3)联合训练:VAE 编码器、Transformer、rectified-flow head 在一个阶段端到端优化,无需多阶段配合;4)流式方案:模型生成每帧不依赖未来帧,可流式输出,并通过特殊设计降低流式首帧延迟。
11. [VibeVoice] VibeVoice Technical Report
- 论文链接:HTTPS://arxiv.org/pdf/2508.19205
- demo:VibeVoice
- 官方开源:https://github.com/microsoft/VibeVoice
- 社区版开源(备份):https://github.com/vibevoice-community/VibeVoice/
- 时间及机构:2025 年 8 月,微软
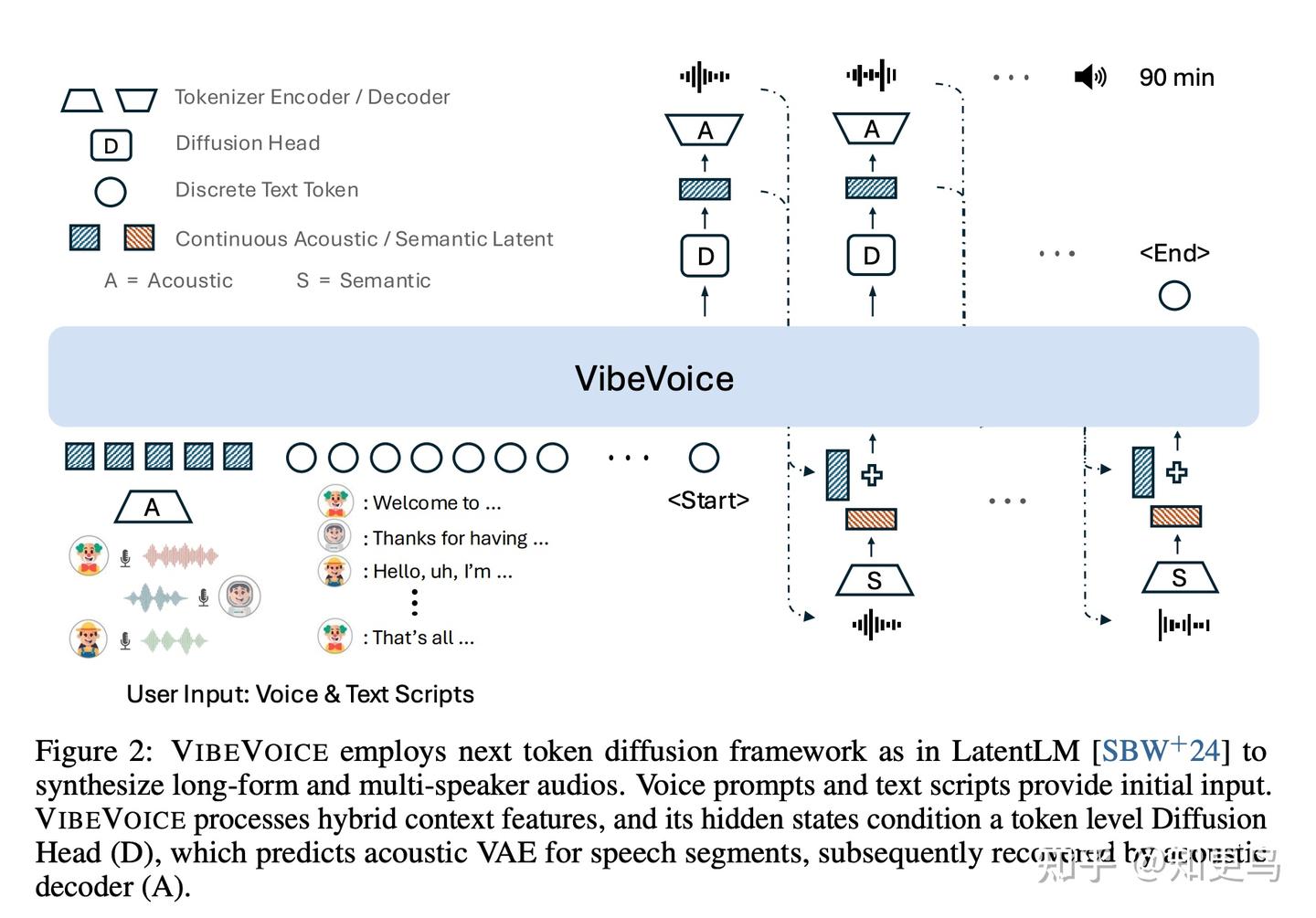
核心方法: VibeVoice 是微软推出的一种生成长篇多说话人语音的模型,同样以“next-token diffusion”技术为核心。模型使用了一种新颖的连续语音 tokenizer:相比流行的 EnCodec,其数据压缩能力提高了 80 倍,但音频保真度几乎不变,用极低的 token 速率表示长音频,为长段合成打下基础。
在生成阶段,同样每个时间步通过扩散模型在连续空间生成 latent,并以自回归方式推进序列。由于连续 token 密度极低,模型可以处理超长上下文(报告称支持 64k 长度上下文)。整套系统能够在 90 分钟的语音长度范围内生成包含最多 4 个说话人的对话内容,真正实现了长对话中说话人语调、语气的细腻呈现。名字“VibeVoice”也寓意捕捉对话“氛围”(vibe)的能力。
关键工作: VibeVoice 最大亮点在于解决了长对话、多说话人的生成问题,同时兼顾了音频质量和效率。其超强压缩 tokenizer 使得长达 1.5 小时的音频仅相当于短序列,对 Transformer 来说仍在可处理范围。加上 Diffusio、模型对连续数据的全局建模能力,模型可以在长对话中维持角色特点和交互节奏。
实验表明,VibeVoice 在多说话人对话合成方面超越了开源和某些专有对话模型,生成的 90 分钟播客令人难以区分真人与 AI。一篇新闻稿称其为“90 分钟播客生成器”,足见其在播客内容自动生成上的巨大突破。
