分享题目:面壁小钢炮:MiniCPM-o 4.5(9B) 首个全双工全模态大模型 + 边看边听主动说
分享者:姚远博士(面壁智能多模态首席科学家、清华大学助理教授)
官方信息:
- github: https://github.com/OpenBMB/MiniCPM-o
- 模型代码:https://huggingface.co/openbmb/MiniCPM-o-4_5/blob/main/modeling_minicpmo.py
- demo: https://openbmb.github.io/minicpm-o-4_5(demo 效果仅体现语音生成能力,效果优异)
会议记录:通义听悟 - 会议转写 & B 站 - 直播回放
一、模型背景与研发主体
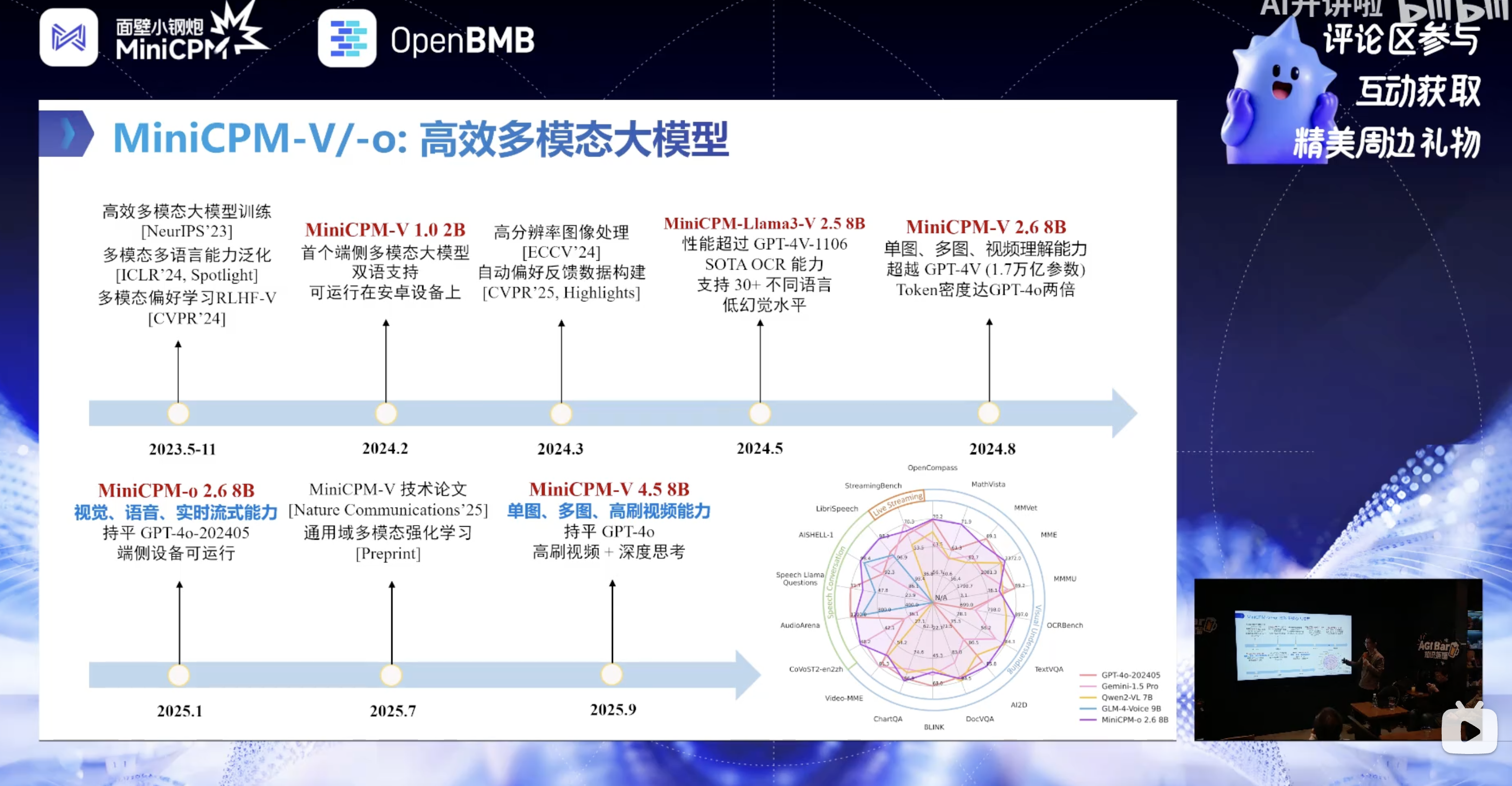
- 研发与开源社区:MiniCPM-o 4.5 由 OpenBMB 开源社区推出,该社区 2022 年由面壁智能 + 清华大学 THUNLP 实验室(刘知远)联合发起。愿景是让大模型普惠大众,聚焦端侧智能研发;开源模型总下载量超 2300 万,Hugging Face 上累计超 10 万 star。
- 模型定位:端侧全模态旗舰模型,是 MiniCPM 系列多模态模型的最新版本,主打边看-边听-主动说的类人多模态感知交互能力。核心参数量 8B,融合多模态模块后整体 9B,实现同尺寸下全模态、视觉、语音能力领先。
- 系列各版本模型发展
| 版本 | 核心能力突破 | 行业价值 |
|---|---|---|
| 早期版本 | 多端侧流畅运行、高清图像 OCR | 首个实现端侧多模态模型落地 |
| MiniCPM-o 2.6 | 视觉 + 语音 + 实时流式能力、原生记忆 / 推理 | 开源社区首个流式全模态模型,对标 GPT-4o/Gemini Live |
| MiniCPM-o 4.5 | 全双工全模态、自主交互、端到端语音克隆 | 突破传统轮次交互,实现类人多模态感知交互 |
二、核心技术理念:突破传统多模态模型的交互制约
