本文继续分析 CosyVoice 项目中 LLM 做强化学习的另一种方式,即 GRPO(Group Relative Policy Optimization)。以 examples/grpo/cosyvoice2 的实现为例,分析下如何把比较成熟的 NLP LLM 强化学习训练框架,迁移到 TTS 模型训练中,高效地进行强化学习训练。
1. TTS 引入强化学习
通常的 TTS 模型训练采用监督学习方式,给定输入文本,让模型预测对应的 speech tokens,loss 是 token 预测的交叉熵,不管是预训练还是 Speaker Finetuning 的 SFT,都是采用这种训练方式。但这种方式有几个局限:
- 训练和评估目标不一致:训练阶段用 token 级别的 cross-entropy 目标,但实际真正关心&评测的是”合成出来的语音听起来对不对”,有没有发音、语调、停顿等维度的错误,训练目标和最终的评价方式并不完全一致。
- exposure bias:训练时用 teacher forcing,推理时自回归,误差会累积(不过这一点在 LLM 上已经不做过多考虑)。
- 缺乏全局质量反馈:cross-entropy 只看到了单个 token(token-level)的概率,无法衡量整条语音(utterance-level)的效果。
强化学习的引入,正是为了弥补这些不足:
- 端到端优化真实指标:用一些更加符合目标的评价方式,作为 reward(奖励),比如”ASR 识别准确率”作为 reward 来优化 TTS LLM,让模型生成的 speech tokens 更符合最终评价方式。
- 探索-利用平衡:通过采样多条 rollout 并比较相对好坏,模型可以发现比 SFT 更优的生成策略。
- 全局反馈:reward 能够基于整条语音进行计算,考虑了序列级别的质量。
2. CosyVoice2 的模型架构回顾
理解 GRPO 训练,首先需要了解 CosyVoice2 的两阶段 TTS 架构:
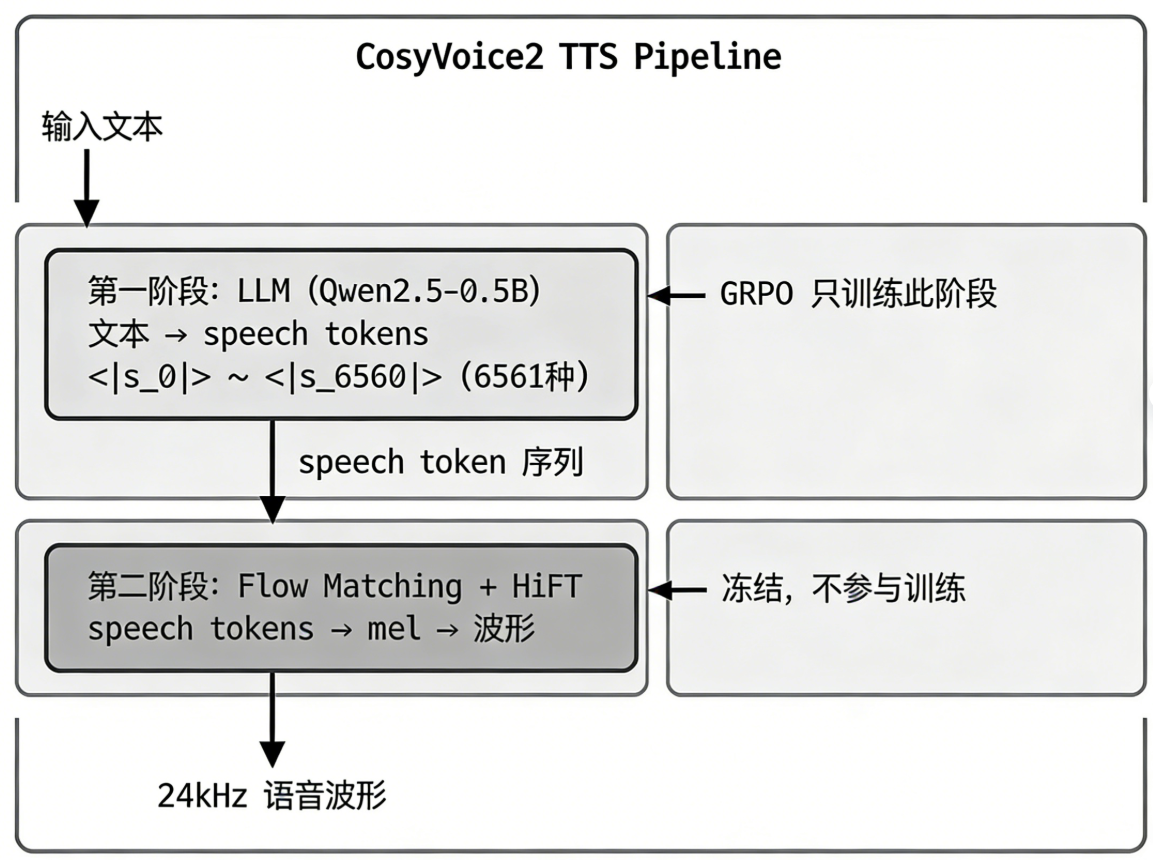
关键点:
- LLM(第一阶段) 是 Qwen2.5-0.5B 模型,词表在原始文本 token 基础上扩展了 6561 个 speech token(
<|s_0|>~<|s_6560|>),加上<|eos1|>,<|eos2|>,<|eos3|>,<|sos|>,<|task_id|>等特殊 token。 - Flow Matching + HiFT(第二阶段) 将离散的 speech tokens 转为连续的 mel 频谱,再合成为波形。这部分在 GRPO 训练中完全冻结,仅用来做 token2wav 转换为波形。 GRPO 的定位是 只优化 LLM 的 speech token 生成策略(如果是 Flow Matching 的强化学习,会有单独的优化方案比如 Flow-GRPO)。
下面是 CosyVoice2 基于拼音 WER 指标做 GRPO 之后的收益。本文就详细解析下具体的原理和代码实操。
| 模型 | Seed-TTS test_zh CER |
CosyVoice3 zero_shot_zh CER |
|---|---|---|
| CosyVoice2 LLM(原版) | 1.45% | 4.08% |
| CosyVoice2 LLM + GRPO | 1.37% | 3.36% |
- zero-shot 中文测试集 CER 从 4.08% 降至 3.36%,相对下降 17.6%
- Seed-TTS 测试集 CER 从 1.45% 降至 1.37%,也有小幅优化
3. GRPO 基本原理
GRPO(Group Relative Policy Optimization)由 DeepSeek 在 DeepSeekMath 中提出,是 PPO 的一种简化变体。
3.1 与 PPO 的核心区别
PPO 强化学习使用的是 Actor-Critic 架构,需要同时维护 Actor(Policy)模型和一个额外的 Critic(Value)模型,在每个 token 位置估计一个基线值(状态价值),用于计算优势函数:
此处不做展开,但需要明确的是 PPO 这种训练方式,意味着:
- 额外的网络参数:Critic 通常与 Actor 虽然是相同 backbone 架构,但参数是额外独立的一份参数。对 Qwen2.5-0.5B 来说,这几乎多一倍的显存用于梯度和优化器状态。