模型创新点: 1)超高压缩连续 tokenizer:将数据压缩到传统的 1/80,大幅减少模型负担;2)next-token 扩散:每个 token 通过扩散模型生成,兼具 AR 的顺序性和扩散模型的高质量生成,保证长文内容的丰富性和一致性;3)多说话人对话:内建对多说话人角色的支持,可在一个上下文中灵活切换 4 种声音;4)极长上下文:将 Transformer 上下文窗口拓展到 64k,使得模型能整段剧本一次读完并自然合成整部有声内容。
目标应用: VibeVoice 针对播客、广播剧、长访谈等应用,能够自动生成长时多人对话音频。例如,给定剧本,模型可以合成数十分钟多角色有声读物,且角色间语气互动真实。未来,它可用于数字内容创作,帮助媒体生产者快速生成高质量播客;也可与聊天机器人结合,创造出具备长对话记忆和逼真声音的 AI 主播或 AI 客服。
12. [CALM] Continuous Audio Language Models
- 论文链接:HTTPS://arxiv.org/pdf/2508.19205
- demo:https://huggingface.co/spaces/kyutai/calm-samples
- 时间及机构:2025 年 8 月,Kyutai
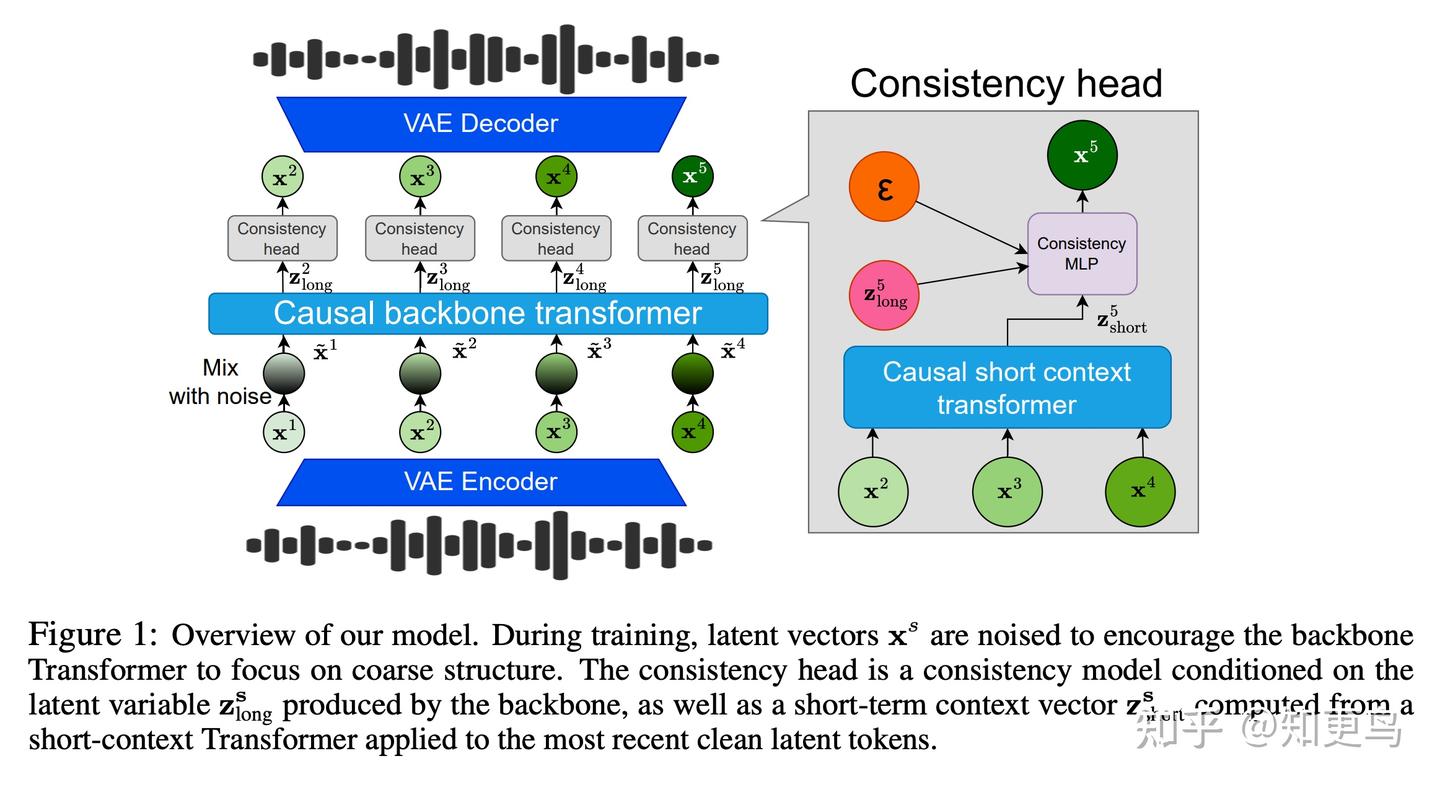
核心方法:Kyutai 团队的最新工作 CALM,提出了一种新的连续音频语言模型架构,不再依赖离散音频 token。模型由一个大型 Transformer Backbone 和 MLP 生成头组成。Transformer 每个时间步输出一个上下文嵌入,随后 MLP(一致性模型)以此嵌入为条件,生成音频 VAE 的下一帧连续向量。
这种通过一致性建模(consistency modeling)的生成方式,可以看作是对扩散模型的蒸馏,使每一步直接产生高质量帧,而无需多次迭代。由于跳过了离散 codec 压缩环节,CALM 在相同计算成本下实现了更高的音质。论文在语音和音乐数据上验证了 CALM 的优势:与现有离散音频语言模型相比,CALM 显著提高了生成效率和保真度。换言之,在达到相同音频质量时,CALM 所需的 token 更少,推理更快;若耗费相同计算量,则 CALM 生成的音频质量更佳。
关键工作: CALM 直接通过连续帧方式生成,它避免了提升质量就必须指数增加 token 数量的矛盾。同时,CALM 利用了 Audio VAE 的编解码能力,使连续帧仍可还原为高保真音频。实验中,其在语音和音乐领域都取得了比离散模型更好的效果。这说明连续音频语言模型不但可行,而且在效率和质量上都优于传统离散范式,为统一生成音乐与语音等不同类型音频铺平了道路。