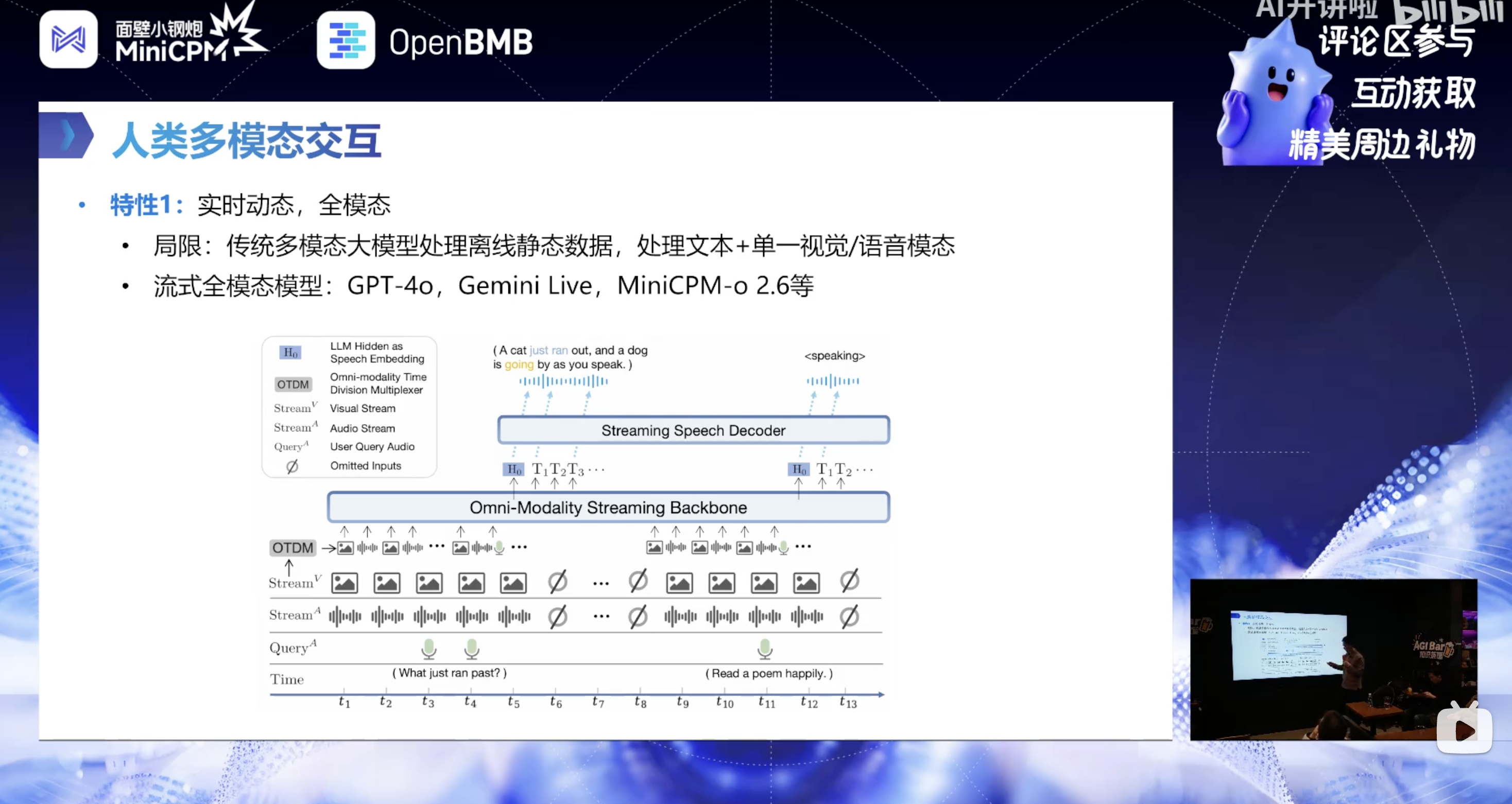

1. 传统多模态模型的核心局限
传统模型继承 LLM 一问一答的轮次交互逻辑,存在以下核心问题:
- 处理离线静态数据,即使是视频也需先固定再上传,无实时动态处理能力;
- 模态受限,多为文本 + 单一视觉 / 语音模态,非真正的全模态;
- 输入输出阻塞,模型开始生成后、无法感知外部信息,且说话时机由外部工具(VAD、唤醒词、按钮)控制,没有自主的交互能力。
2. 人类多模态交互的核心特性(模型设计目标)
- 实时动态 + 全模态:天然处于多模态信息流中,并行接收视觉、音频等信号,低延迟反应;
- 并行信息流 + IO 互不阻塞:输入输出同步进行,可根据外部反馈及时调整行为;
- 交互自由性:说话时机、轮次不受限,可即时回复、打断、主动插话;
- 自然低延迟语音交互:语音表达有韵律、拟人度,可根据场景调整语气。
3. 传统多模态模型 VS MiniCPM-o 4.5 VS 人类交互「总结对比」
核心解决传统模型 “继承语言模型一问一答逻辑,与人类交互脱节” 的问题。
| 对比维度 | 传统多模态模型 | MiniCPM-o 4.5 实现效果 | 人类多模态交互(目标&愿景) |
|---|---|---|---|
| 数据处理 | 离线静态(视频需固定后上传) | 几十毫秒级别粒度进行「时间对齐」,实时处理音视频流 | 实时动态(持续接收多模态流) |
| 模态支持 | 文本 + 单一视觉 / 语音(模态阻塞) | 全模态并行处理,支持通用类型的音频(非仅语音) | 全模态(视 / 听 / 触 / 嗅,并行感知) |
| 输入输出 | 阻塞(输出期间不感知外部信息),区分 AI 的 turn 和用户的 turn | 全双工 IO,边看边听边说,可实时调整表达 | 互不阻塞(边输入边输出,实时根据各类信息的变化而调整) |
| 交互时机 | 外部工具控制(VAD / 唤醒词 / 按钮) | 高频语义判断(每一秒进行判断),自主决定说话时机 | 自主决定(可即时 / 主动 / 打断 / 插话) |
