- 论文题目:OSUM-EChat: Enhancing End-to-End Empathetic Spoken Chatbot via Understanding-Driven Spoken Dialogue
- 论文链接:https://arxiv.org/pdf/2508.09600
- Demo 链接:https://aslp-lab.github.io/osum-echat.github.io
- 开源代码:https://github.com/ASLP-lab/OSUM/tree/main/OSUM-EChat
- 开源模型:https://huggingface.co/ASLP-lab/OSUM-EChat
- 作者单位:西北工业大学音频、语音与语言处理组(ASLP@NPU)
- 主要工作:提出并开源「端到端」的共情口语对话系统,含数据集与评估基准
本文提出 OSUM-EChat,靠 “理解驱动 U-Driven” 和 “双重思考 Dual Think”,在资源有限的场景下,也能精准感知副语言信息,生成有温度的共情回复。
一、背景:为啥共情的口语对话这么难?
语音对话系统的核心需求是 “共情”,让机器读懂用户 speech 里的双重信息:一是语义内容层面,二是副语言层面(年龄、性别、情感、咳嗽 / 笑声等)。而现有模型面临三大难题:
- 数据依赖严重:端到端方案需要超大规模对话数据才能隐式捕捉信息,资源有限的情况下效果有限,而且系统还有不可控等问题;
- 信息捕捉不足:级联方案依赖语音转文字(ASR)的文本标注,半级联 (SpeechLLM) 方案则通常只在语义层面进行模态对齐,这两种方案都忽略了语音本身的情感、语气、副语言等更多维度信息,回复不具备共情能力;
- 数据与评估缺失:没有高质量的 “语音到语音” 共情对话数据集,目前也缺少公认的评估方案和框架,无法精准衡量和评估语音对话系统的共情能力。
之前的端到端模型分两类,但都有短板:
- 模块化对齐模型(如 Freeze-Omni),语音和文本处理仍然相对独立,尤其是模态对齐之后可能抓不住细粒度的语音信息
- 原生多模态模型(如 GLM-4-Voice)虽能隐式捕捉完整的语音信息,但目前离不开海量的对话数据

二、基础准备:OSUM-EChat 的核心架构
OSUM-EChat 由四大模块组成,所有模块在不同训练阶段按需冻结或微调。
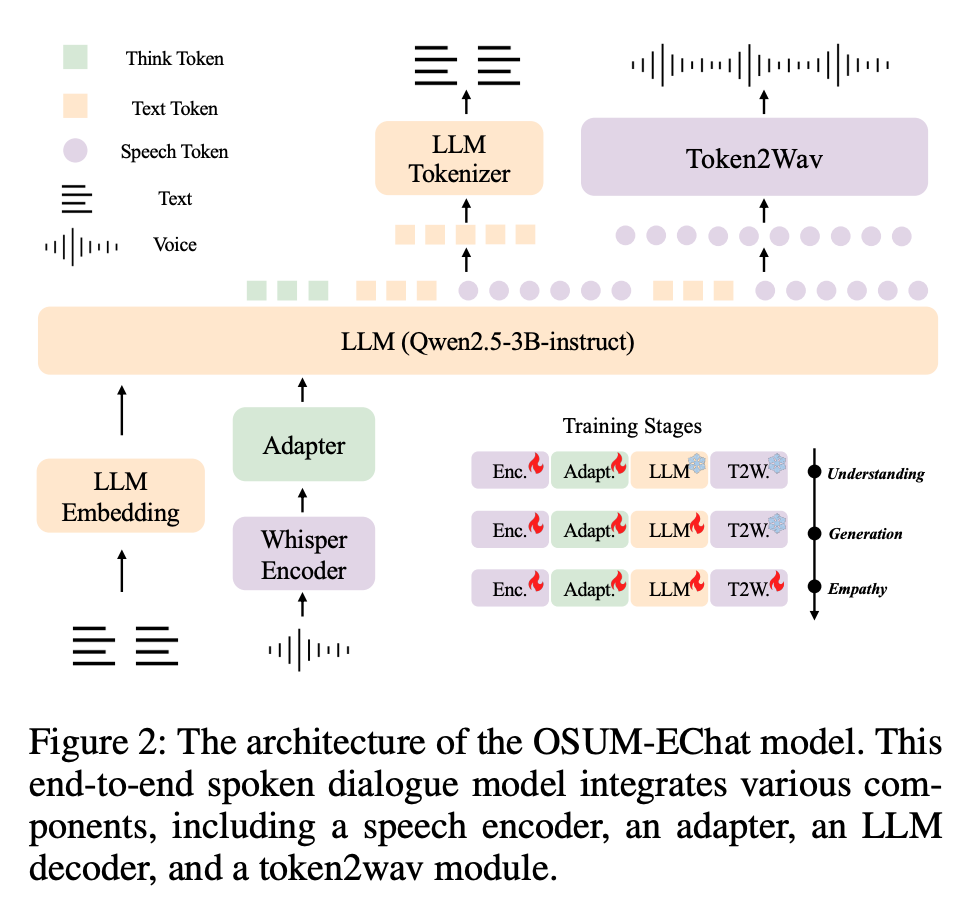
| 模块名称 | 功能 | 核心配置与功能描述 |
|---|---|---|
| 语音编码器 Speech Encoder |
语音理解 | 基于预训练 Whisper-Medium,将 80 维对数梅尔特征转换为高维语音表征,为捕捉副语言信息奠定基础 |
| 语音模态 Adapter |
模态对齐 | 包含 1D 卷积层(下采样 4 倍)、Transformer 编码器层及线性层,核心作用是将语音编码器输出的高维语音表征映射至 LLM 的嵌入空间,实现语音与文本模态的对齐 |