- 实现复杂度:需要同步更新 Actor 和 Critic,处理两个网络的学习率、梯度裁剪等。
而 GRPO 的思路更简单粗暴:对同一个 prompt,采样一组(group)输出(通常称为 rollout),直接用组内的统计量作为基线:
其中
3.2 GRPO 的优势
| 特性 | PPO | GRPO |
|---|---|---|
| 需要 Critic 网络 | 是(额外的训练和推理开销) | 否 |
| 优势估计方式 | TD 误差递归(GAE) | 组内均值归一化 |
| 适用场景 | 通用 RL | 更适合 ORM(outcome reward) |
| 实现复杂度 | 高 | 低 |
对 TTS 场景来说,reward 是基于整条生成语音计算的(outcome reward),天然适合 GRPO,同时省去了 Critic 网络大大简化了训练 pipeline。
3.3 GRPO 训练的直观理解
假设对文本 “Hello World!” 采样了 4 条 speech token 序列,各自的 reward 分别为:
| 回复 | Reward | 归一化优势 |
|---|---|---|
| 序列 A | 0.92 | +1.2(好,增大概率) |
| 序列 B | 0.85 | +0.3(较好,略增概率) |
| 序列 C | 0.78 | -0.6(较差,减小概率) |
| 序列 D | 0.65 | -0.9(差,大幅减小概率) |
GRPO 不关心绝对 reward 值,只关心组内相对差异,使得算法不受 reward 量纲尺度的影响,只需要能区分相对好坏即可。
4. 整体训练流程(Pipeline)
以上简要说明了下技术原理和思想,下面直接深入看下代码实战。CosyVoice2 的整个 GRPO 流程由 examples/grpo/cosyvoice2/run.sh 脚本统一调度,GRPO 的训练框架选用的是字节开源的 verl,配置完 verl 环境外,核心分为 7 个 stage:
1 | Stage -1: 模型格式转换 ──→ HuggingFace 兼容的 LLM |
核心文件间的调用关系
1 | run.sh |
4.1 Stage -1:模型格式转换(pretrained → HuggingFace)
文件:pretrained_to_huggingface.py
CosyVoice2 的模型结构不是 Huggingface Transformers 支持的标准 LLM 结构,包含了很多 speech 模态的结构设计,speech 的相关权重是分离存储的,包括:
speech_embedding:6561 个 speech token 的输入 embeddingllm_decoder:speech token 的输出投影头(含 bias)llm_embedding:<|sos|>和<|task_id|>等 special tokens 的 embedding
转换脚本将这些权重合并到标准 Qwen2.5 模型中。
词表合并
1 | # 扩展词表:原始 Qwen 词表 + special tokens + 6561 speech tokens + 5 特殊 tokens |
这一步将文本词表和语音任务的词表统一到同一个 tokenizer,得到的新词表:
1 | [0, original_tokenizer_vocab_size) → 文本 token(Qwen2.5 原始词表 + special tokens) |
扩展 embedding 并填充 lm_head
1 | llm.resize_token_embeddings(len(tokenizer), pad_to_multiple_of=128) |
最关键的操作是构建一个统一的 lm_head(输出层):
resize_token_embeddings:将 Qwen 的 input embedding 扩展到新词表大小,pad_to_multiple_of=128是为了对齐到 128 的倍数以优化 GPU 计算效率- 创建新的
lm_head:注意带bias=True(原始 Qwen2.5 的 lm_head 是无 bias 的,但 CosyVoice2 的 llm_decoder 有 bias),这一点在与主流推理框架配合时也会带来一些小麻烦 - 权重初始化策略:这里非常巧妙:
- weight 全部置零 → 文本 token 的 logit 输出为 0