模型创新点: 1)帧级语言建模:逐帧生成音频,不再将音频切成离散符号,消除了不可逆压缩损失;2)一致性生成:采用一致性模型确保一步预测高质量帧,避免扩散多步耗时,实现质量和速度兼得;3)统一语音音乐:不区分数据类型,证明了连续框架对不同音频模态的普适性;4)轻量高质:无需庞大码本,Transformer+MLP 的小巧组合即可匹敌离散大模型性能,为后续模型轻量化提供了思路。
目标应用: CALM 有望应用于通用音频生成场景。例如,一个模型既可以用来合成语音对话,又能生成音乐片段,实现多模态音频合成。其高效架构也适用于设备端部署,用于音乐伴奏生成、实时音效合成等需要高质量和低时延的场景。此外,CALM 为构建音频领域的 GPT 提供了另一条路线——通过连续表示,可以训练出同时掌握语言和声音的超大模型,在语音对话系统、AI 作曲等方向具有广阔前景。
13. [MELA-TTS] Joint transformer-diffusion model with representation alignment for speech synthesis
- 论文链接:HTTPS://arxiv.org/pdf/2509.14784
- 时间及机构:2025 年 9 月,阿里巴巴 & 东南大学
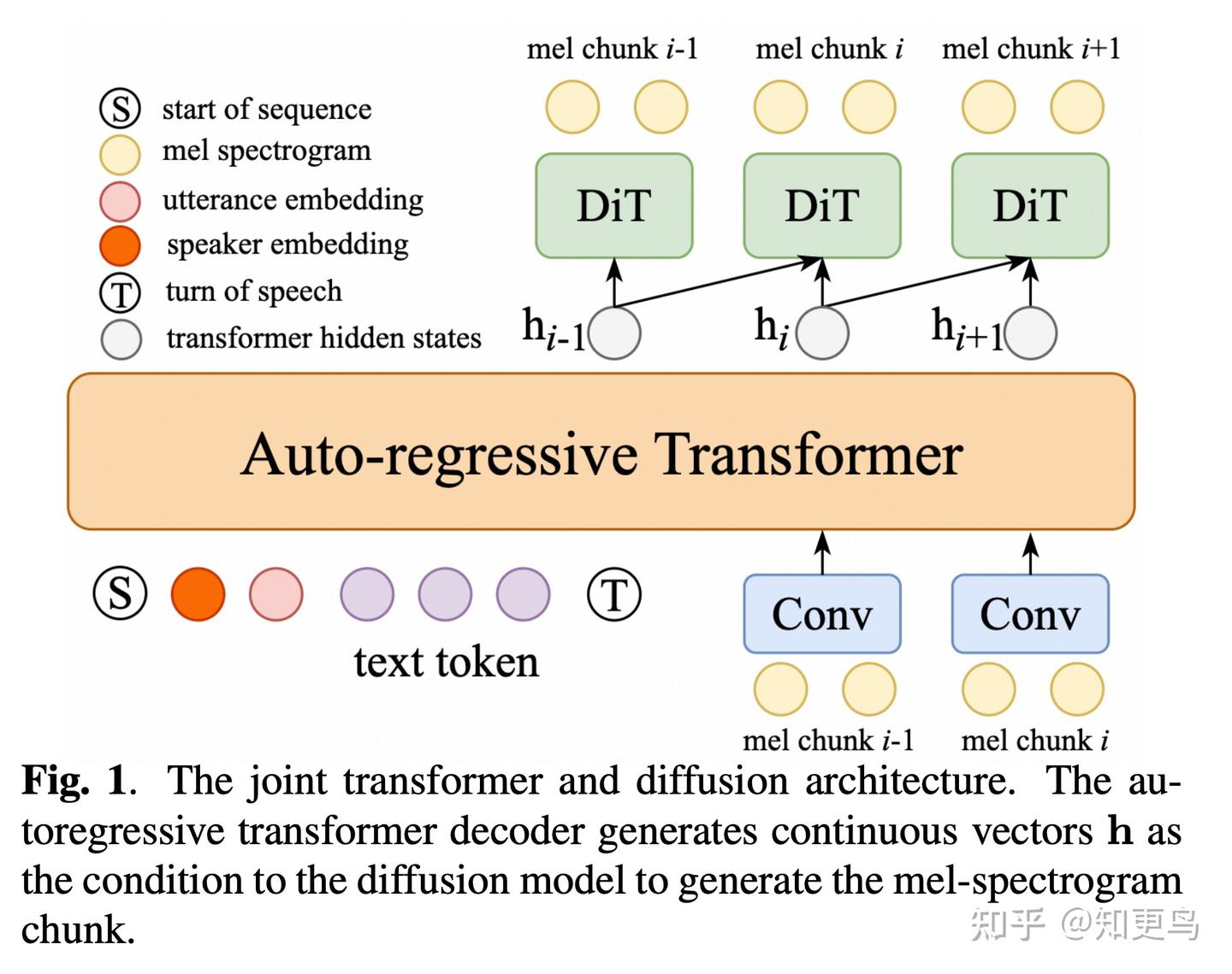
核心方法: MELA-TTS 提出了一种将 Transformer 自回归与扩散模型紧密结合的 TTS 架构。模型直接从文本和说话人条件出发,自回归地生成连续梅尔谱帧,不经过任何离散符号或多级流程。针对连续特征难以建模的问题,论文还引入了表示对齐模块:在训练过程中,将 Transformer 解码器的输出表示和预训练 ASR(自动语音识别)编码器的语义嵌入对齐。
具体而言,让 TTS 模型的中间表示去匹配一个 ASR 模型对相应语音帧的高层表示,从而强制 TTS 输出携带正确的语义信息和结构。这种对齐机制加速了模型收敛,并增强了文本域与语音域的跨模态一致性。同时,模型内部融合了噪声估计器,在自回归生成每帧时辅以噪声建模,提升了连续帧预测的稳定性。整体框架实现了端到端的一阶段训练,相比离散 token 范式极大简化,但在各项评测中取得了新的 SOTA 性能。