| 语音交互 | 固定音色、无韵律控制、长语音易出错 | 字级别韵律控制、端到端克隆、1 分钟长语音错字率减半 | 自然韵律、个性化表达、低延迟 |
4. 流式全模态模型的前期探索
2025 年出现 GPT-4o、Gemini Live、MiniCPM-o 2.6 等流式全模态模型,初步实现实时流式、低延时交互,具备原生记忆和初步推理能力,但未解决输入输出阻塞和自主交互的核心问题。
| 模型类型 | 核心特征 |
|---|---|
| 流式全模态 | 「实时接收 + 单次生成」→ 仍为轮次交互 |
| 全双工全模态 | 「实时接收 + 持续生成 + 实时调整」→ 类人的连续交互 |
三、核心技术架构与创新点
1. 端到端全模态架构

整体设计
采用8B 骨干 LLM + 轻量级模态编解码器的模块化架构,兼顾文本能力的保留与运行效率:
- LLM 聚焦高级语义处理,无需处理原始模态信息,最大程度能保留文本能力;
- 视觉 / 音频编码、语音解码由几百 M 级轻量级模块实现,避免主干模型处理高频模态 token 导致的效率低下。
关键连接方式
LLM 与模态编解码器通过隐层表示进行逐 token 紧密端到端连接:
- 输入端:各模态编码的隐层结果均输入 LLM;
- 输出端:文本 token + 隐层表征,逐 token 传入语音生成模块;
- 作用:实现细粒度控制,让模型充分吸收全模态数据的丰富知识,突破传统稀疏连接或级联方案的能力上限。
稀疏连接 vs 紧密连接
| 对比维度 | 稀疏连接 | 紧密连接 |
|---|---|---|
| 信息交互粒度 | 【粗粒度】只使用全局层面的 embedding,一次性注入LLM | 【细粒度】输出逐 token 级序列隐层特征,与LLM token逐位置时间对齐,细粒度融合隐含特征与文本 |
| 连接方式与耦合性 | 【级联式结构】不共享隐层,模块之间耦合很弱 | 【端到端结构】隐层级深度交互,模态特征全程参与LLM计算,可梯度回传,耦合紧密 |
| 输出端连接方式 | LLM 仅输出文本token,语音生成与模态上下文脱钩 | LLM 输出文本token+逐token隐层表征,语音生成受模态表征影响,输出端紧密耦合 |