- bias 全部置为
→ 文本 token 的 logit 为 ,只有 speech token 对应的区间才被填入真实的 llm_decoder 权重,这样经过 softmax 之后其他位置概率为 0,确保模型在生成 speech token 时永远不会输出文本 token。
转换后的模型可被 veRL/vLLM/Transformers 当作标准 Qwen2.5 模型加载和推理。同时设置了 chat template:<|sos|>{text}<|task_id|>{speech tokens},这样 veRL 在做 GRPO 采样时,可以直接用标准的 chat API 构建 prompt,模型在 <|task_id|> 之后开始自回归生成 speech token 序列。
4.2 Stage 0:数据准备
将 AISHELL-3 数据集(约 88035 条中文语音数据)转为 veRL 要求的 parquet 格式。每条数据包含:
1 | { |
关键设计:
assistant.content留空 → veRL 会让模型从这里开始自回归生成 speech tokens 获取 rolloutground_truth保存原始文本 → 后续 reward 计算时,方便与 ASR 识别结果对比
4.3 Stage 1:启动 Reward 推理服务
整个 GRPO 训练中,最关键的设计是将 reward 的计算过程,抽离为独立的 HTTP 推理服务。
服务基于 NVIDIA Pytriton(Triton Inference Server 的 Python 封装),在 8 张 GPU 上各部署一个 _Token2Wav_ASR 实例,每个实例包含:
- CosyVoice2 解码器:Flow Matching + HiFT,将 speech tokens 解码为波形
- SenseVoice ASR 模型:将合成的语音波形识别为文本
服务启动后监听 HTTP 端口 8000,接收 speech token IDs 和 ground truth 文本,返回 reward 分数。
1 | python3 token2wav_asr_server.py --number-of-devices 8 |
单独部署 Reward 服务的优势
CosyVoice2 解码器和 SenseVoice ASR 模型都需要 GPU 显存。如果和训练的 Actor 模型放在同一批 GPU 上,显存会不够用。独立部署后,训练 GPU 和 Reward GPU 可以是不同的机器/不同的卡。
4.4 Stage 2:GRPO 训练
文件:run.sh Stage 2 + reward_tts.py
调用 veRL 框架的 PPO trainer,通过参数切换为 GRPO 模式:
1 | python3 -m verl.trainer.main_ppo \ |
每个训练步骤:
- Rollout:从训练集采样 32 个 prompt(由
train_batch_size来指定),对每个 prompt 用 vLLM 生成 4 条 speech token 序列(共 128 条) - Reward:将 128 条序列通过 reward_tts.py → HTTP 请求 → Triton server 计算 reward
- Advantage:在每组 4 条中计算 GRPO 相对优势
- Update:基于 GRPO 的 loss,更新 LLM 参数
4.5 Stage 3-5:合并权重、评测、格式回转
Stage 3(verl.model_merger):训练使用 FSDP 分片存储权重,合并为完整的 HuggingFace checkpoint。
Stage 4(infer_dataset.py + scripts/compute_wer.sh):
- 用 RL 训练后的 LLM 在测试集上进行多卡分布式推理
- 生成的 speech tokens 经 CosyVoice2 解码为 wav 文件
- 用 sherpa-onnx Paraformer 做离线 ASR 转写
- 与 ground truth 对比计算 CER/WER
Stage 5(huggingface_to_pretrained.py):将 HF 格式模型转回 CosyVoice2 原始格式(llm.pt),方便在 CosyVoice 官方 repo 中使用。