关键工作: MELA-TTS 在保证零样本音色克隆和支持流式/离线双模式的同时,在 MOS、WER 等多个指标上超越了以往工作。表示对齐模块功不可没,它让 TTS 生成更贴合文本语义,减少了说话不清或语义偏离的问题(ASR 嵌入相当于给 TTS 提供了“教师信号”)。此外,LLM+Diffusion 的结合提高了连续帧的预测精度和多样性,使模型在稳健性方面表现突出。综合实验结果表明,MELA-TTS 为连续特征建模提供了强有力的例证,有望成为取代离散 token 范式的有力替代。
模型创新点: 1)LLM + Diffusion融合:在每个自回归步注入扩散噪声建模,提高连续预测的可靠度和平滑度;2)语音语义对齐:首创将预训练 ASR 的特征用于指导 TTS,使合成语音在内容和韵律上都更加精准;3)一阶段端到端:无需嵌套 VAE 或两步流程,训练简单、推理高效;4)全模式支持:同一模型即可离线批量生成,又可流式逐帧输出,应用灵活。
详细解读: ARDM-TTS 专题文章
14. [VoxCPM] VoxCPM: Tokenizer-Free TTS for Context-Aware Speech Generation and True-to-Life Voice Cloning
- 论文链接:https://arxiv.org/pdf/2509.24650
- demo:VoxCPM: Tokenizer-Free TTS for Context-Aware Speech Generation and True-to-Life Voice Cloning
- 开源:HTTPS://GitHub.com/OpenBMB/VoxCPM
- 时间及机构:2025 年 9 月,面壁智能
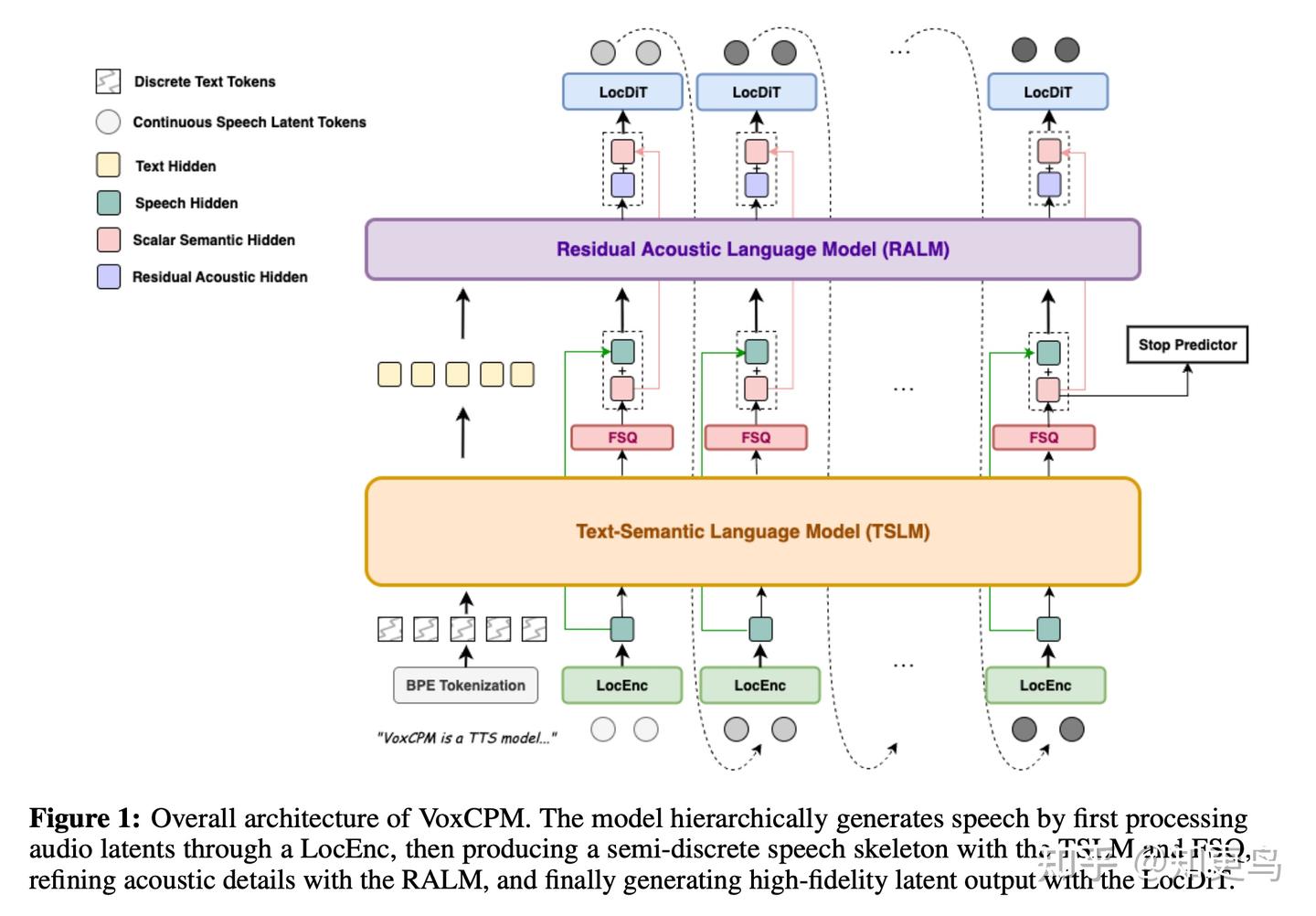
VoxCPM 是由 OpenBMB 推出的不使用离散 tokenizer 的 TTS 方案,也是采用连续表征建模:抛弃主流的离散 token 化路径,采用 扩散 + 自回归架构,直接在连续空间生成语音表征。突出的特点在于:采用了类似于 UniAudio/Moshi/FireRedTTS-2 的两个 LLM 模型,分别负责 semantic hidden 和 acoustic hidden 的生成。这部详细解读请见:ARDM-TTS 专题文章。
官方核心总结:
- 上下文感知语音生成:能理解文本上下文,自然推断韵律与语气,合成更具表现力的语音。
- 真实感语音克隆:通过一段简短的参考音频即可实现零样本克隆,捕捉音色、口音、情绪、节奏等细粒度特征。
- 高效流式合成:在消费级 RTX 4090 上的实时因子(RTF)低至 0.17,适用于实时交互场景。
- 训练规模:基于 MiniCPM-4 作为主干,训练语料达 180 万小时双语语音,增强了表达力和稳定性。