| 注意力与信息流 | LLM信息弱对齐、注意力学习难度大,易丢失细粒度对应关系 | 模态与文本序列对齐,实现词-图像、字-音频的时间对齐,更容易学习全模态知识 |
| 总结性概括 | 仅输入端粗粒度一次性注入模态特征,无逐token隐层交互,非端到端耦合 | 隐层级逐token对齐、端到端融合,输入输出细粒度交互,突破传统级联上限 |
2. 首个全双工全模态大模型:解决 IO 阻塞问题
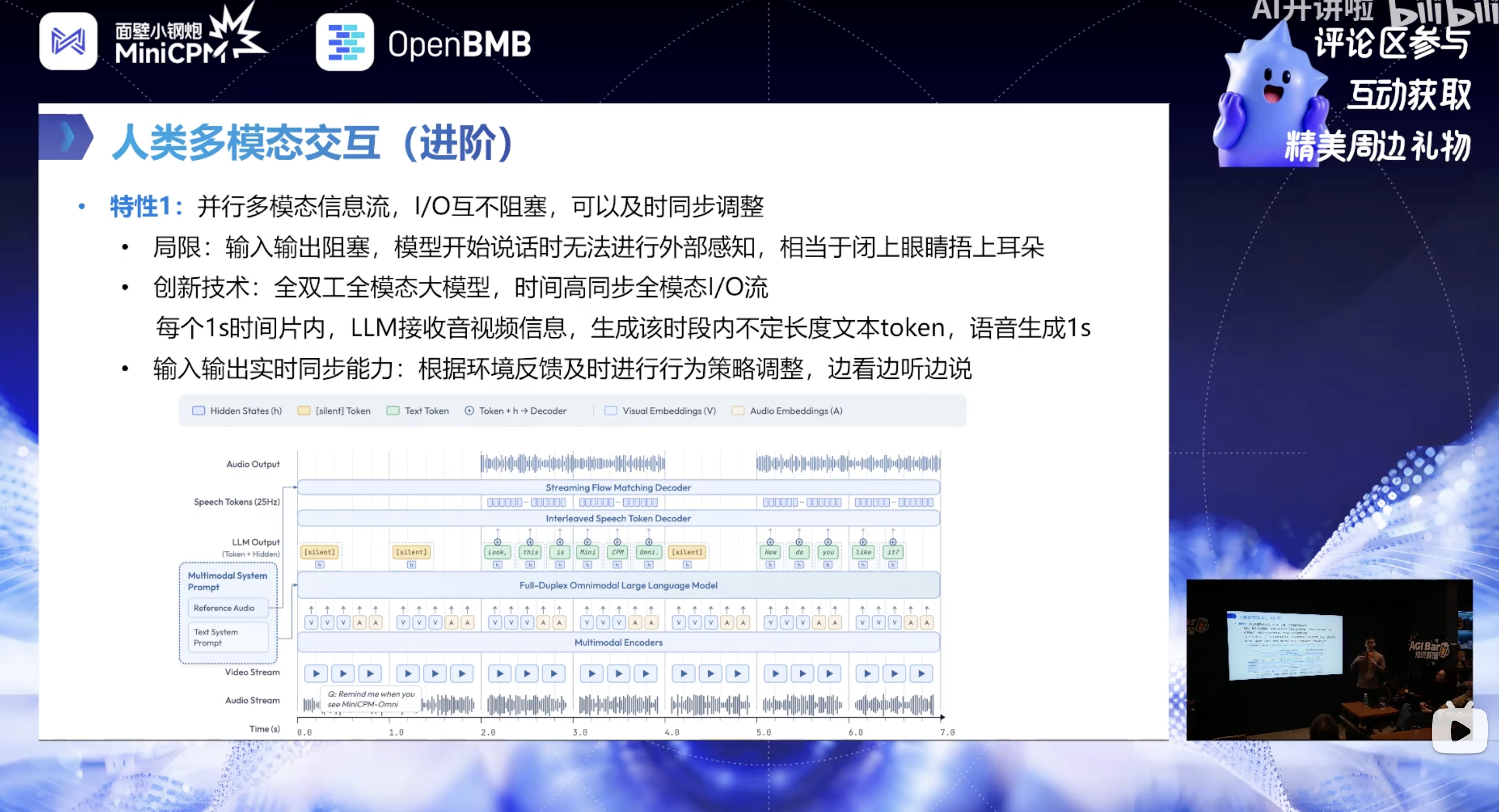
全双工概念迁移
将通信领域的全双工概念引入大模型:
- 单工:单向信息传输;半双工(如对讲机):双向传输但同一时间仅一方可发送;
- 全双工(如手机通话):时间高同步的全模态 IO 流,模型可同时接收多模态输入、生成输出,输入输出互不阻塞。
核心实现手段
- 时间概念建模:将输入输出与时间严格绑定,实现几十毫秒级数据对齐,每秒的视频、音频输入与文本、语音输出在时间轴上精准匹配;
- 时分复用:将并行的多模态信息流切分为毫秒级时间切片,宏观维度并行互不阻塞;
- 每秒固定处理逻辑:每个 1 秒时间片内,模型接收该时段的所有视频 / 音频信息,生成不定长度文本 token + 固定数量语音 token,仅生成当前秒的实时信息。
核心能力:输入输出实时同步
模型可根据环境反馈及时调整行为策略,真正实现边看边听边说,区别于传统模型 “一次性生成所有信息再逐步输出” 的静态模式。
- 人的输入和输出是不阻塞的,处理的是并行的信息流,根据实时环境反馈进行实时策略变化&及时调整,并非开口后阻塞外部信息,可边说边察言观色;
- I/O 互相不阻塞的核心是时分复用,时间概念为核心:输入输出在时间上严格绑定,实现几十 ms 粒度对齐;1s 时间内,LLM 输入切片后的视频和语音信息,输出不定长文本 Token + 固定长度语音 token,避免文本 token 生成过快造成浪费。
3. 高频自主交互语义判断机制:实现交互自由性
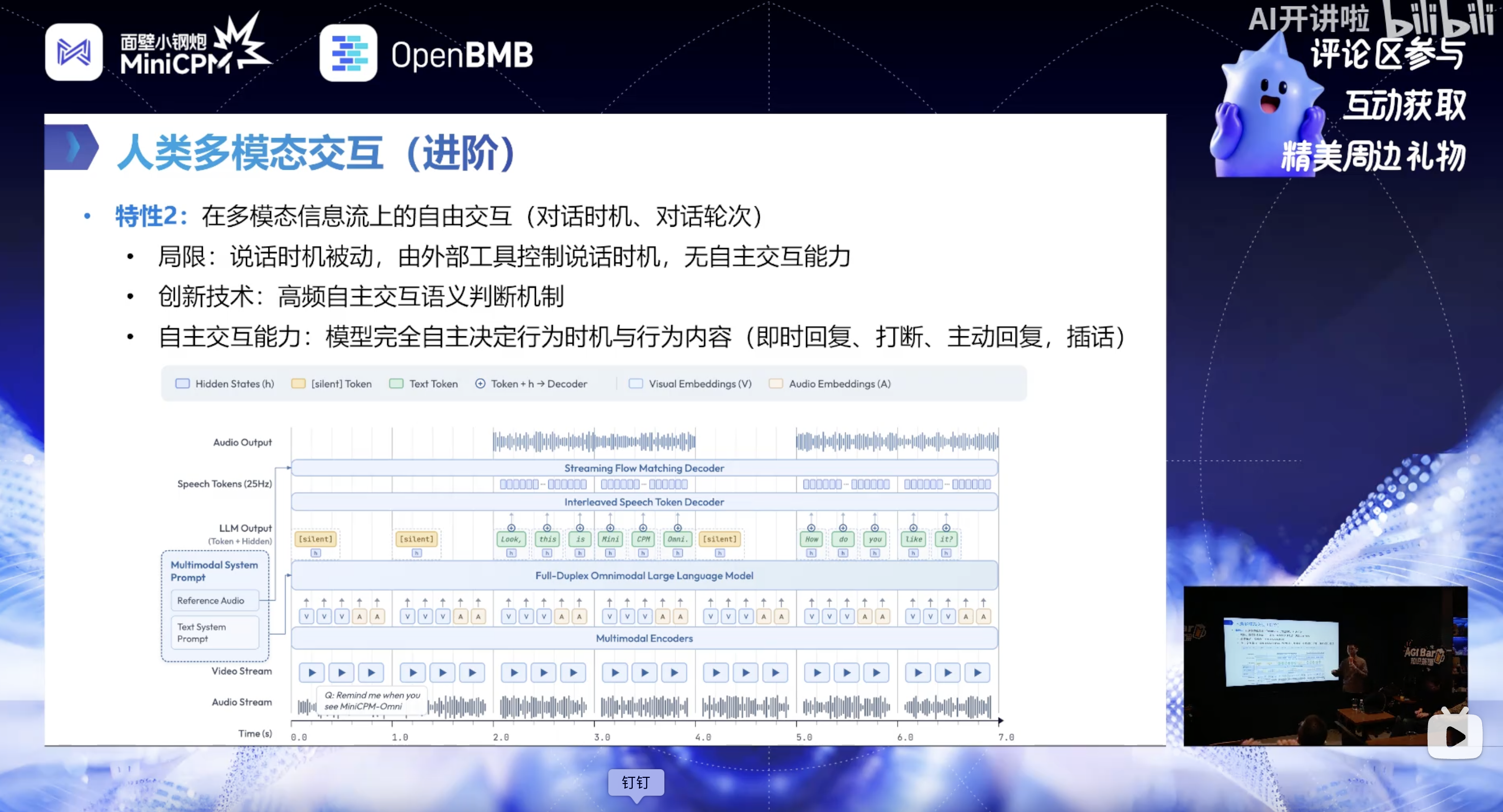
解决的核心问题