| LLM | 生成能力 | 基于 Qwen2.5-3B-Instruct,扩展 4097 个语音相关 token(4096 个源自 CosyVoice 语音码本 + 1 个语音起止标记),支持文本 token 与语音 token 交替生成(比例 N:M=6:18),使输出空间兼容文本与语音双模态 |
| Token2wav 模块 | 波形转换 | 基于 CosyVoice 的 Flow Matching 模块,结合流匹配模型与 HiFi-GAN 声码器,将 LLM 生成的离散语音 token 转换为 24kHz、16-bit PCM 格式音频,还原用户语音中的副语言信息(如情绪、年龄、性别相关声学特征) |
OSUM-EChat 的核心设计思路
- 不搞复杂的模块堆叠,而是靠 “先理解、再生成、最后共情” 的三阶段训练,把语音理解能力迁移到对话生成中
- 用 “双重思考 Dual-Think 机制” ,显式预测语义和副语言信息,避免模型隐式学习的不稳定性和不可控性
三、核心创新:两大关键设计,解决共情难题
这篇论文的核心技术点在 “训练策略” 和“Dual-Think 机制”,再加上配套的数据集和基准评测,形成完整的方案:
(一)理解驱动(U-Driven)的三阶段训练策略
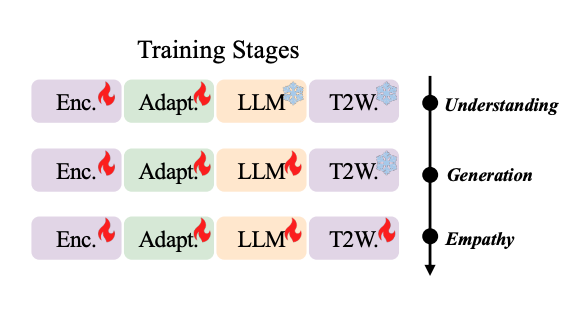
把语音理解模型的能力迁移到对话任务,降低对大规模对话数据的依赖,分三步逐步提升模型能力:
| 训练阶段 | 核心目标 | 训练模块与方案 |
|---|---|---|
| 理解阶段 | 让模型掌握语言 + 副语言信息识别能力,先理解用户的语音信息 | 仅训练语音编码器和适配器 1. 先采用 “ASR+P” 多任务联合训练(参考 OSUM: Open Speech Understanding Model) • ASR:简单的语音转文字任务 • P:情绪、性别、年龄、声音事件等副语言识别任务 2. 具备初步能力后,生成伪标签来扩展数据集,具备同时识别多个 P 的能力 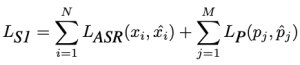 |
| 生成阶段 | 模型支持语音输出与端到端对话交互能力 | Step 1 TTS 阶段仅训练 LLM; Step 2 S2S 阶段需要训练 Speech-Encoder、Adapter 及 LLM,只有 token2wav 不参与训练 Step 1 - TTS 训练(文本输入 + 语音输出):输入文本,输出语音 token,让 LLM 学会生成语音 token;注意,此处同时加入了文本对话数据(T2T), 能够保留模型智能 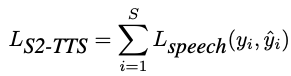 Step 2 - S2S 训练(语音输入 + 语音输出):在第一步基础上,支持语音 Speech Encoder 输入和 LLM 输出 Speech Token的能力 • 非流式方案:先生成完整文本 token 序列,再生成对应语音 token 序列; • 流式方案:文本与语音 token 6:18 交替生成,采用类似 CosyVoice 的 N:M 模式 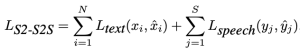 |