三、连续表征新范式的优缺点分析
上述工作实际都是围绕着“连续表征 + 自回归”这一新范式在进行各种改动尝试,可以看出各论文大同小异。连续表征新范式在语音生成中展现出诸多优势,但是离散方法的优势也是显而易见的:有成熟的编码器(如 EnCodec/ DAC / CosyVoice Tokenizer)、有稳定的训练范式、在过去两年推动了 CosyVoice、FireRed-TTS、Index-TTS 等工业落地。所以,下面我们从优缺点两方面对比连续表征范式与传统离散 token 方法:
连续表征的优势:
- 首先是高保真。AR-DiT、CLEAR、CALM 等直接在连续 latent 上建模,省去了 VQ 离散压缩环节,不存在码本限制,几乎摆脱了量化带来的折损,声音细节被完整保留。例如,AR-DiT 等模型利用高比特率连续向量,实现了几乎无损的重建效果。连续模型也无需像 VQ-VAE 那样担心 codebook 坍塌的问题(比如需要多种训练 VQ 的 trick 来保证 codebook 利用率和训练稳定性)。
- 其次是端到端的简化:MELLE、Cont-SPT 让我们看到不用单独 tokenizer 也能把文本直接映射到语音,架构更轻、更干净,单阶段即可训练和生成,减少了模型设计和调优的复杂度,避免了离散 token 范式中编码器-解码器失配或误差累积的问题。
- 更重要的是,连续表征方法在长语音生成上天然具备优势,VibeVoice 可以合成 90 分钟的播客,而离散方法很难撑住如此长的 token 序列。连续表示在相同质量下所需 token 帧率更低(因为每个连续帧携带的信息量更大),加上蒸馏、并行化、硬件优化的加入,推理速度并非不可解的难题,在应用落地方面具有天然的优势。
当然,「没有免费的午餐」,缺点或者难点也是有的:
- 连续表示包含的信息更加丰富,所以分布的建模难度远高于离散,简单使用均方误差(MSE)或平均绝对误差(MAE)损失会假设分布肯定过于简单,导致输出模糊或失真。需要引入扩散、流匹配、flux loss 等复杂技术来避免输出模糊,这意味着更高的算法和技巧门槛。
- 其次,离散 token 因为有预训练码本压缩,较小模型即可处理,而连续模型要直接拟合连续空间的复杂特征,参数量可能需要更大(位置)?中小型研究团队和定制场景可能难以立刻复现和使用。
