今天(2025年10月16日),字节跳动发布了新版的豆包2.0语音合成能力,引发广泛讨论,效果确实惊艳。
火山引擎发布新版语音合成系列模型:豆包语音合成模型2.0(Doubao-Seed-TTS 2.0)和豆包声音复刻模型2.0(Doubao-Seed-ICL 2.0),两款模型展现出更强的情感表现力、更精准的指令遵循能力,还能准确朗读复杂公式,还拓展了上下文推理和自然语言描述的控制能力,实现对情感风格变化的控制。
事实上近两年来,语音合成(Text-to-Speech, TTS)领域涌现出来自国内外的多款大模型产品。本文将简要总结语音合成方向上,八个国内外比较知名的科技公司的技术能力:
- 字节跳动
- 阿里
- MiniMax
- FishAudio
- ElevenLabs
- OpenAI
- Google Gemini
- Hume
本文整合了各公司官方宣传、接口文档以及技术论文等公开信息,仅客观体现各公司的能力丰富性和覆盖度,不具体比较某一维度能力的水平/指标高低。
总结版(对比表格)
语音合成的能力,本文大概从以下六个维度来评价/对比。
一、基础信息与音色数量
| 维度 | 模型名称 | 是否开源 | 精品音色数量 |
|---|---|---|---|
| 豆包 | SeedTTS / Mega-TTS | ❌ | 300+ |
| 阿里 | CosyVoice / Qwen-TTS | ✅ | v1/v2 数十个;v3/v3-plus 单个 |
| Minimax | Speech 01/02/2.5 | ❌ | 60+ |
| Fish Audio | OpenAudio-S1 | ✅ | 未说明 |
| ElevenLabs | v2 / v2.5 / v3 | ❌ | 20+ 高品质音色;5000+ 社区音色 |
| OpenAI | OpenAI FM | ❌ | 11 |
| Gemini 2.5-TTS (Flash/Pro) | ❌ | 30+ | |
| Hume | Octave 2 | ❌ | 未说明 |
二、声音复刻与高级合成能力
| 公司 | 声音复刻 | 指定情感/风格 | 自然语言控制 | 副语言合成 |
|---|---|---|---|---|
| 豆包 | ✅ | ✅ (可控制强度) | ✅ | ✅ |
| 阿里 | ✅ | ✅ | ✅ | ✅ |
| Minimax | ✅ | ✅ (7 种情感) | ✅ | ❌ |
| Fish Audio | ✅ | ✅ (类别多) | ❌ | ✅ |
| ElevenLabs | ✅ | ✅ (类别多) | ❌ | ✅ (类别丰富) |
| OpenAI | ❌ | ✅ | ✅ | ❌ |
| ✅ | ✅ | ✅ | ❌ | |
| Hume | ✅ | ❌ | ❌ | ❌ |
三、音色控制与编辑能力
| 公司 | 音色设计/捏音色 | 音色编辑/混合 | 音色转换 |
|---|---|---|---|
| 豆包 | ❌ | ✅ (音色加权混合) | ❌ |
| 阿里 | ✅ | ❌ | ❌ |
| Minimax | ✅ | ✅ (加权混合/增强) | ❌ |
| Fish Audio | ❌ | ❌ | ❌ |
| ElevenLabs | ✅ | ✅ (编辑增强) | ✅ |
| OpenAI | ❌ | ❌ | ❌ |
| ✅ | ❌ | ❌ | |
| Hume | ✅ | ❌ | ✅ |
四、发音控制/多语种能力
| 公司 | 音素控制发音 | 跨语种合成 |