5. Reward 函数设计详解
5.1 Reward 计算流程
Reward 的计算经历三步,全部在 token2wav_asr_server.py 的 _Token2Wav_ASR 类中完成:
1 | LLM 生成的 speech token IDs |
5.2 使用拼音级 WER
1 | gt_pinyin = lazy_pinyin(gt_norm, style=Style.TONE3, tone_sandhi=True, ...) |
使用拼音级别而非字级别的 WER,原因是:
- 中文存在大量同音字(如”的”/“得”/“地”,”做”/“作”),ASR 输出的同音字替换不应被视为发音错误
- 拼音级 WER 可以更准确地反映”语音听起来对不对”,而不是严格的”文字写得对不对”(引入了 ASR 识别的错误)
- 使用
Style.TONE3包含声调信息(如ni3 hao3),确保声调错误也会被惩罚 - 缺陷:用文本正则化 + 拼音 WER 的问题是,这些模块本身就是文本层面的任务,尤其是中文的多音字、儿化音、轻声、语气词等维度,可能会引入一些模块本身导致的错误,造成一些不合理的分数。
5.3 为什么用 1 - tanh(3c) 映射
1 | reward_val = 1.0 - np.tanh(3.0 * c) |
这个 reward 映射函数,确实有一些考量。
(1)reward score 限制在 [0, 1]
WER c 的取值范围是 [0, +∞)(当插入错误很多时可以超过 1),简单的 1 - c 会产生负值。而 tanh 天然将输出限制在 (0, 1) 之间。
(2)系数 3 的作用
| WER | k=1: 1-tanh(WER) |
k=3: 1-tanh(3×WER) |
k=10: 1-tanh(10×WER) |
|---|---|---|---|
| 0% (完美) | 1.000 | 1.000 | 1.000 |
| 5% | 0.950 | 0.851 | 0.519 |
| 10% | 0.900 | 0.709 | 0.036 |
| 20% | 0.802 | 0.463 | 0.000 |
| 33% | 0.644 | 0.238 | 0.000 |
| 50% | 0.538 | 0.095 | 0.000 |
| 100% | 0.239 | 0.005 | 0.000 |
CosyVoice2 的 baseline CER 约 2-3%,大多数生成样本的 WER 在 0%~20% 之间。系数 3 使得 reward 在这个区间内变化幅度大、区分度高,让 GRPO 的分辨粒度更细;对于 WER > 50% 的低质量输出,reward 几乎都接近 0,相当于不浪费梯度信号去区分”很差”和”极差”。
(3)tanh 函数的作用
GRPO 计算组内相对优势 tanh 的非线性放大了低 WER 区间的差异,提供更清晰的优化信号。
6. 关键训练参数解读
以下是 run.sh Stage 2 中所有关键参数的分类解读:
6.1 算法核心参数
| 参数 | 值 | 说明 |
|---|---|---|
algorithm.adv_estimator |
grpo |
使用 GRPO 优势估计,无需 Critic Model |
rollout.n |
4 |
每个 prompt 采样 4 条回复(GRPO group size) |
actor.use_kl_loss |
False |
不额外增加 KL 散度惩罚,全靠小学习率控制偏移 |
6.2 训练数据配置
| 参数 | 值 | 说明 |
|---|---|---|
data.train_batch_size |
32 |
每步 32 个 prompt × 4 条 = 128 条生成 |
data.max_prompt_length |
1024 |
prompt 最大 token 长度 |
data.max_response_length |
512 |
对应 25Hz token,相当于生成序列最大长度(约 20 秒语音,这里其实设置的偏短了) |
6.3 Actor/Policy 模型
| 参数 | 值 | 说明 |
|---|---|---|
actor.optim.lr |
1e-6 |
极小学习率,防止灾难性遗忘 |
actor.ppo_mini_batch_size |
32 |
等于 batch size,每个 batch 都做 GRPO |