- 另外,加上扩散和流匹配在推理中的时延问题,几十步迭代采样的方案几乎无法实时,需要配合蒸馏、rectified flow 或者 Consistency Models 来优化建模。相比之下,离散 AR 模型虽然帧率较高,但每步直接采样,下一个 token 生成一步到位,在同等条件下速度优势明显(当然可能音质会略差)。
- 最后,连续范式也强依赖于底层的连续表征质量。往往依赖一个高质量连续表示编码器(如 CLEAR 的 VAE、VibeVoice 的 tokenizer、Cont-SPT 的 encoder),需要良好的设计和训练,否则会影响最终合成效果——如果连续表征不能完美重构音频,那么生成模型再优秀也无济于事。连续新范式,实际把一部分难度转移到了学习可逆的连续表示上,和离散 token 本质上一样需要同样的外部编/解码模型。
四、技术展望
短短一年多里,连续表征范式已经跑出了气势,取得了不错的成果:从 AR-DiT 到 MELLE,从 VibeVoice 再到 VoxCPM,我们看到了一条不同于离散 token 的技术曲线。但如果说这已经是终点,可能还为时过早。接下来几年,这条发展曲线会走向哪里呢?以下仍然值得深入探索的方向:
第一,连续表示学习的方法改进。 连续范式很大程度上依赖底层连续表示的质量,如何在不牺牲音质的情况下进一步提高压缩效率、简化表示维度?VibeVoice 提升 EnCodec 压缩 80 倍就是一个惊人的进步,但是否还有余地?此外,可以探索跨模态的统一表示——让语音的连续表示与文本 embedding 处于同一空间或者具有直接可比性,这将有利于语音和语言模型的结合(Cont-SPT 等工作已开始在尝试)。实现语音-文本的表示对齐,将使多模态模型训练更加便利,或许哪天能看到一个 Transformer 既能处理文本 token 又能处理语音帧,实现真正意义上的 Modality-Agnostic 的“语音/音频语言模型”。
第二,模型的融合与范式统一。 目前的研究呈现出两大方向融合的趋势——即自回归语言建模与扩散/流匹配的结合,未来或许会出现更加统一的框架,将 Transformer 的长程建模能力与扩散模型的细节合成能力有机结合,形成端到端的语音和音频大模型(实际上,之前传出的 GPT-4o 图像生成能力可能也采用了类似的模型结构方案)。随着之后的发展,连续与离散、AR 与扩散模型(包括连续扩散和离散扩散)的界限,可能逐渐被模糊甚至消解。甚至有可能出现一套模型同时支持离线高质量生成和在线流式生成,只需通过调节参数或子模块即可切换,从而满足不同场景的应用需求。