|---|---|---|
| 豆包 | ❌ | ✅ |
| 阿里 | ✅ | ✅ |
| Minimax | ❌ | ✅ |
| Fish Audio | ❌ | ✅ |
| ElevenLabs | ✅ | ✅ |
| OpenAI | ❌ | ✅ |
| ✅ | ✅ | |
| Hume | ✅ | ✅ |
五、输入格式支持与输出能力
| 公司 | 支持 SSML | 支持 LaTeX | 返回字级时间戳 | 流式输入输出 |
|---|---|---|---|---|
| 豆包 | ✅ (简单格式) | ✅ (简单格式) | ✅ (字级别) | ✅ (单&双流) |
| 阿里 | ✅ (复杂格式) | ✅ (复杂格式) | ✅(商用接口) | ✅ (单&双流) |
| Minimax | ✅ (复杂格式) | ❌ | ❌ | ✅ (单流) |
| Fish Audio | ❌ | ❌ | ❌ | ❌ |
| ElevenLabs | ✅ | ✅ | ✅ (字符级) | ✅ (单流) |
| OpenAI | ❌ | ❌ | ❌ | ✅ (单流) |
| ✅ | ❌ | ❌ | ✅ (单流) | |
| Hume | ✅ | ✅ | ❌ | ✅ (单流) |
六、合成速度与稳定性
| 公司 | 延迟 / RTF 指标 | 提到模型仍存在稳定性问题 |
|---|---|---|
| 豆包 | 首包 < 600 ms;RTF≈0.5 | ✅ 提到稳定性问题 |
| 阿里 | 首包 < 500 ms;RTF≈0.3 | ✅ 提到稳定性问题 |
| Minimax | 未说明 | 未说明 |
| Fish Audio | 未说明 | 未说明 |
| ElevenLabs | 最低 75 ms | ✅ 提到稳定性问题 |
| OpenAI | 未说明 | 未说明 |
| 未说明 | ✅ 提到稳定性问题 | |
| Hume | 首包 < 200 ms | 未说明 |
各家公司能力详细版详见下文。
1. 字节跳动-豆包:Seed-TTS
官方文档:https://www.volcengine.com/docs/6561/1257543
豆包语音合成2.0能力介绍:https://www.volcengine.com/docs/6561/1871062
CosyVoice 开源链接:https://github.com/FunAudioLLM/CosyVoice
☆ 技术能力现状
字节跳动火山引擎于2024年推出了“豆包”语音大模型系列,其中核心是 Seed-TTS 模型家族。Seed-TTS 提供了两种技术路线:一是自回归模型(AR)支持零样本声音复刻,即 Seed-TTS-ICL,可通过输入几秒语音快速复刻说话人音色;二是非自回归扩散模型,即 Seed-TTS-DiT,采用扩散式生成替代传统显式时长预测,实现端到端语音生成。
除了 Seed-TTS 外,字节其他团队还发布了 Mega-TTS 系列模型。最新的 Mega-TTS 3 方案引入了 WaveVAE 和 稀疏对齐扩散 Transformer(Sparse-Aligned DiT)技术,实现了零样本快速声音复刻。Mega-TTS 3 通过 PeRFLow 方法将扩散步数从25步减少到8步,大幅提升合成速度。
MegaTTS 有官方维护的代码库,但模型参数未开源:https://github.com/bytedance/MegaTTS3