摒弃传统由外部工具(VAD、唤醒词)控制说话时机的模式,让模型自主决定行为时机与内容,弱化一问一答的轮次概念。
核心实现
- 高频判断:模型以每秒 1 次的频率,在动态时间流中判断自身是否该说话(静默 / 回复 / 插话),频率可调整以模拟人类不同的反应速度;
- 基于全模态的决策:外部多模态信息时刻持续输入,模型可基于实时信息流做出决策,而非仅依赖用户的单次提问,这是与纯文本模型的核心区别;
- 自主交互能力落地:
- 即时回复:基于语义判断用户说话结束,无需硬等 VAD 的时间阈值,可预判用户即将说完;
- 打断:持续监控外部信息流,检测到用户说话时自动进入静默倾听状态;
- 主动回复:当多模态时机成熟时主动反馈(如 “电梯到 24 层了”“绿灯亮了”);
- 插话:可基于语义判断主动插话(产品层面做了限制,避免频繁打断)。
全模态全双工核心设计逻辑解读
(1)时间流是全双工自主交互的核心:模型从「被动响应」变为「主动伴随」
- 时间流的核心是「持续的伴随态」:模型始终处于多模态信息流接收状态,「静默/说话/插话」是基于实时时间流的统一决策结果,而非不同功能策略;
- 决策依据从「用户指令」升级为「全场景流信息」:模型判断基于整体实时多模态时间流,即使用户无指令,也可根据视觉/音频信息自主反馈,突破传统模型的决策局限。
简单来说:时间流让模型从「用户的工具」变成了「场景的伴随者」。
(2)全模态全双工的价值远高于纯语音全双工:多信道的天然互不阻塞属性
- 纯语音全双工需求偏弱:语音为单信道,人类交流多为半双工场景,技术优化对体验提升有限;
- 全模态全双工是多信道天然需求:视觉、音频、语音等为独立信息传输信道,天然互不阻塞,贴合人类“边看边听边说”的交互习惯;
- 核心价值:还原真实世界的信息交互方式,是解锁车载、无障碍辅助、智能机器人等端侧场景的关键,为纯语音全双工无法实现。
简言之:纯语音全双工是「单信道的技术优化」,而全模态全双工是「多信道还原真实世界的底层重构」。
(3)全双工的技术落地具备可行性:半双工能力可无损耗继承
- 全双工为「兼容式升级」:通过合理网络结构设计和针对性数据驱动训练,升级后模型能力无明显掉点;