第三,优化推理速度与效率。以上部分论文声称达到了实时甚至超实时速度,但这些通常是在非生产环境下得到的指标,未必考虑了部署开销。未来研究还需要着眼于模型压缩和加速推理,离散 LLM 和扩散/流匹配模型单独进行推理的部署框架已经相当成熟,但是两个模型相结合的推理方案,有可能定制化的优化还有提升空间,还比如像 StreamMel 这类交替输入文本和语音 token 的 TTS 方案,如何更好地平衡 prefill/decode 的开销及 cache 方案,都值得进一步定制化设计。
总之,连续表征驱动的语音生成远不是“取代离散 token”这么简单,有可能也不是最终的方案,但是更像是一次思路上的重构,提醒我们思考什么才是语音大模型的原生形态。最近也在不同渠道看到一些小伙伴开始有相同的思考:如何进一步简化模型设计、提高模型效率,或许也是后续大家关注的焦点。未来的下一站,或许是一个真正统一的音频大模型,能像人类一样全方面理解和生成声音。
某些新的范式,或许在加速到来。
参考文献
- [AR-DiT] Autoregressive Diffusion Transformer for Text-to-Speech Synthesis
HTTPS://arxiv.org/pdf/2406.05551 - [MELLE] MELLE: Autoregressive Speech Synthesis without Vector Quantization
HTTPS://arxiv.org/pdf/2407.08551 - [SALAD] Continuous speech synthesis using per-token latent diffusion
HTTPS://arxiv.org/pdf/2410.16048 - [Cont-SPT] Continuous Speech Tokenizer in Text To Speech
HTTPS://arxiv.org/pdf/2410.17081 - [KALL-E] KALL-E: Autoregressive Speech Synthesis with Next-Distribution Prediction
HTTPS://arxiv.org/pdf/2412.16846 - [DiTAR] DiTAR: Diffusion Transformer Autoregressive Modeling for Speech Generation
HTTPS://arxiv.org/pdf/2502.03930 - [FELLE] FELLE: Autoregressive Speech Synthesis with Token-Wise Coarse-to-Fine Flow Matching