豆包目前以 Seed-TTS 系列模型为主流方案,Mega-TTS 系列正在逐步被替换。Seed-TTS 基础模型具备强大的音色多样性和可控性,体现在:
- 精品音色支持:豆包团队已支持数百个高品质的音色供商用,涵盖直播主持、广播、剧情等场景。不仅可模拟不同方言和口头习惯,还能生成真实说话细节,智能预测文本中的情绪、语调等。
- 情感和副语言合成:Seed-TTS 通过指令微调和强化学习,能够准确控制愤怒、高兴、悲伤、惊讶等情绪表达。
- 声音复刻能力:仅需5秒录音即可定制专属音色,发音及韵律高度还原,能保留提示者的说话风格和音色特点(跨语种声音复刻的常见能力)。
- 输入输出支持:对于数字、符号、LaTeX 公式等特殊文本,Seed-TTS 在最新发布的 2.0 系列模型也已经支持更准确的处理。输出时间戳方面支持返回字级别时间戳,具体方案未透露,可能通过后处理强制对齐获得。
- 响应速度:豆包提供实时语音大模型服务版本,官方文档显示在服务器上实测实时因子约0.5(生成1秒语音耗时0.5秒),首包延迟约600ms。
☆ 公开信息摘录
精品音色
- 精品音色支持 300+ 音色,覆盖不同语种、方言/口音、情感(情感种类很多)
- 情感支持采用 1-5 不同数字来控制情感表现力
- 支持对多个已有音色进行加权混合,快速生成全新的个性化声音
- 支持 SSML 格式输入,支持 Latex 输入,支持 markdown 格式解析
- 支持输出单向流式和输入输出双向流式两种接入方式,支持返回字级别时间戳
- 支持模型自发预测语调和重读,支持笑声、哭腔等副语言现象的合成
- 非流式版本生成 10 秒音频约需 5 秒(实时率 RTF 约 0.5),流式调用的首包延迟约 600 毫秒
- 最新 Seed-TTS 2.0 模型:
- 支持通过自然语言描述,实现对情感、风格的精准调整,大幅提升语音的可控性
- 支持输入合成文本的上文,模型会理解并承接语境的情绪后,合成效果更优
声音复刻
- 模型方案有多组代称,根据上线时间和文档信息,可以初步判断:
- ICL 声音复刻 → SeedTTS-ICL 方案
- DIT 声音复刻 → SeedTTS-DIT 方案
- DIT 标准版 → 音色相似,不还原用户的风格
- DIT 还原版 → 音色相似,同时还原用户口音、语速等风格
- 声音复刻 2.0 → Mega-TTS方案
其他信息
- 官方文档强调了声音复刻大模型存在不少已知问题
- 模型存在幻觉问题:发音错误、声音跳变、合成不稳定
- 出现合成不好的情况,建议用户调整 prompt 质量,或者合成多次解决
- 官方文档还泄露了一些技术术语,比如
- DMD(来自https://www.volcengine.com/docs/6561/1829010)
- 推测(不保证准确):使用了 CFM 分布匹配蒸馏的方案降低采样次数
- WVAE(来自https://www.volcengine.com/docs/6561/1257544)
- 推测(不保证准确):采用了 WaveVAE 的 latents 进行建模
- DMD(来自https://www.volcengine.com/docs/6561/1829010)
总体而言,豆包通过在 Seed-TTS 方案上持续深耕,在商业化程度、可控合成能力、情感表现力及音色多样性方面,已经建立了全方位的能力版图,形成了国内最成熟的一条语音产品线。
2. 阿里巴巴:CosyVoice & Qwen3-TTS
CosyVoice 大模型:产品简介_智能语音交互(ISI)-阿里云帮助中心