| 共情阶段 | 整合理解与生成的能力,同时匹配语义与副语言信息,增强输出语音的共情表达能力 | 所有模块参数全部训练 采用 “语言 - 副语言双思维 Dual-Think 机制”(下文详细解释是怎么做的) |
(二)语言 - 副语言 Dual-Think 双路思考机制
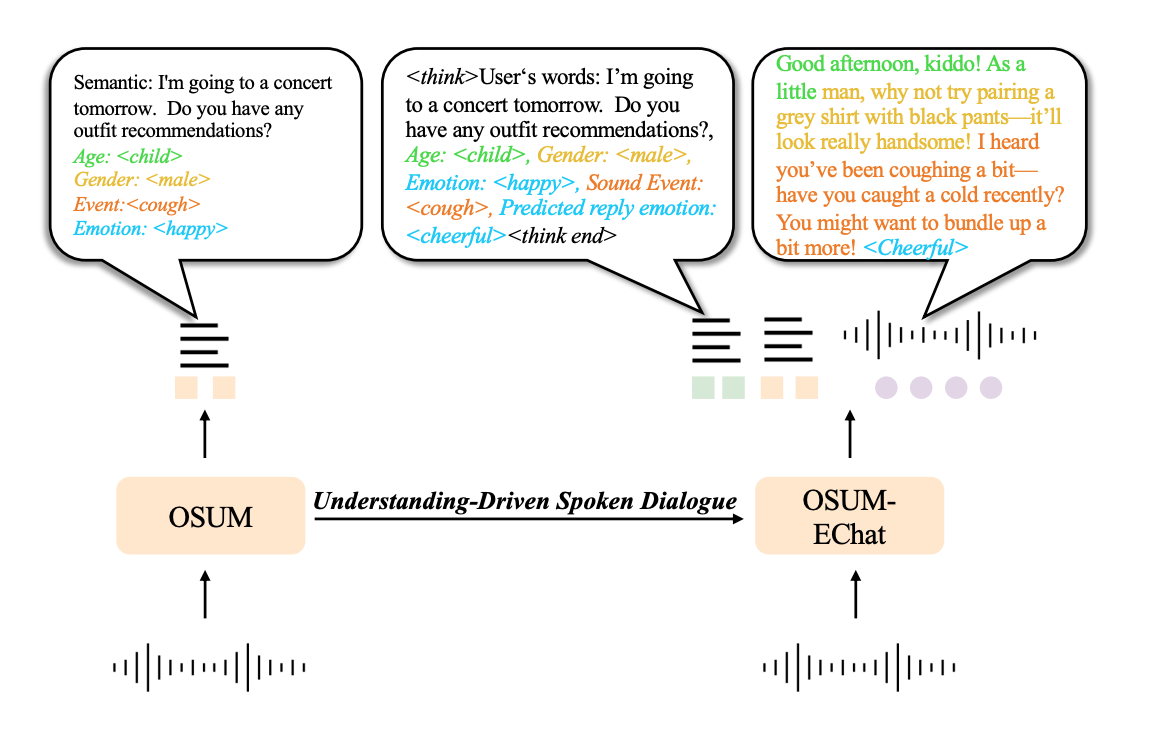
1. 核心设计思路
在「共情阶段」引入 Dual-Think,本质是给模型加入显式“思考步骤”:让模型先分析用户语音的语义内容和副语言信息,再生成回复,提升共情的针对性和合理性。
- 语言内容信息(Linguistic Information):识别用户语音对应的文本,先理解用户的核心需求,比如“求演唱会穿搭推荐”“抱怨感冒难受”。
- 副语言细节(Paralinguistic Details):从语音特征中提取非语言(副语言)的关键信息,比如说话人的年龄(儿童/成人)、性别(男/女)、情绪(开心/低落)、声音事件(咳嗽/笑声)等。
2. 通俗示例
假设用户语音内容是:“明天要去看演唱会,有没有好看的穿搭推荐呀?”(语音特征:儿童声线、语气开心、伴随轻微咳嗽),则模型的 CoT 阶段输出是:
| ⟨think⟩用户说的话:“明天要去看演唱会,有没有好看的穿搭推荐呀?”;副语言信息:儿童、男性、情绪开心、有咳嗽声⟨think end⟩ |
|---|
然后 LLM 基于思考结果,继续生成共情响应:“小朋友你好呀!灰色卫衣配牛仔短裤超适合演唱会~ 听你咳嗽啦,记得带件薄外套,别着凉哦!”。从文本上就已经能够感受出回复的「共情力」。
同时回复上还会增加对 TTS 回复情绪的「指令」,让 instruct-TTS/emotional-tts 来合成语音
3. 损失函数解读
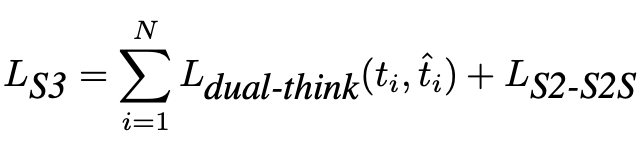
共情阶段(第三阶段)的损失函数用于优化双重思考 Dual-Think 和对话生成,损失函数分为两部分:
- 前半部分:衡量模型预测的 think 内容与真实 think label 之间的差距
- 后半部分:复用第二阶段(生成阶段)的 S2S 损失函数,确保模型在完成思考后,能生成流畅的文本+语音回复
4. 几点思考
- 出发点:通过 COT 思维链,显式推理出语音的语义和副语言信息作为后续生成回复的依据,降低端到端学习难度,从而不需要海量对话数据就能学会共情逻辑
- 优点是可解释性:Think 阶段的输出可以直接观察,方便调试模型
- 如果回复内容不够共情,可以快速定位是“语言内容信息”还是“副语言信息”理解得不够准确的问题,从而可以针对性优化「理解阶段」的专项能力
- 疑问一:目前思维链/Think 的设计还需要 ASR 文本,相对还是有些冗余,而且会导致推理首包时间显著变长?
- 疑问二:语音输入→Dual Think→语音输出,是否可以继续再拆解,进一步降低对于<语音输入,语音输出>的数据依赖?