- 原有能力完整继承:全双工模式下可完美实现半双工的所有功能,是能力的叠加而非替代,保证了模型实际应用的实用性。
(4)整体总结
- 技术逻辑:时间流的伴随态让全双工自主交互成为可能,决策从「围绕用户」升级为「围绕场景」;
- 商业价值:全模态全双工是多信道天然属性决定的、更具实际应用价值的技术方向;
- 工程实现:全双工为兼容式升级,原有能力无损耗继承,具备落地可行性。
4. 自然低延迟语音交互技术:提升语音拟人度与流畅性
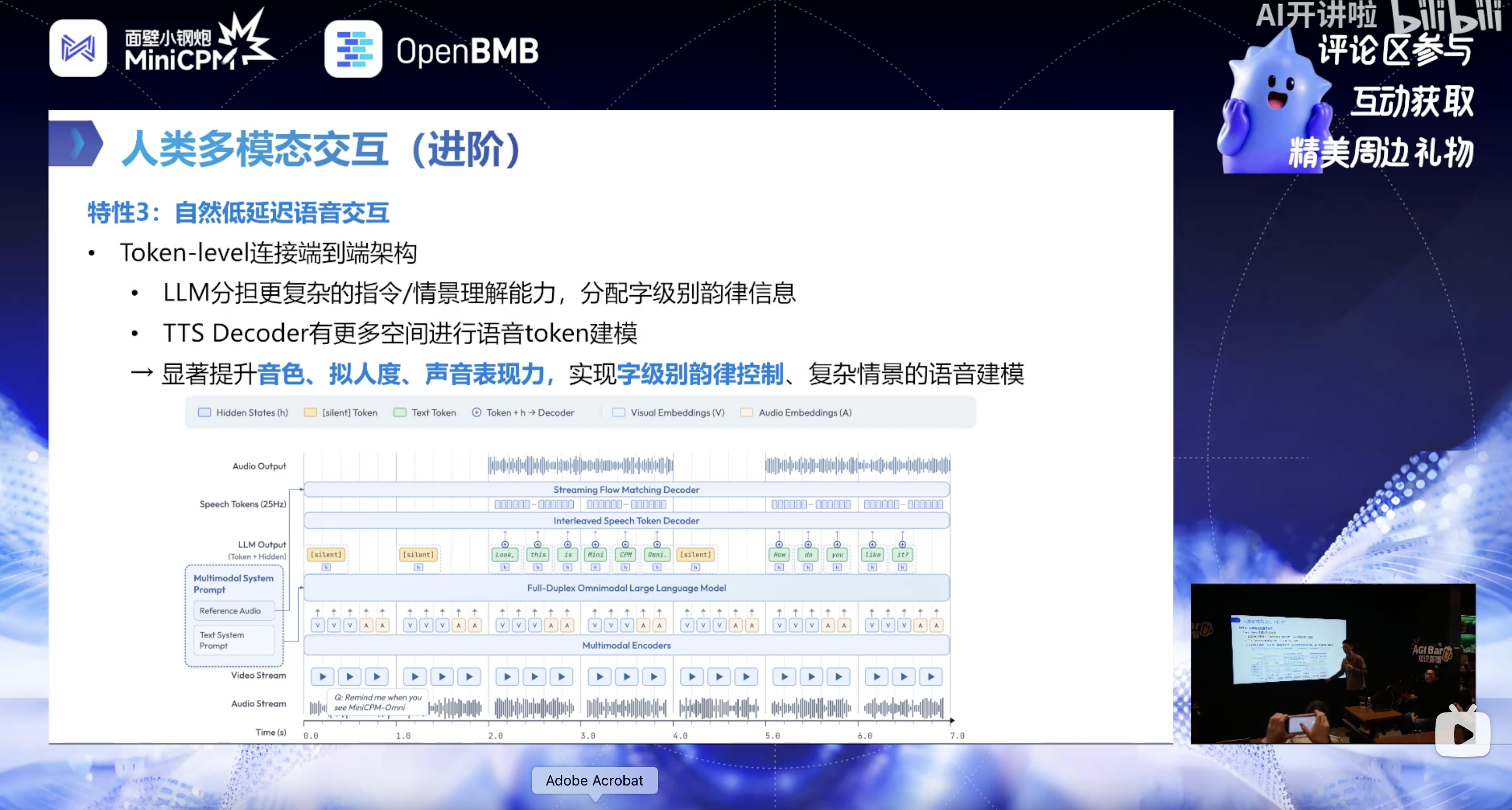
围绕token-level 端到端连接和全双工语音生成两大核心,实现自然、低延迟、可定制的语音交互,核心技术点如下:
(1)LLM 与 TTS 的协同优化
- LLM 分担复杂指令 / 情景理解,并为 TTS 分配字级别韵律信息;
- 轻量级 TTS 解码器无需处理复杂语义,有更多空间进行语音 token 建模,显著提升音色、拟人度和声音表现力,实现字级别韵律控制和复杂情景语音建模。
| 模块 | 核心功能 | 技术价值 |
|---|---|---|
| 8B LLM | 情景理解、字级别韵律信息分配 | 为语音生成提供细粒度语义控制 |
| 轻量级 TTS | 语音 token 建模、韵律还原 | 专注语音生成,提升拟人度与音色表现力 |
(2)全双工语音生成实现
- 实时流式改造:将传统离线 TTS 的 attention 改为因果型,实现实时流式编解码,保留上下文一致性;
- 每秒同步生成:每秒接收文本 + 隐层表示,生成 1 秒语音,实现输入输出同步;
- Pre-look 机制保证连贯性:生成当前秒语音时,提前读取后续一小段文本 / 语音 token,基于未来信息调整当前语音的语气、韵律,避免断句生硬,生成后丢弃预读的冗余信息。
(3)附带优势:长语音生成稳定性
传统离线 TTS 生成长语音时,错字率随时间急剧上升;全双工流式模式下,模型交替处理文本和语音,生成1 分钟以上长语音的错字率降至业界最好水平的一半以下。
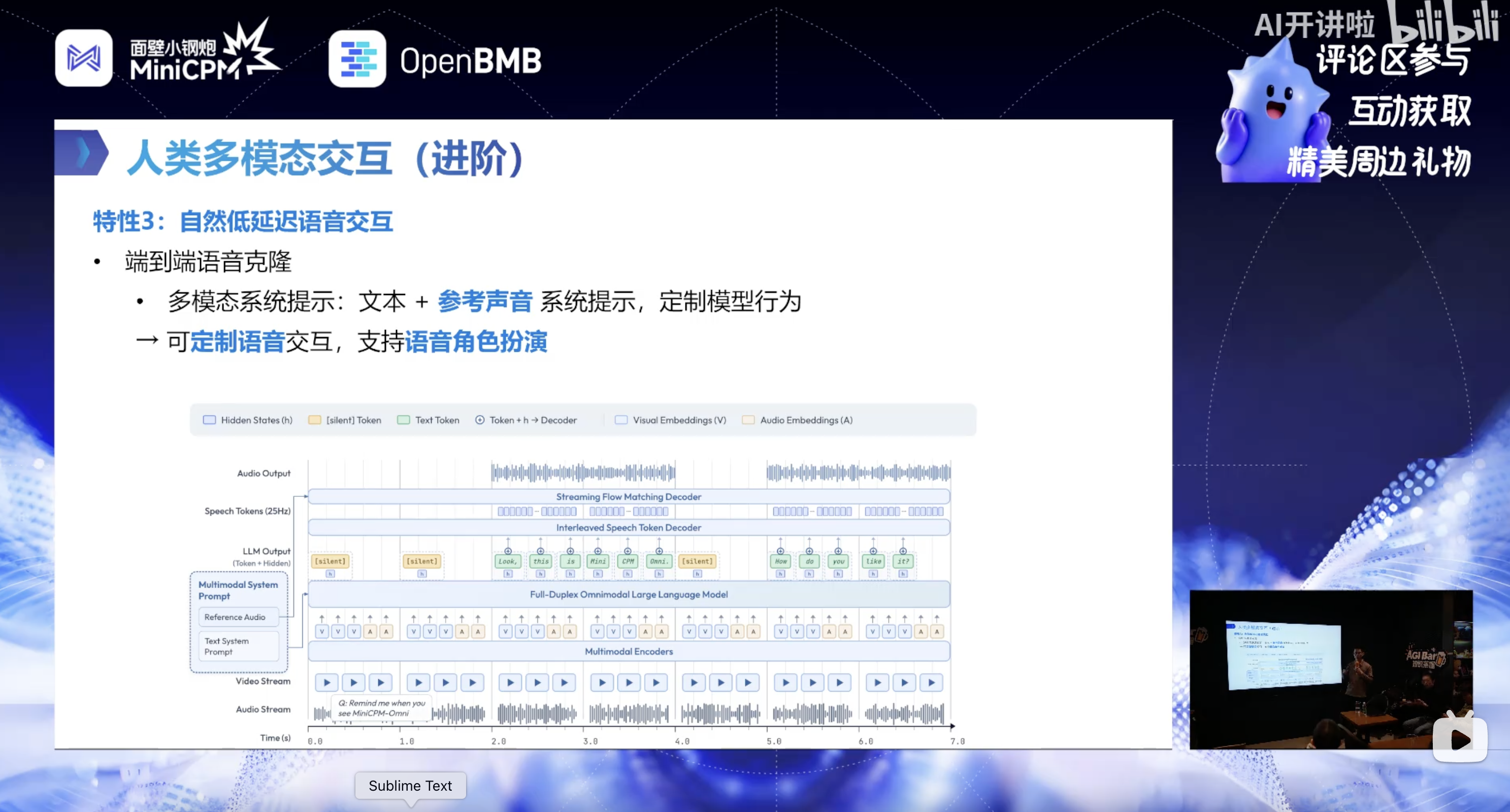