Qwen-TTS:通义千问的语音合成模型_大模型服务平台百炼(Model Studio)-阿里云帮助中心
Qwen3-TTS:Qwen3-TTS-Flash:多音色 & 多语言 & 多方言的语音合成
阿里在语音合成领域的布局,包括通义语音实验室的 CosyVoice 系列和通义千问的 Qwen-TTS 系列两部分。
☆ 两种技术方案
CosyVoice 从v1到v3逐步升级:v1主打中英文合成,支持普通话和部分英语音色;v2 扩展至多种方言和英语口音(如东北话、粤语以及英式、美式英语);v3 则进一步提升合成质量和多样性,并提供了 v3-plus 高阶版本(猜测是更大参数量模型)以追求极致逼真效果。CosyVoice 能结合上下文预测情绪和韵律,还支持双向流式合成,也就是在上游大模型生成文本时,实时将部分文本转语音输出,满足对话系统低延迟语音回答的需求。相较之下,阿里早期的 Sambert 模型不仅自然流畅度不够,还不支持流式,只能在获取完整文本后一次性生成语音。
2024年底,阿里通义千问团队推出了 Qwen-TTS 模型,9月份升级至 Qwen3-TTS(对应于 Qwen3 系列模型),支持17种音色和10种语言,涵盖9种汉语方言及多种外语,在官方评测中各项指标全面优于 Qwen-TTS。Qwen-TTS 一直没有公开技术方案,但是根据通义千问推出的 Qwen2.5-Omni 中提及了 Qwen-TTS-Tokenizer 及 Qwen2.5-Omni 中 Talker(TTS 模型)的结构,猜测 Qwen-TTS 整体架构与 CosyVoice 差异不大。
☆ 公开信息摘录
CosyVoice 系列
- 支持丰富的 Latex 和 SSML 格式,但是不支持输出时间戳
- 支持通过 SSML 指定音素来控制发音(模型具备音素控制发音的能力)
- 支持富语言声音事件以及多情感语音生成,例如笑声、语气词等,以及不同情感表现
- 响应时间的技术指标
- 首包延迟:正常500ms左右
- RTF(RTF = 合成总耗时/音频时长):正常0.3左右
- 支持输入输出双向流式调用
Qwen-TTS 系列
- 最新版 Qwen3-TTS 在方言能力和音色丰富度上更优,但尚未支持声音复刻能力
- 同样支持输入输出双向流式调用
- 亮点能力:每个音色都能支持十几种语言,没有语种合成上的瓶颈
3. Minimax:Minimax-Speech
MiniMax Speech 02:AI语音的Her Moment: 个性化交互达到临界点 - MiniMax News
MiniMax Speech 2.5:全球第一再升级!MiniMax Speech 2.5上线:多语种表现力更强,音色复刻更“像” - MiniMax News
MiniMax 是国内少数在语音合成大模型方向出圈的创业团队之一,推出了新一代语音大模型 abab-speech 系列。2023年11月MiniMax发布了 _abab-speech-01_,之后又取消_abab_代号,迭代出 speech-02 (2025年5月发布)和近期的 speech-2.5 版本(2025年8月发布),大幅提升了韵律节奏、情感表现、多风格和中英混合支持等能力,并在海螺等平台上线,已经有大量国内外忠实用户进行使用。