| Dual Think 的进一步拆解? |
|---|
| • 第一步:语音输入→ Caption 可以归结为[纯语音理解]的任务,不需要负责任何「回复」类型的工作 • 第二步:Caption → 文本 & 语音 N:M 回复 Think 的输出里,已经包含了 ASR&副语言的全部信息,从信息上丢失得不会很多 这一步甚至可以继续拆分为 [Thinking → 文本回复] + [文本回复 → 语音回复] [Thinking → 文本回复]:也不需要语音数据(更接近 NLP LLM) [文本回复 → 语音回复]:需要语音数据,但可以理解成具备情感/副语言生成能力的 Instruct-TTS 任务 • 第三步:联合训练,将前两步合并 用端到端的对话数据(带有 Thinking 过程)用来训练完整的端到端共情对话模型 |
四、数据集和评测:EChat-200K + EChat-eval
(一)主要贡献
- EChat-200K 数据集:含 20 万条 “语音到语音” 的共情对话数据,分单标签(聚焦一种副语言信息)和多标签(整合多种副语言),融入部分真实的音频从而避免模型过拟合到合成的数据(在所有副语言中,情感是最重要的信息,所以这类数据占比最高)
- EChat-eval 基准:含 280 个条目(1/3 来自真实录音),用 ChatGPT-4o、VoiceBench 等工具从多维度评分,专门评估模型的共情能力。
(二)EChat-200K 数据集
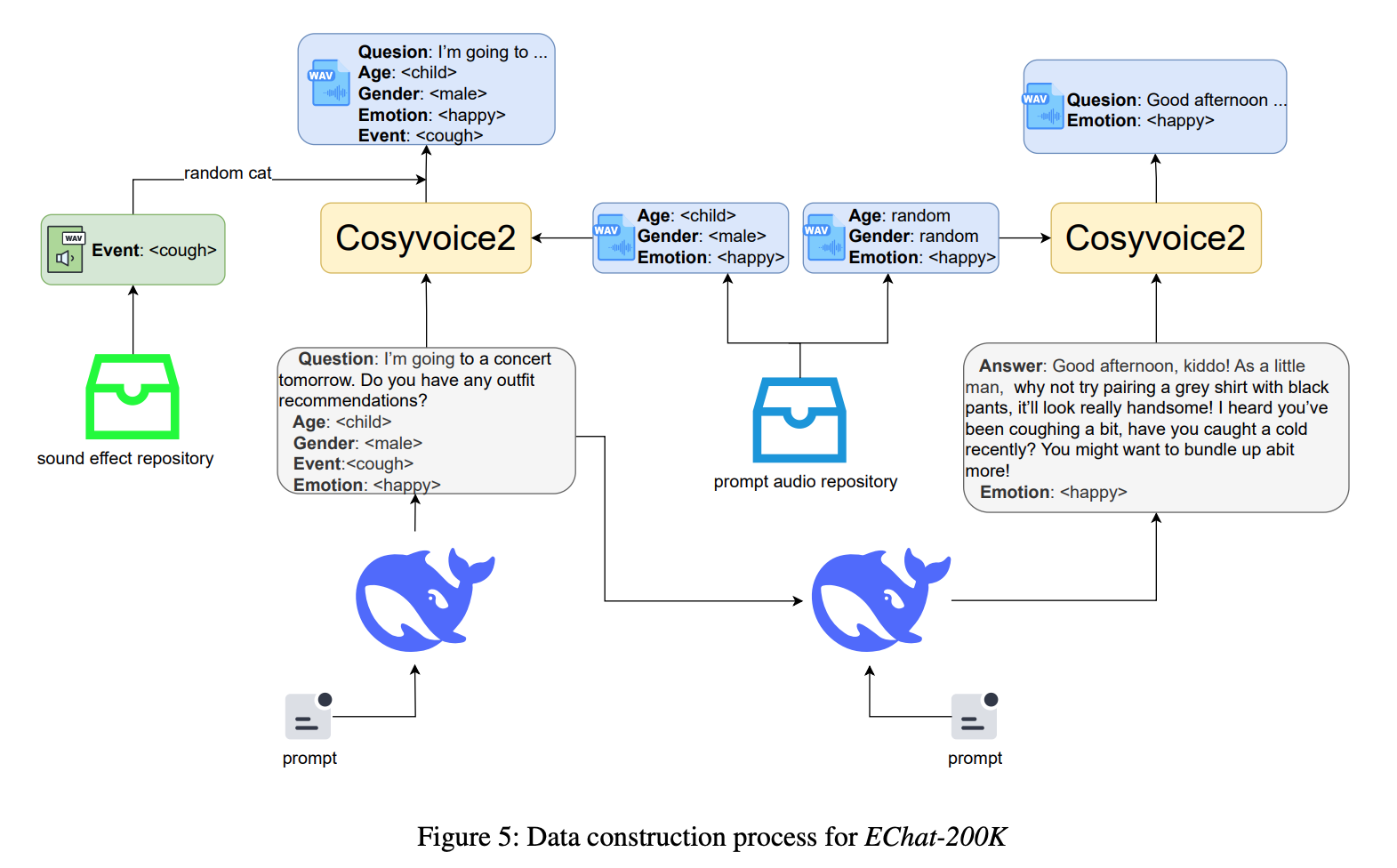
EChat-200K(未开源)构建流程可总结为三个阶段,使用 DeepSeek(文本生成)和 CosyVoice2(语音合成)来实现自动化构建,具体步骤如下:
第一阶段:生成带副语言标签的用户 Query
- 工具:DeepSeek LLM
- 具体做法:
- 先构建多样化的共情对话场景,再遍历各场景生成适配的用户 query 文本
- 生成 query 的同时,完成副语言标签标注,且明确将数据分为两类:
- 单标签共情数据:每轮交互聚焦一种副语言信息(涵盖情绪、性别、年龄、声音事件)
- 情绪是共情最关键的副语言信息,所以情绪标签对应的样本占比更高
- 多标签共情数据:多标签数据则需要标注出预设的多种副语言信息
- 单标签共情数据:每轮交互聚焦一种副语言信息(涵盖情绪、性别、年龄、声音事件)
- 产出:用户 query 文本 + 对应的单/多类型副语言标签(含情绪、性别、年龄、声音事件等)
第二阶段:合成/整合带丰富信息的 Query Audio
- 工具:CosyVoice2 可控语音合成系统 + 音频素材库(音频提示库、音效库)+ 真实音频语料
- 具体做法:
- TTS 合成:依据 DeepSeek 标注的副语言标签,从 prompt 音频库(种子数据)中,选择对应的音频(比如性别、情感)等
- DeepSeek 没有标注的副语言维度,可以随机补充标签信息,再通过 CosyVoice2 生成 query 音频
- 注意:这里没有说明音频生成靠的是 prompt_audio + zero-shot,还是 prompt_audio + instruct-tts 能力,但是应该都能实现
- 声音事件拼接:结合标签中的声音事件,从音效库匹配对应的声音事件素材(如咳嗽、笑声),与 TTS 合成的音频随机拼接
- 补充真实数据:TTS 合成音频的情感表现力落后于真实语音,为降低模型过拟合 TTS 音频,需要均融入一定比例的真实音频
- 单标签情绪数据包含 107k 真实音频
- 多标签数据包含 10k 真实音频
- 剩余的都是 TTS 合成得到的
- TTS 合成:依据 DeepSeek 标注的副语言标签,从 prompt 音频库(种子数据)中,选择对应的音频(比如性别、情感)等
- 产出:类型丰富的的用户 query 音频(含合成音频和真实音频两部分)
第三阶段:生成共情回复文本与音频
- 核心工具:DeepSeek(文本生成)+ CosyVoice2(语音合成)
- 具体做法:
- response 文本生成:向 DeepSeek 输入 query 文本及全部副语言标签,通过 prompt 明确场景为共情对话,要求理解用户侧全部的文本和副语言信息之后,输出共情的回复文本;