actor.ppo_micro_batch_size_per_gpu |
4 |
每卡 batch,控制显存 |
model.enable_gradient_checkpointing |
True |
梯度 checkpointing,用时间换显存 |
6.4 Rollout 推理参数
| 参数 | 值 | 说明 |
|---|---|---|
rollout.name |
vllm |
使用 vLLM 加速推理 |
rollout.gpu_memory_utilization |
0.6 |
vLLM 占 60% 显存,剩余留给训练 |
rollout.temperature |
0.8 |
采样温度 |
rollout.top_p |
0.95 |
Nucleus sampling 阈值(这里和目前推理使用的 top_p=0.8 有点出入) |
rollout.top_k |
25 |
只从 top-25 token 中采样 |
6.5 Reward 入口配置
| 参数 | 值 | 说明 |
|---|---|---|
reward_model.reward_manager |
prime |
reward 计算方式复杂,使用并行 reward 计算(64 线程) |
custom_reward_function.path |
reward_tts.py |
自定义 reward 函数文件 |
custom_reward_function.name |
compute_score |
函数入口名 |
6.6 Trainer 控制
| 参数 | 值 | 说明 |
|---|---|---|
trainer.total_epochs |
1 |
GRPO 只训练 1 个 epoch |
trainer.save_freq |
100 |
每 100 步保存 checkpoint |
trainer.test_freq |
100 |
每 100 步验证 |
trainer.n_gpus_per_node |
8 |
8 卡训练 |
6.7 参数间的关键关联
1 | train_batch_size (32) = n_gpus (8) × micro_batch_size (4) |
lr=1e-6 + use_kl_loss=False 是一组配合:没有 KL 约束时全靠极低学习率防止 policy 偏移过大。如果打开 KL loss,学习率可以适当调大。
7. Reward 客户端-服务端交互架构
reward_tts.py(客户端)和 token2wav_asr_server.py(服务端)之间的完整交互流程:
1 | veRL Trainer (训练主循环) |
这种客户端-服务端分离的设计有几个核心优势:
- 显存隔离:CosyVoice2 解码器 + SenseVoice ASR 需要大量 GPU 显存,与训练端物理隔离
- 独立扩缩容:reward server 可以单独部署更多 GPU 来提升吞吐
- 并行加速:Triton 的 DynamicBatcher 自动聚合并发请求为 batch,最大化 GPU 利用率
- 容错性:单条 reward 计算失败(超时/OOM)返回 0.0,不会阻塞训练
8. 拓展延伸:多维度奖励(Multi-Reward)
在 CosyVoice2 + GRPO 的实验中,reward 采用了”ASR 拼音级 WER”这一项指标。但在真实的 TTS RL 中,单一 reward 基本无法覆盖所有待优化维度。所以在 CosyVoice2 的基础上,可以进一步扩展到多维度 Multi-Reward,即每个 rollout/序列综合多个评价指标,提升模型在发音、音色、流利度等全方面质量:
8.1 常用 Reward 类型
- 拼音 WER:衡量语音与文本内容的准确率
- 口语打分(Prosody Scoring):用专门的口语评测模型,给生成的语音”流利度/发音/语调”评分,检测韵律错误
- 音色相似度:与参考音色 embedding 计算 cosine similarity,保证 timbre 还原
- 停顿/断句检测:统计停顿错误数(如短 pause、长 pause 位置对齐),提升表达自然度
或者可以单独结合以上维度,训练一个专门的 TTS 评测模型作为 Reward Model,训练排序模型(如 Bradley-Terry/Pairwise Preference Model),用多重标准筛选/人工标注的样本,对分数打标。