MiniMax 模型以超大规模语音数据训练,效果一度领先于ElevenLabs和OpenAI,曾在 TTS Arena(https://tts-agi-tts-arena-v2.hf.space/leaderboard)平台上多次登顶。根据公开的 Minimax-Speech 技术报告,其架构借鉴了Tortoise-TTS的思路:采用离散语音表示、LLM自回归建模和流匹配相结合,同时基于可学习的 Speaker Encoder 模块,实现高保真语音合成和音色迁移。
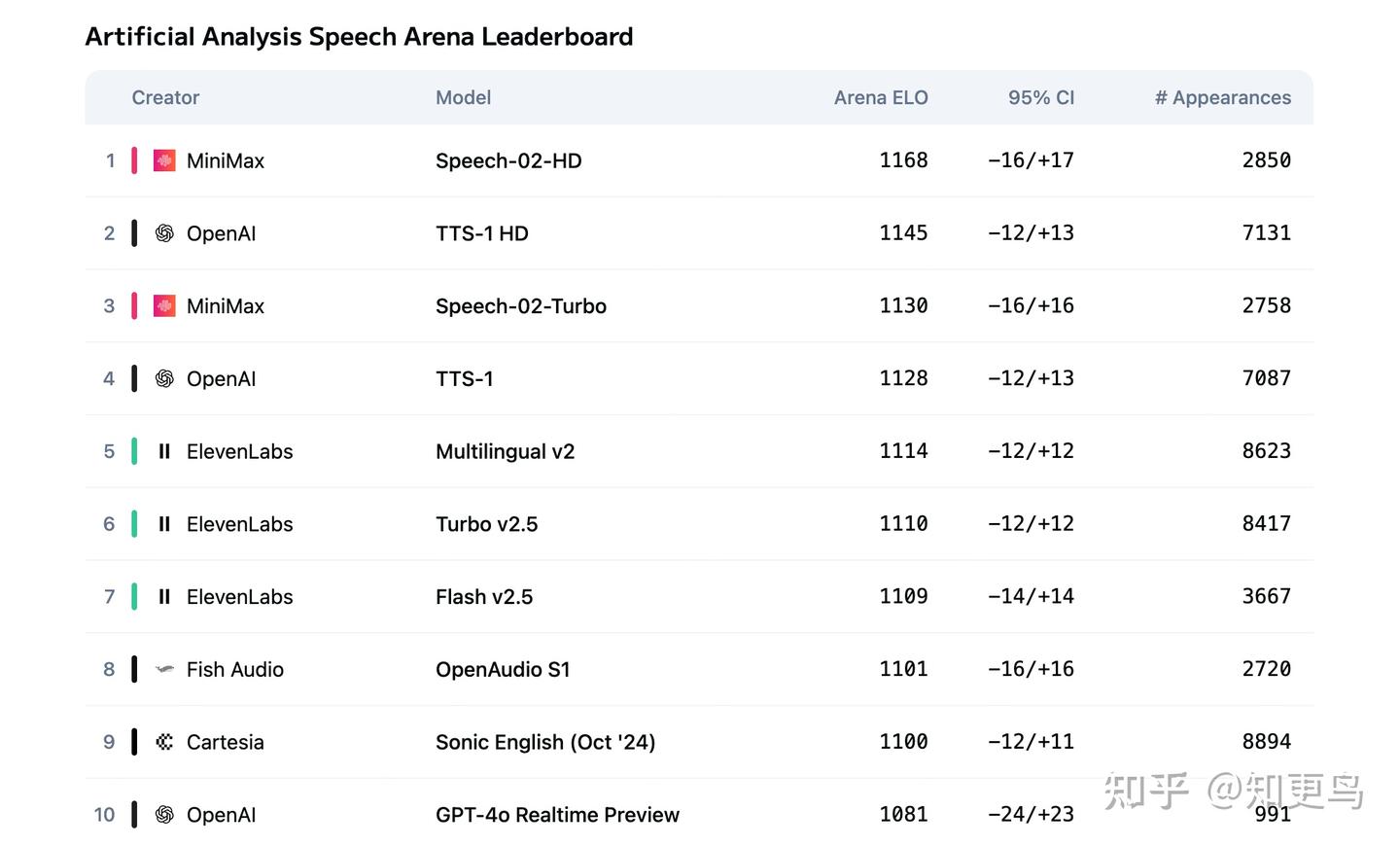
此外,Minimax 近期也上线了类似 ElevenLabs 的音色设计能力,基于文本描述生成虚拟的音色。

☆ 公开信息摘录
- 技术方案上采用类似 Tortoise-TTS 的 Learnable Speaker Encoder 方案
- 核心能力:基础语音合成
- 支持语种丰富,包括很多小语种
- 支持持自定义句子间的停顿时长:在输入文本中加入‘<#X#>’来控制句子间的停顿
- 支持自定义语音情绪:当前支持7种情绪;模型也会根据文本内容自动代入合适的情感
- 支持音色效果调节:可自由调节多维度音色参数,并提供多种音色特效
- 目前只支持句子级别的时间戳,不支持字级别/音素级别的时间戳
- 特殊能力:音色设计
- 除了支持按比例混合音色,还支持通过提示词/prompt 文本描述来生成和保存音色
- 提示词举例:古代行侠仗义的侠客,声音洪亮正直,充满英雄气概,语速果断
4. FishAudio
开源链接:https://github.com/fishaudio/fish-speech/
中文文档:https://github.com/fishaudio/fish-speech/blob/main/docs/README.zh.md
Fish-Speech 系列模型是近年来开源社区的焦点,来自于语音合成方向的明星创业团队FishAudio。模型强调不依赖音素表示,直接以字符或字词作为输入特征(当然目前这已经成为大多数 TTS 模型方案的选择)。
最新版本 OpenAudio S1 支持多种语言,包含 0.5B 和 4B 两个不同参数量级。在官方公布的SeedTTS评测中,在英文合成上达到了词错误率 WER≈0.8%、字错率 CER≈0.4%的优秀成绩(注意使用的是 OpenAI GPT-4 ASR 转写进行的评测)。精品音色方面,FishAudio作为开源项目并未内置大量成品音色库,更多是提供一个灵活的工具:用户可以加载自定义语音样本,即时复刻出任意音色,模型还支持副语言声音的生成,支持多种情感、语调和特殊标记来增强语音合成能力。

5. ElevenLabs
官方文档:https://elevenlabs.io/docs/capabilities/text-to-speech
ElevenLabs 是国外语音合成领域的知名企业,其产品以即时声音复刻(Instant Voice Cloning, IVC)和专业声音复刻(Professional Voice Cloning, PVC)两种模式著称。
IVC 模式其实通常说的声音复刻,只需上传几秒到几十秒的录音,系统即可近乎实时就具有对应音色的复刻能力,无需专门训练模型。需要注意,IVC并不单独微调模型参数,而是利用已有训练数据中的广泛说话人特征,对新声音进行参考性的合成。这种方式对大多数常见音色都效果惊人,但对于非常独特的音色声线(模型训练中未覆盖的),可能会有不足。