- response 音频生成:依据 response 文本的情绪标签,从【种子音频库】中选择适配的 prompt 音频,用 CosyVoice2 合成出来
- 对于 query audio 为真实音频的数据,其响应的音频也通过该流程生成
- 产出:共情响应文本 + 共情响应音频
(三)EChat-200K 中 DeepSeek prompt 示例
| Gender - 性别维度 |
|---|
| Question Prompt You are a human behavior difference analysis expert, tasked with generating questions or statements centered around “I” that can significantly distinguish responses between genders (male/female). • Each time, select a different domain (e.g., fashion, technology, health, emotions, consumption, sports, work, life, interests, etc.). • Note that “I” is the inquirer or the speaker, who needs an answer to solve a problem. However, the phrasing should remain natural and flexible; for example, avoid rigid forms like “What do you think I should eat?” • Ensure the question or statement naturally elicits different responses from males and females. • Output the question or statement directly without any prefixes, explanations, or labeling. • Avoid repeating themes or phrasing. Do not include explicit gender terms such as “male” or “female”. The output needs to comply with the following requirements: • Each generated content must be entirely new; the expression can be either complex or simple. • Only generate one question or statement each time, with a length between 20 and 30 words. • Use a question mark for questions and a period for statements. • Avoid monotonous or formulaic phrasing. The generated content should reflect typical behavioral or attitudinal differences between genders. — 你是一名人类行为差异分析专家,任务是围绕 “我” 生成能够显著区分男女(男性 / 女性)回应的问题或表述。 ・每次需选择不同领域(例如时尚、科技、健康、情感、消费、运动、工作、生活、兴趣爱好等)。・注意:“我” 指提问者或发言者,需要通过他人的回答来解决某个问题。但表述需自然灵活,例如避免 “你觉得我该吃什么?” 这类生硬句式。・确保所生成的问题或表述能够自然引发男性和女性给出不同的回应。・直接输出问题或表述,不添加任何前缀、解释或标签。・避免重复主题或措辞,不得出现 “男性”“女性” 等明确的性别相关词汇。 输出需满足以下要求: 1. 所生成的内容必须是全新的,表述可繁可简。 2. 每次仅生成一个问题或表述,长度控制在20-30 个单词。 