(4)端到端语音克隆(多模态 system prompt)
- 创新点:拓展文本 + 参考声音的多模态系统提示,替代传统固定少数音色的模式;
- 实现方式:推理阶段通过结构化字段(如 JSON)传入文本 prompt + 参考声音片段,模型在训练中学会模仿参考声音的音色(基于 loss 最小化原则);
- 能力:支持语音角色扮演,可定制语音交互的音色和表达风格(如模仿哪吒、马斯克的语音和语气),且在语音克隆的同时保持低错字率,达到业界最优水平。
5. 核心结构总结
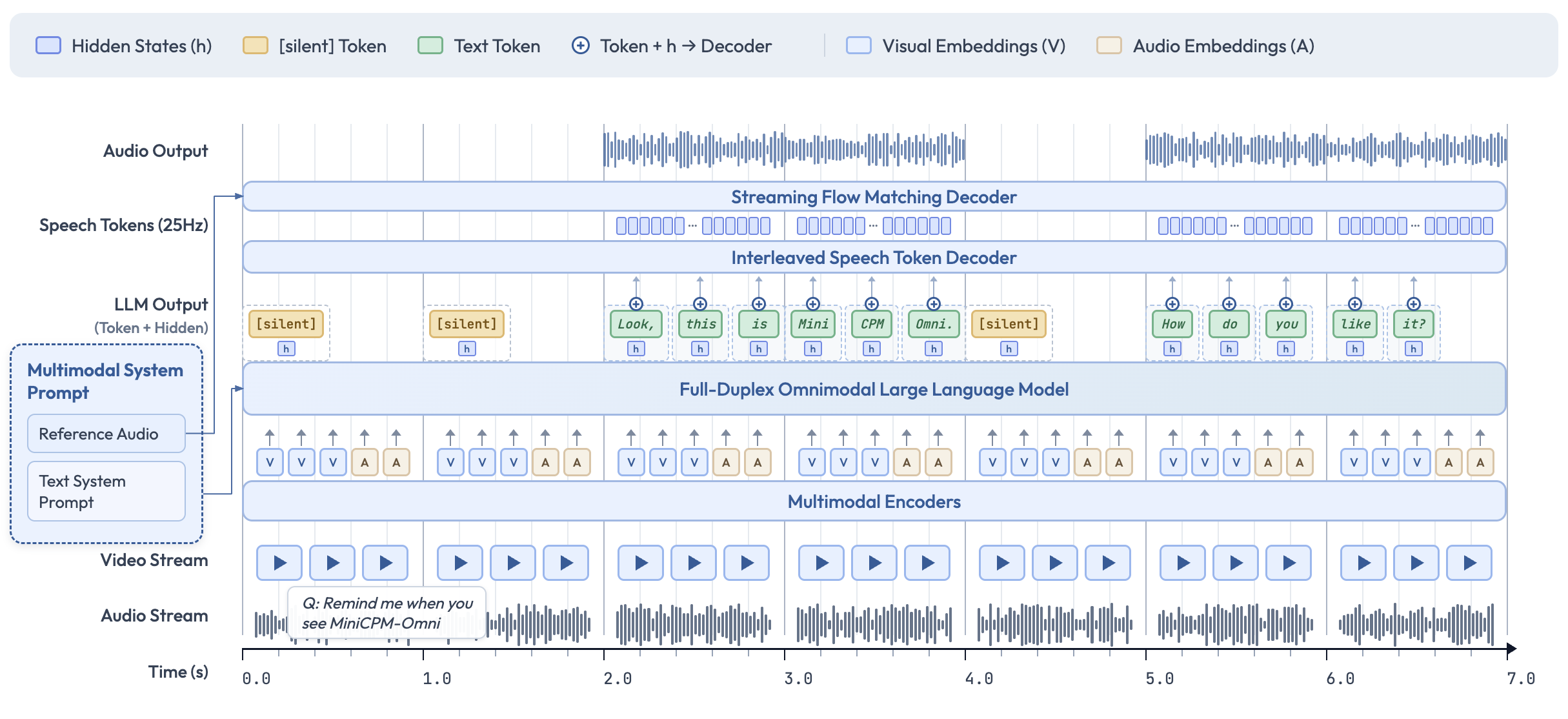
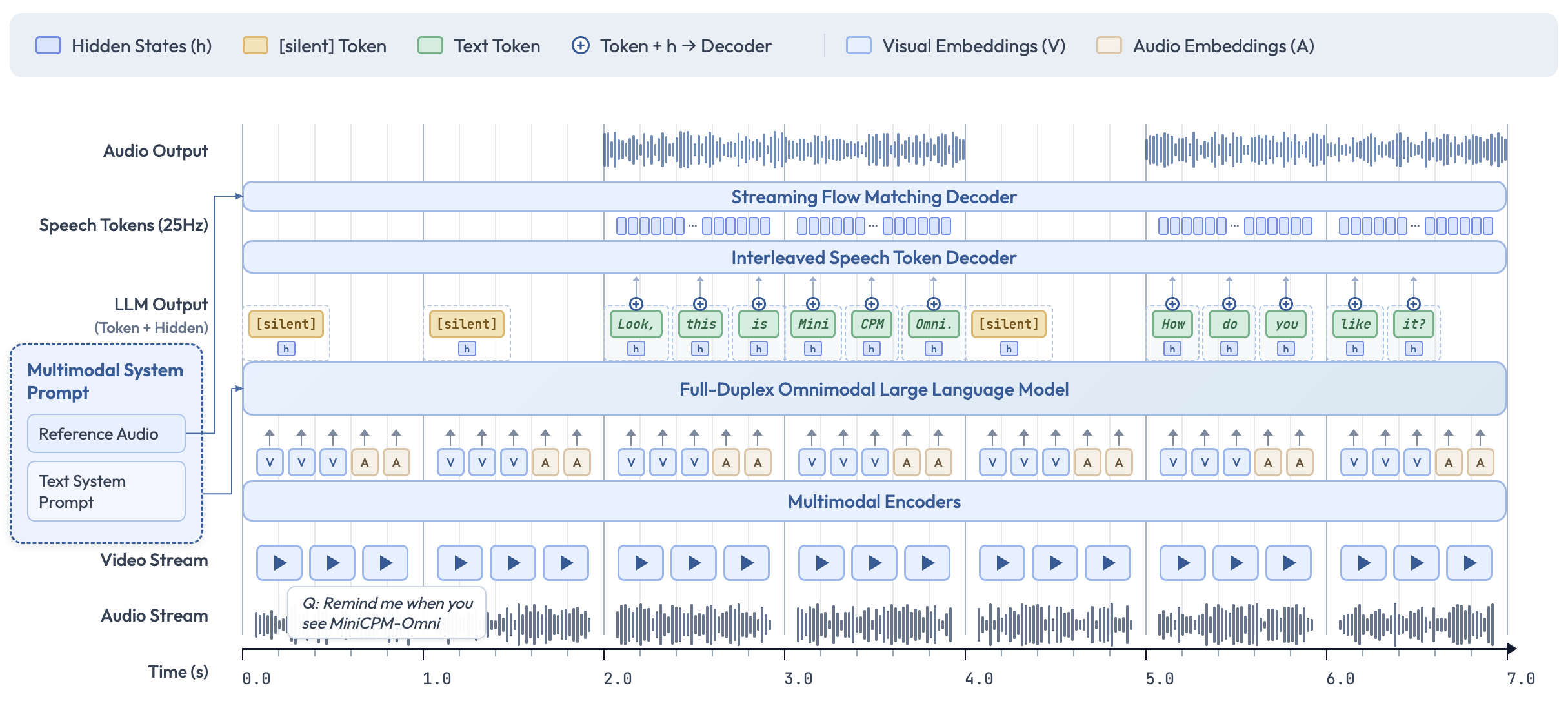
5.1 整体架构:全双工多模态实时交互系统
8B 骨干 LLM + 轻量级多模态编解码器的模块化架构,核心目标是实现边看、边听、边说的全双工交互,而非传统模型 “先理解再一次性生成” 的静态模式。
从下到上的数据流(时间轴从左到右)
- 底层输入层
- Video Stream:按时间片输入视频帧,由 Multimodal Encoders 编码为视觉嵌入(V);
- Audio Stream:实时输入音频波形,由 Multimodal Encoders 编码为音频嵌入(A);
- Multimodal System Prompt:包含文本系统提示(如任务指令)和参考音频(用于语音克隆),作为系统级上下文注入。
- 中间处理层
- Multimodal Encoders:轻量级编码器,将视频帧和音频波形编码为固定维度的视觉 / 音频嵌入(V/A),并按时间片对齐;
- Full-Duplex Omnimodal LLM:8B 骨干大模型,接收所有模态嵌入和系统提示,进行高级语义理解、决策和生成;
- Interleaved Speech Token Decoder:接收 LLM 输出的文本 token + 隐层表征(h),逐 token 生成语音 token;
- Streaming Flow Matching Decoder:轻量级流式语音解码器,将语音 token 转换为可播放的音频波形。