PVC 则是针对更高要求的复刻需求,ElevenLabs 支持PVC服务:用户提交大量录音(通常几分钟到几小时),系统会训练出一个专属定制模型,能几乎完美地复现目标声音。PVC由于涉及模型微调,处理时间在数小时量级。两种模式结合,使得ElevenLabs既能满足快速体验(IVC几分钟获得结果),又能实现高保真度(PVC模型发音几可乱真)。这套IVC+PVC体系也成为行业标杆,不少其他平台(如国内的MiniMax Speech、国内Google 的Chirp等)在借鉴类似思路。
在音色和音库方面,ElevenLabs内置了丰富的预设声音和自定义声音管理工具。用户既可以从其声音库中选择官方提供的成熟声音,也可以通过音色设计(Voice Design)工具基于文字描述来生成全新声音。
Voice Design 是一项非常有意思的能力。最新的 ElevenLabs v3 生成模型,允许用户输入诸如“年轻的英伦腔女性,语调热情友好”这样的描述,模型会据此生成三条候选声音供试听选择。
文本描述支持人设、口音、性别、风格,越细节越好
文本描述中也可以说明对音质的要求
这种基于文本 prompt 描述的音色生成极大地方便了创作者,弥补了库中没有合适声音时的空白。不过ElevenLabs也强调目前PVC复刻的真人声音在质量上仍是最佳选择。除了音色设计,ElevenLabs还支持用户对已有音色进行声音混合、效果叠加等Remixing 能力,使AI声音更符合创作需求。
音色设计(Voice Design)是完全无中生有,音色编辑组合(Voice Remixing)是基于现有音色进行调整编辑。
在性能上,ElevenLabs的云服务表现相当优异。其实时性主要取决于所用模型版本:标准版模型侧重高品质,生成可能略慢,而提供的_Eleven Labs High Speed (Flash)_模型则进行了优化,可在保证自然度前提下更快返回结果。社区用户反馈其平均速度约为实时的23倍,即每生成1秒语音需0.30.5秒。对于几秒钟长度的文本,用户往往在1秒内就能拿到完整音频。
总体而言,ElevenLabs通过丰富的工具链(即时复刻 + 专业复刻 + 文本设计音色 + 音色编辑组合)和稳健的多语言生成,成为当前业内功能最齐全、易用性很高的商用TTS平台之一。
☆ 公开信息摘录
普通语音合成
- 支持很多 audio tag 达到更好的合成效果
- 支持副语言 tag、情感 tag、音效 tag、口音强度控制 tag 等多项能力,tag 可以组合使用
- 大长段落合成的时候,支持带上前文或者下文,合成的会韵律会更好
IVC 即时音色复刻 - 录音经验
- 最少一分钟,但别超过3分钟
- 干净,无混响/噪声
- 128kbps 以上码率
PVC 专业音色复刻 - 录音经验
- 强调想要啥效果,就得录出来啥样的效果
- 跨语种的效果是很难保证的,会存在口音残留,最好按照音色期望的语种来录制
- 最少提供 30 分钟音频,最好提供 2-3 小时音频
关于模型效果
- 请求文本的大小写、标点、都会影响合成效果:大写表示重读、省略号增加停顿
- 支持针对请求文本进行额外增强(enhance)
- 使用额外的文本模型预测出 audio tag,主要是副语言、插入语等(类似 ChatTTS)
- 强调了模型合成仍然是有不稳定/badcase
- 重新合成第二次,能够解决一半左右的合成质量问题
- ElevenLabs 接口,模型合成是具有随机性的,固定随机种子可以缓解这个问题,但仍然可能存在小的随机性
- 过短的文本,会导致合成结果不一致/不稳定,建议超过 250个字符来合成
- 复刻场景下,prompt 音频音色一致性差的话,模型会出现混淆,合成也更加不稳定
6. OpenAI
试用页面:https://openai.fm