基于以上维度,通过加权融合为综合 reward,融合策略可根据实验和任务目标调整,一般是线性加权。
1 | final_reward = α * WER_reward + β * prosody_score + γ * timbre_sim + ... |
8.2 多个 reward 如何修改 verl 配置
veRL 框架已经原生支持”多 reward 源”与灵活 reward 汇总。在配置和代码层面调整非常简单:
多 reward 合成的 compute_score
可以在 reward_tts.py 内,为每个 rollout 依次请求所有 reward 服务,合成为最终 reward 分数。例如:
1 | def compute_score_multi(tokens, gt_text): |
也可以支持更复杂的 reward 结构,如输出 dict/tuple,主训练脚本做加权:
1 | # 返回多 reward 向量 |
修改 verl 配置:指定 reward function
主要有两种方式集成:
- 直接修改 config yaml(推荐):
verl/trainer/config/ppo_trainer.yaml 里修改 reward 相关字段。例如:1
2
3
4reward_fn:
_target_: verl.reward_tts.compute_score_multi # 指向你的多 reward 融合函数
reward_weights: [0.5, 0.3, 0.2]
reward_names: ["wer", "prosody", "timbre"] - 命令行参数覆盖:训练时附加参数覆盖,如
1
python main_grpo.py reward_fn=verl.reward_tts.compute_score_multi reward_weights="[0.5,0.3,0.2]"
- 多 Reward Model Server:如果 reward 已在外部 HTTP 服务汇总,直接让
compute_score统一请求服务返回总分。
若采用 RM(Reward Model)打分
- 训练新品质 reward model,用人类偏好对比作为监督,可用 Bradley-Terry/Pairwise Ranking 损失,训练方法与常规 LLM RM 类似,只需模型输出分数。
- 配置
reward_fn为包含 RM 推理逻辑的函数,通常只需要在verl/reward_tts.py增加一段调用外部或本地 RM 的接口。
附录:veRL 框架深入解析
A.1 veRL 是什么
veRL(Volcano Engine Reinforcement Learning)是字节跳动开源的 LLM 强化学习训练框架。核心架构:
- Ray 分布式调度:管理多 worker(Actor、Critic、Reward Model 等)
- FSDP 数据并行:分片存储模型参数和优化器状态
- vLLM 推理加速:rollout 阶段用 vLLM 的 continuous batching 和 PagedAttention 提升采样吞吐
- Hydra 配置系统:所有参数通过 yaml 配置 + 命令行覆盖
veRL 支持 PPO、GRPO、DrGRPO、DAPO、GSPO 等多种 RL 前沿算法,通过配置切换。
A.2 训练入口与配置系统
入口文件 verl/trainer/main_ppo.py:
1 |
|
run_ppo() 的初始化流程:
- 初始化 Ray 集群
- 加载 tokenizer 和模型配置
- 加载 Reward Manager(关键步骤,下面详述)
- 创建
RayPPOTrainer,传入 reward_fn(reward function) - 调用
trainer.fit()开始训练
配置文件 verl/trainer/config/ppo_trainer.yaml 定义了所有默认参数,命令行的 key=value 会覆盖对应默认值。
A.3 训练主循环(Rollout → Reward → Advantage → Update)
RayPPOTrainer.fit() 中的核心循环(verl/trainer/ppo/ray_trainer.py):
1 | for epoch in range(total_epochs): |
A.4 GRPO 优势估计的实现