HTTPS://arxiv.org/pdf/2502.11128 - [SMLLE] Zero-Shot Streaming Text to Speech Synthesis with Transducer and Auto-Regressive Modeling
HTTPS://arxiv.org/pdf/2505.19669 - [StreamMel] StreamMel: Real-Time Zero-shot Text-to-Speech via Interleaved Continuous Autoregressive Modeling
HTTPS://arxiv.org/pdf/2506.12570 - [CLEAR] CLEAR: Continuous Latent Autoregressive Modeling for High-quality and Low-latency Speech Synthesis
HTTPS://arxiv.org/pdf/2508.19098 - [VibeVoice] VibeVoice Technical Report
HTTPS://arxiv.org/pdf/2508.19205 - [CALM] Continuous Audio Language Models
HTTPS://arxiv.org/pdf/2509.06926 - [MELA-TTS] MELA-TTS: Joint transformer-diffusion model with representation alignment for speech synthesis
HTTPS://arxiv.org/pdf/2509.14784 - [VoxCPM] VoxCPM: Tokenizer-Free TTS for Context-Aware Speech Generation and True-to-Life Voice Cloning
HTTPS://GitHub.com/OpenBMB/VoxCPM
- 本文标题:专题分享 | 语音生成的新范式?连续表征的「自回归 × 扩散」建模
- 创建时间:2025-09-20
- 本文链接:2025/2025-09-20-ARDM-collection/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!