OpenAI 在2025年推出了首个面向开发者的语音合成模型,即 gpt-4o-mini-tts,并配套上线了演示平台 OpenAI.fm。与传统TTS模型不同,OpenAI的方案体现出强大的提示词可控(Steerability)特点。开发者不仅可以输入文本让模型“念出来”,还可以在提示中指定语气、情感、语速、口音等风格要求。
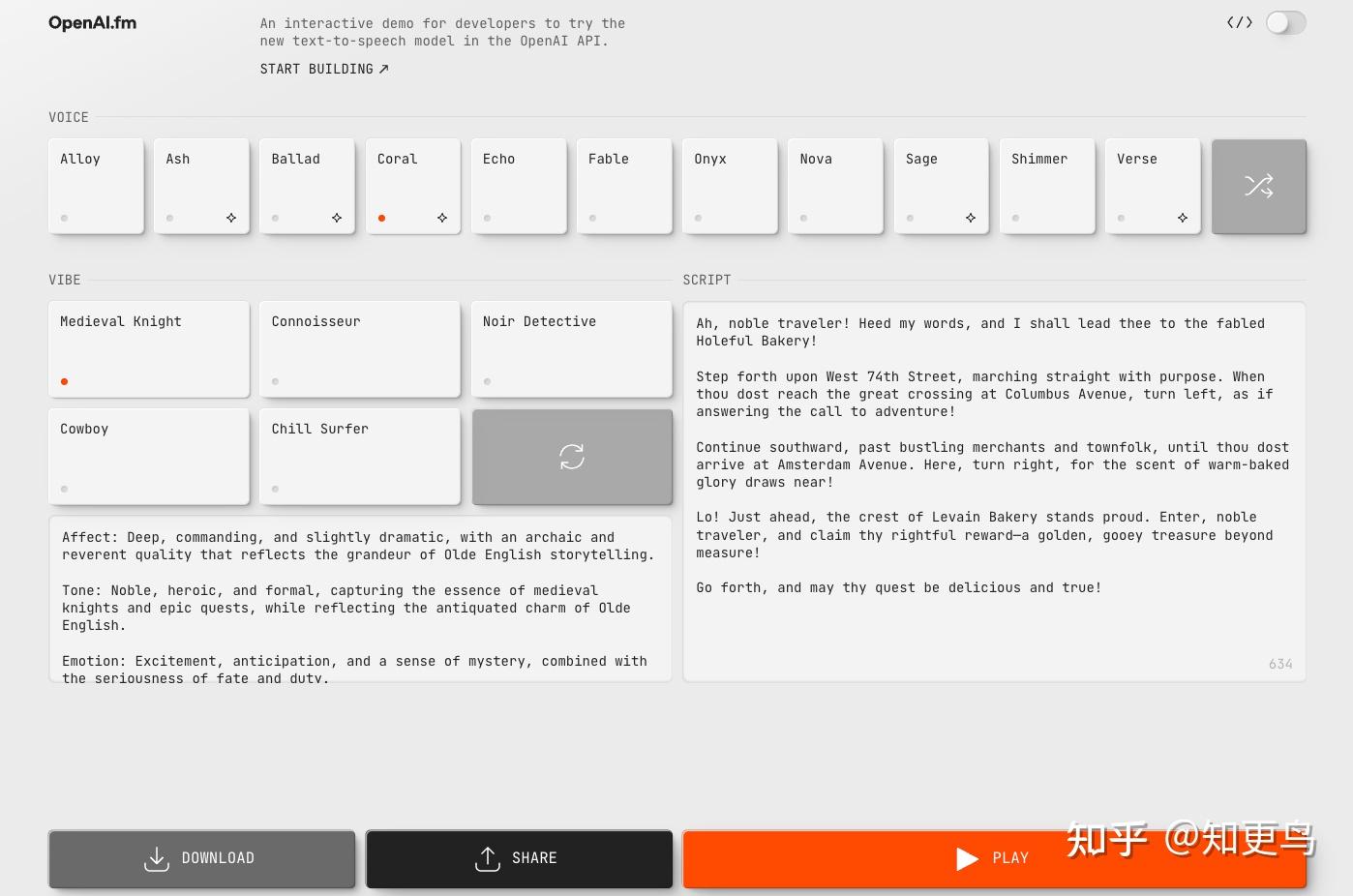
OpenAI.fm 提供了11个内置基础音色(如 Sage, Ash, Coral 等),各音色均支持多语种。用户选择一个声音后,可以通过一个 instructions 字段来控制该声音的表现。这个功能和近期豆包 Seed-TTS 2.0 的功能一样,但是OpenAI 比较早就进行了支持。例如,OpenAI给出的示例中,开发者可以在提示中写:
1 | Voice Affect: Calm, composed, and reassuring; Tone: sincere, empathetic; |
这样的自然语言描述将指导模型以冷静且令人安心的声音效果来朗读后续文本。同理,也可以提示模型“带有意大利口音地说英语”或“像疯狂科学家一样说话”,模型都会据此调整输出音频的风格。OpenAI在技术直播中强调,gpt-4o-mini-tts 可以被视为将LLM对文本语义、语境的深刻理解融入到了语音生成中——它并非逐字逐句地读,而是真的理解语义后有表现力地说出来。这也解释了为何OpenAI的TTS能做到遇到电影对白时充满戏剧张力,遇到客服场景时又语调柔和富有同理心。
OpenAI.fm支持多语言和多说话人场景。目前11种内置声音覆盖了多种性别和年龄效果,主要针对英语进行了精调,但模型本身是多语言的。声音复刻方面,OpenAI目前没有公开提供用户上传样本来自定义音色的功能(即没有像ElevenLabs那样的IVC/PVC接口)。OpenAI偏向于让用户使用其预设声音,再通过提示调试不同风格。
总的来看,OpenAI以GPT系列为基础打造的TTS,它没有将语音看作单独的任务,而是视为LLM能力延伸的一部分。这带来的好处是模型在可控性和上下文理解上表现卓越——用类似写Prompt的方式就能定制输出风格。
7. Gemini-TTS
Gemini-TTS:https://cloud.google.com/text-to-speech/docs/gemini-tts?hl=zh-cn
Chirp 3:高清语音 https://cloud.google.com/text-to-speech/docs/chirp3-hd?hl=zh-cn
Chirp 3:即时自定义语音:https://cloud.google.com/text-to-speech/docs/chirp3-instant-custom-voice?hl=zh-cn
2023年底,Google在Gemini Live实时助手中首次展示了其AI语音对话功能,引发业界关注。2024年,Google Cloud发布了 Gemini-TTS 模型,作为其云TTS服务的新一代产品。Gemini-TTS 有两个主要配置:2.5-Flash TTS(侧重低延迟)和 2.5-Pro TTS(侧重可控度和复杂场景高质量)。