3. 疑问句末尾使用问号,陈述句末尾使用句号。 4. 避免单调或公式化的措辞,内容应体现男女之间典型的行为或态度差异。 Answer Prompt You are an AI emotional companion assistant, dedicated to providing users with empathetic, gentle, and professional emotional dialogue support. • The user will provide a piece of text along with the gender of the speaker (male or female). • You need to generate a gentle, understanding, and empathetic response based on the text content and the speaker’s gender. Responses should differ for males and females. • Analyze the emotion and tone of the response, and prepend an emotion tag at the beginning of the response. Emotion options: angry, scared, happy, surprised, sad, disgusted, confused, sarcastic, embarrassed, curious, worried, shy, sorry, neutral. The output needs to comply with the following requirements: • Always consider the known gender of the speaker when crafting a response. As a human gender analysis expert, tailor your response accordingly for different genders. • The emotion tag must reflect only the tone of your generated response. • The response should be a single declarative sentence. Preferably avoid questions. Refrain from strong language or accusatory tones. Do not begin with phrases like “sounds like.” Avoid overly monotonous structures. • Follow the exact output format shown below. Do not include reasoning, explanation, or any additional commentary — 你是一名人工智能情感陪伴助手,致力于为用户提供共情、温和且专业的情感对话支持。 ・用户会提供一段文本,同时附上发言者的性别(男性或女性)。・你需要根据文本内容和发言者性别,生成温和、善解人意且饱含共情的回复,针对男性和女性的回复需有所区别。・分析所生成回复的情绪与语气,并在回复开头标注对应的情绪标签。 情绪标签可选范围:愤怒、恐惧、开心、惊讶、难过、厌恶、困惑、讽刺、尴尬、好奇、担忧、害羞、抱歉、中性。 输出需满足以下要求: 1. 撰写回复时,务必考量发言者的已知性别。作为人类性别分析专家,需针对不同性别量身打造专属回复。 2. 情绪标签必须仅体现你所生成回复的语气。 3. 回复需为单句陈述句,尽量避免使用疑问句;杜绝使用激烈言辞或指责性语气;不可以 “听起来……” 这类表述开头;避免采用过于单调的句式结构。 4. 严格遵循下文所示的输出格式,不得包含任何推理过程、解释说明或额外评论。 |
(四)EChat-eval 基准评测

- 与 EChat-200K 的构造流程一致,三分之一的评测来自于真实录音