核心代码在 verl/trainer/ppo/core_algos.py:
1 |
|
注意 index 参数就是每条数据的 prompt uid。GRPO 通过 rollout.n=4 让每个 prompt 生成 4 条回复,这 4 条的 index 相同,在此处被分为一组进行归一化。
A.5 Custom Reward Function 加载机制
veRL 通过 verl/trainer/ppo/reward.py 中的 get_custom_reward_fn() 动态加载用户自定义的 reward 函数:
1 | def get_custom_reward_fn(config): |
自定义 reward 函数必须遵循的签名约定:
1 | def compute_score( |
在本项目中,reward_tts.py 的 compute_score 从 solution_str 中解析出 speech token IDs,通过 HTTP 发送到 Triton server,拿到 reward 分数后返回。
A.6 PrimeRewardManager 并行打分
reward_model.reward_manager=prime 指定使用 PrimeRewardManager(verl/workers/reward_manager/prime.py):
1 |
|
prime 模式的核心价值在于并行化:每次 reward 计算涉及一次 HTTP 请求到 Triton server(token→wav→ASR 需要数百毫秒),64 路并行可以将 128 条数据的 reward 计算时间从数十秒压缩到数秒。
相比之下,naive 模式是串行调用,在这个场景下会成为严重瓶颈。
A.7 GRPO vs PPO 在 veRL 中的差异
veRL 框架通过配置自动处理 GRPO 和 PPO 的差异:
1 | # verl/trainer/ppo/ray_trainer.py |
| 环节 | PPO (GAE) | GRPO |
|---|---|---|
| Critic 网络 | 需要训练和推理 | 不需要 |
| 优势估计 | TD(λ) 递归,需要计算状态价值基线 | 组内均值归一化 |
| 采样策略 | 每个 prompt 1 条也能做 | 每个 prompt 需要采样 N 条 |
| reward 类型 | token-level 或 outcome | 通常 outcome(整条序列一个分数) |
| KL 惩罚 | 通常需要(防止 policy 崩溃) | 可选 |
| 显存占用 | 大(有 critic 模型) | 较小(无 critic 模型) |
| 实现复杂度 | 高 | 低 |
参考资料
- CosyVoice2: Scalable Streaming Speech Synthesis with Large Language Models — CosyVoice2 论文,本文分析的 TTS 模型架构
- CosyVoice GitHub — 阿里 FunAudioLLM 开源的 CosyVoice 项目,包含 GRPO 训练代码(
examples/grpo/cosyvoice2)- DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models — GRPO 算法的提出论文
- veRL (Volcano Engine Reinforcement Learning) — 字节跳动开源的 LLM 强化学习训练框架
- Proximal Policy Optimization Algorithms — PPO 算法原始论文
- SenseVoice — 阿里开源的语音识别模型,用于 Reward 计算中的 ASR 环节
- NVIDIA Pytriton — Triton Inference Server 的 Python 封装,用于部署 Reward 推理服务
- vLLM — 高性能 LLM 推理引擎,用于 Rollout 阶段的采样加速
- 本文标题:代码解读 | CosyVoice 代码研读(二):CosyVoice2 LLM + GRPO
- 创建时间:2025-12-18
- 本文链接:2025/2025-12-18-cosyvoice2-grpo/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!