在情感和副语言能力上,Gemini-TTS 明显提升了对复杂文本的演绎。例如它可以有感情地朗诵诗歌、用播新闻的腔调播报新闻,甚至在故事旁白中根据标点和语义自动断句、变换语气。模型可以执行诸如“大笑着说出这句话”这样的指令,也可以根据感叹号、问号自动调整语调高低。对于口语填充词(如 “uhm”, “er”)模型也能合成出自然的语气词音,对于喘气、叹气等声音,Gemini允许在Prompt里直接写入[sigh]或类似标识符并在音频中反映出来,这一点非常适合有声书和多角色有声内容的精细制作。
Gemini-TTS支持使用音素来自定义发音,说明模型也具备基础的音素控制发音能力;同时,开放了声音复刻能力和接口,并且支持跨语种的声音复刻。

8. Hume AI
官方介绍:https://www.hume.ai/blog/octave-2-launch
Hume AI 在国外的语音合成领域也是能力相对突出的公司,专注情感和高表现力合成。其推出的 Octave 2 模型被誉为全球首个将语音转换(Voice Conversion)和直接音素编辑(Phoneme Editing)引入大模型TTS的产品。Octave 2 是一款多语言的“语音-语言模型”(Speech-Language Model),融合了语言理解和语音生成两方面能力。它支持11种语言(涵盖英、中、日、韩、法、德、印地等常用语种),并通过持续训练计划拓展到20+语言。
与前述模型类似,Octave 2 能根据输入文本情境自动调整演绎方式,真正做到“理解文本再开口”。例如,官方表示Octave遇到秘密对白会自动压低声音近似耳语,遇到高亢情节会提高音调和音量。这种对剧本的深度理解使其合成的语音不仅音质高度自然(几乎听不出AI痕迹),更难得的是具备人物性格和情绪。Hume团队强调模型可再现一个说话人的“人格”,而不仅仅是嗓音,这对于配音和数字人应用极为重要。
Octave 2 在声音复刻方面同样出色。它采用instant cloning零样本复刻,仅需约15秒的目标声音录音,便能创造出该声音的AI副本。生成的AI声音不仅在原语言上几可乱真,在说其他语言时也会带有原说话人的独特口音和说话风格。
总体而言,Hume的方案非常适合对情感真实度要求极高的场景(影视配音、有声读物)以及需要精细后期的场景。
总结
总体来看,过去两年语音合成技术正处于爆发式演进阶段。无论是国内外综合实力更强的大厂,比如:字节跳动、阿里、OpenAI和Google,亦或是以MiniMax、ElevenLabs 等代表的专攻语音生成领域的新生力量,都在从“自然度”走向“高表现力”和“可控性”的新阶段。
从行业趋势上看,有三点尤为值得关注:
- 模型范式统一化——几乎所有厂商都在尝试将 TTS 模型与 LLM 融合,形成 “Speech-Language Model” 的通用范式,使语音合成从“照着读”走向“想好怎么说”,从单纯的语音模仿任务,上升到语言理解之后进行更好表达的任务。
- 情感与人设可控性增强——从情感标签到自然语言描述控制,再到文本描述生成丰富的音色,TTS 模型的指令可控能力显著提升,创作者能够像“导演”一样操控AI的音色、语气与风格。
- 商业化与生态扩展——各公司平台正在通过开放 API、音色库、即时声音复刻工具,推动语音合成大模型从技术探索大步走向生态落地,大模型语音生成正逐渐成为内容生产、交互体验、数字人产业的重要基础能力。
- 本文标题:专题分享 | 2025年10月,一文梳理国内外八大厂商 TTS 能力
- 创建时间:2025-10-22
- 本文链接:2025/2025-10-22-tts-companies/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!