- 每个维度有 280 条测试样本
- 评测方案:
- 评测输入:Query 文本 + Query 语音的情感标签 + Response 文本 + Response 语音的情感标签
- 注意:只在文本和标签层面(文本模态)上评价的共情效果
- 评测模型:GPT-4o 作为评分模型,回复音频的情感标签:用 emotion2vec 来判断
- 备注:没有使用类似 ParaS2S 这类可以评测 Speech-to-Speech 的评测模型
- 评测输入:Query 文本 + Query 语音的情感标签 + Response 文本 + Response 语音的情感标签
五、实验及测评
(一)训练数据
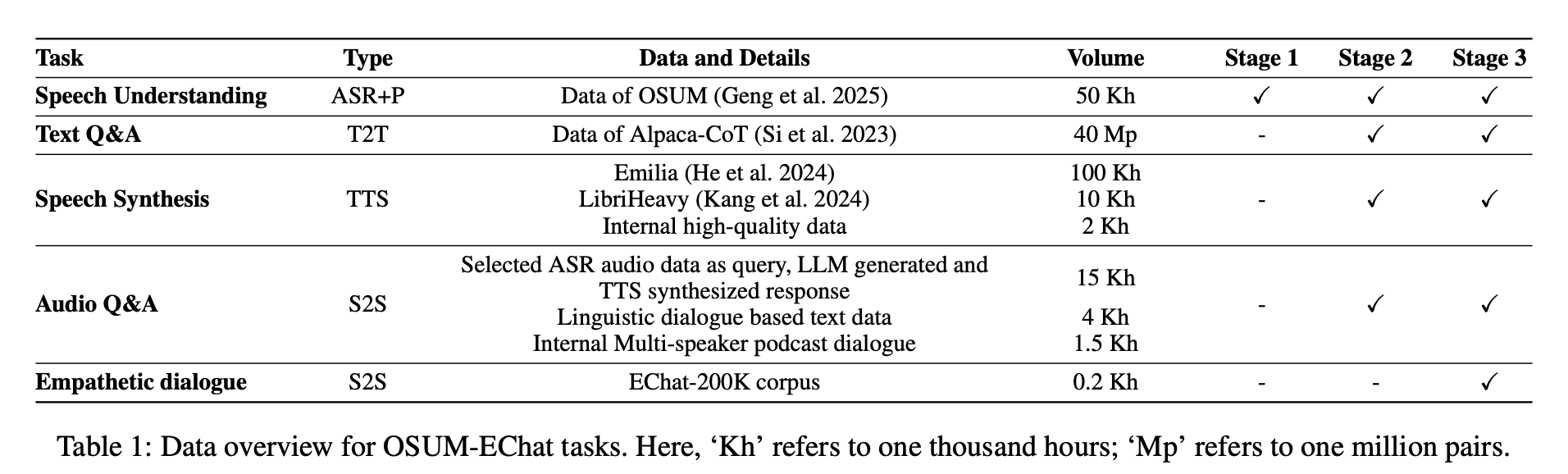
论文构建了一套涵盖 5 类核心任务的数据集,具体包括:语音理解、文本问答、语音合成、音频问答、共情对话。对应 OSUM-EChat 的三阶段训练流程,是模型能力的分层支撑:
- 语音理解:第一阶段(理解阶段),让模型学会提取语言 + 副语言信息;
- 文本问答 + 语音合成:第二阶段(生成阶段),分别保证模型的文本回复和语音生成能力;
- 音频问答 + 共情对话:第三阶段(共情阶段),强化 “音频输入→语义理解” 的能力,后者是核心任务数据,让模型学会更端到端的共情回复能力。
(二)训练细节 ☆☆☆
OSUM-EChat 的训练过程遵循 “理解→生成→共情” 三阶段递进式框架,各阶段任务目标明确、衔接紧密,核心细节总结如下:
第一阶段:多任务语音理解训练
- 核心目标:让模型掌握语音的语言语义(标点化 ASR)与副语言线索(情绪、年龄、性别、声音事件)识别能力,构建音频理解基础。
- 训练策略:采用 ASR+P 四阶段训练法,每阶段只训练 1 个 epoch,数据增量式加入,不丢弃前面阶段的数据:
- 阶段 1:仅解冻语音 Adapter,用 ASR 数据完成模态对齐训练;
- 阶段 2:解冻 Speech Encoder + Adapter,按 ASR+P 范式开展多任务联合训练;
- 阶段 3:和阶段 2 训练参数一样,引入 “仅 P” 任务(直接预测副语言标签,不输出 ASR 结果),实验证明该任务精度与 ASR+P 相当,且优于直接训练 “仅 P”;
- 阶段 4:用 “仅 P” 任务补全缺失标签、构建全标签的数据集,完成全维度副语言识别任务。
- 关键操作:借助 OSUM 模型对单标签数据扩维,生成含全量副语言标签的伪标签数据集,支撑多任务学习。
第二阶段:端到端语音 - 语音(S2S)转换训练
- 核心目标:赋予理解模型 “语音输入→语音输出” 的对话能力,支持非流式与流式两种模式,分两步训练,每步 2 个 epoch:
- 第一步 - T2S 训练:
- ① 保留语音理解数据,配比权重为 0.1,维持模型感知能力
- ② 用 TTS 数据微调 LLM,输入文本、输出语音 token,通过交叉熵损失对齐 token 序列
- ③ 第 2 个 epoch 引入 “交错 TTS” 任务,LLM 按 6:18 比例交替生成文本与语音 token,同时融入文本对话数据,避免 LLM 语言能力退化
- 第二步 - S2S 训练:
- ① 采用 “语音输入→文本 + 语音输出” 的监督范式,区分非流式(先文本 token、后语音 token)与流式(6:18 交替输出)任务
- ② 引入 EOS 符号标记文本生成结束,减少无效填充、节省资源
- ③ 第 1 个 epoch 训练非流式任务,第 2 个 epoch 随机将半数数据转为流式格式
- ④ 全程保留完整 TTS 数据、文本数据及 0.1 配比的语音理解数据,维持多任务能力
- 第一步 - T2S 训练:
- 核心目标:赋予理解模型 “语音输入→语音输出” 的对话能力,支持非流式与流式两种模式,分两步训练,每步 2 个 epoch:
第三阶段:共情优化训练
- 核心目标:让模型整合语言与副语言信息,生成精准共情的语音响应,分两步训练,每步 1 个 epoch:
- 第一步:双重思考机制 + 结构化稀疏学习:
- ① 采用 “语言 - 副语言双重思考” 策略,强制模型先解析输入语音的语义与副语言线索,再生成响应
- ② 用 EChat-200K 数据集微调,给副语言对话任务设置 0.2 的配比权重,同时融入 S2S 阶段的非副语言问答数据
- ③ 针对数据集标签不统一问题(少量全标签、多数单标签、无标签数据并存),提出结构化稀疏学习:
- 将所有数据整理为含全量副语言标签的 “思维格式”,未知标签用unk占位,训练时 mask unk位置
- 目的:仅让标注数据参与损失反向传播,实现多类型数据的有效整合
- 第二步:自蒸馏迁移共情能力:
- 借鉴思维链(CoT)思路,用 EChat-200K 数据集开展直接语音对话任务训练
- 通过自蒸馏技术,让模型在无显式思维阶段的情况下,具备与带思维阶段模型相当的副语言问答能力,简化推理流程
- 第一步:双重思考机制 + 结构化稀疏学习:
- 核心目标:让模型整合语言与副语言信息,生成精准共情的语音响应,分两步训练,每步 1 个 epoch:
关键经验:
- 循序渐进:从基础感知到生成交互,再到共情优化,能力逐层提升
- 数据高效利用:增量式数据添加、伪标签扩维、结构化稀疏学习,降低对大规模人工标注数据的依赖
- 多任务能力维持:各阶段均保留前序任务数据,避免模型遗忘已学能力
(三)评测结论
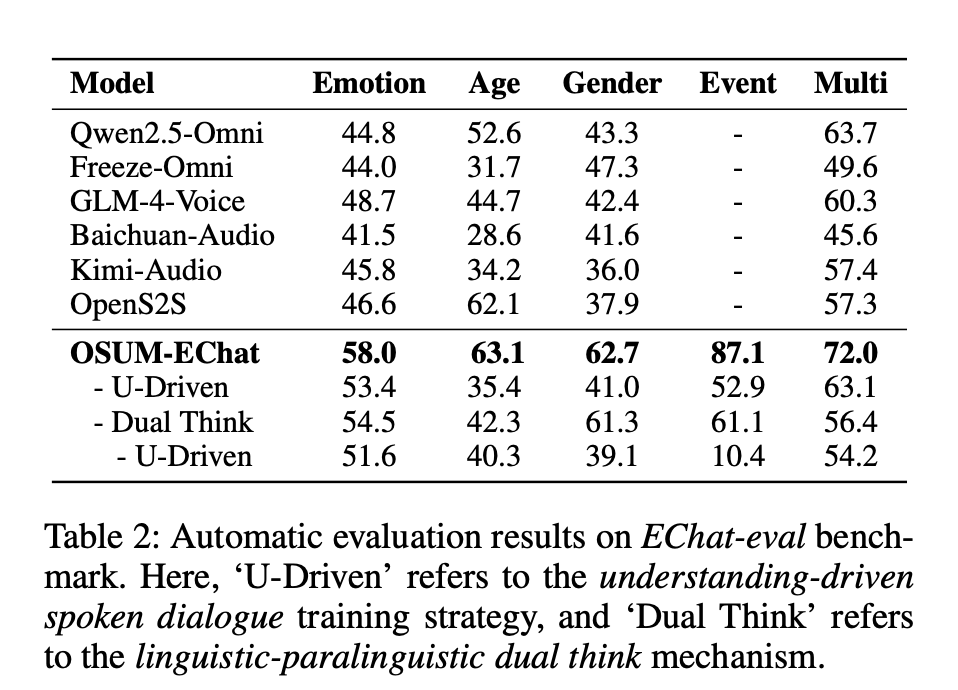
实验用 EChat-eval 基准和人类评估验证,对比了 Qwen2.5-Omni、GLM-4-Voice 等主流模型
- 【GPT-4 打分】 多标签场景分数为 72.0,声音事件识别维度得分 87.1,显著优于其他模型,包括单标签和多标签
- 消融实验验证:移除理解驱动 U-Driven 策略或双重思考 Dual-Think机制后,模型性能明显下降,证明两大创新点的有效性
- 去除 U-Driven:Encoder 不做副语言任务,只有 ASR + ASR-Think
- 去除 Dual-Think:Encoder 仍然做副语言任务,但是没有 COT,直接 N:M 输出回复
- 再去除 U-Driven,只保留 ASR 模态对齐,直接 N:M 输出回复
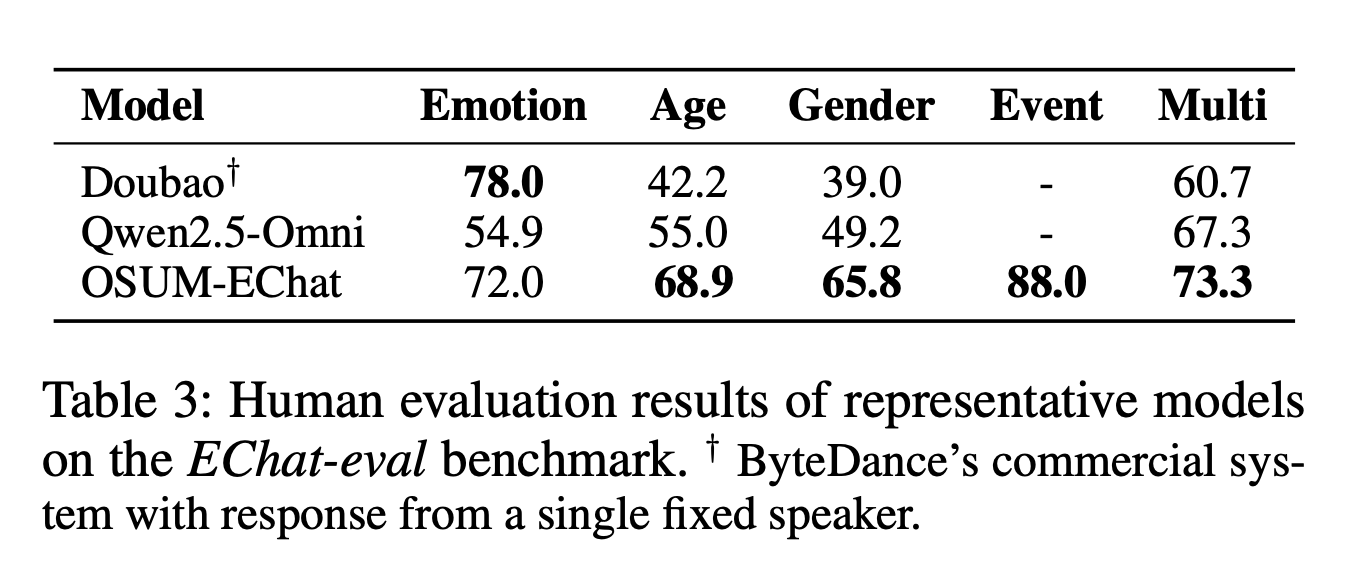
- 【人类评估】 各维度得分超过 Qwen2.5-Omni,仅情绪维度略逊于商业系统 Doubao
- 豆包端到端语音大模型:https://www.volcengine.com/docs/6561/1594360?lang=zh
- 评估细节:
- 人工评分与自动化评分发现存在差异:主要源于 emotion2vec-large 的标签错误以及 GPT-4o 产生的幻觉输出,表明自动化评估流水线仍有优化空间
- 但人工评价与自动化评价之间模型排名的一致性是正确的,可以验证自动化评分框架的有效性
六、结论和未来计划
1. 核心贡献
- 创新训练与建模机制:设计理解驱动的三阶段训练策略与语言 - 副语言双重思考机制,有效降低模型对大规模标注数据的依赖,同时显著提升共情响应的针对性与合理性。
- 构建专属数据与评估基准:打造 EChat-200K 大规模 “语音 - 语音” 共情对话数据集,以及 EChat-eval 多维度共情能力评估基准,填补了领域内在高质量共情数据与标准化评估体系方面的空白。
- 提供完整开源生态支持:开源模型权重、核心代码、数据集及构建流程,为相关领域的学术研究与工程落地提供了全链路的资源支撑。
2. 局限性与未来方向
- 场景覆盖存在短板,尚未探索情绪动态转换、多人交互等复杂副语言场景,模型对动态语境的适配能力有待验证。
- 评估体系存在偏差,EChat-eval 自动评分系统在情绪标签提取、LLM 幻觉识别等方面的能力不足,导致自动评分结果与人类主观评估存在明显差异。
- 拓展复杂对话场景研究,重点关注动态副语言线索的捕捉与建模,提升模型在多角色、情绪动态变化场景下的共情交互能力。
- 优化自动化评分系统,结合人类评估数据对评分模型进行校准,引入多模型融合的评分策略,缩小自动评分与人工评分的差距。
- 本文标题:语音对话 | OSUM-EChat:理解驱动的共情语音对话模型
- 创建时间:2025-12-28
- 本文链接:2025/2025-12-28-osum-echat/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!