- 顶层输出层
- LLM Output:输出文本 token(绿色)和 [silent] token(黄色),以及对应的隐层表征(h);
- Speech Tokens:25Hz 的语音 token 序列,由语音解码器生成;
- Audio Output:最终的实时语音波形输出。
5.2 核心机制:时间绑定与全双工交互
- 时间概念建模(Time-Bound Processing)
- 模型将整个交互过程严格绑定到时间轴上,以1 秒为一个时间片进行处理;
- 每个时间片内:接收该时段内的所有视频帧和音频片段;由 LLM 生成不定长度的文本 token(用于语义表达)和固定数量的语音 token(用于语音生成);仅生成当前秒的实时信息,确保输入输出同步。
- 时分复用(Time-Division Multiplexing)
- 并行的视频、音频、文本信息流被切分为毫秒级的时间切片;
- 宏观上各模态处理并行不阻塞,微观上按时间片顺序处理,保证了系统的实时性和稳定性。
- 高频决策机制(High-Frequency Decision Making)
- 模型以每秒 1 次的频率,在动态时间流中判断自身行为:
- 静默 ([silent] Token):当无需说话时,输出 [silent] token,保持倾听状态;
- 回复 (Text Token):当需要说话时,输出文本 token,驱动语音生成;
- 插话 / 打断:持续监控输入流,可基于语义判断用户说话结束,或在检测到用户说话时自动静默。
- 模型以每秒 1 次的频率,在动态时间流中判断自身行为:
5.3 关键技术点:Token-Level 端到端连接与全双工语音生成
- Token-Level 端到端连接
- 输入端:视觉嵌入(V)和音频嵌入(A)逐帧逐秒输入 LLM,让模型充分吸收全模态信息;
- 输出端:LLM 输出的每个文本 token 都携带对应的隐层表征(h),并逐 token 传入语音解码器;
- 价值:实现了细粒度的语义控制,让语音生成不仅基于文本内容,还能充分利用 LLM 理解到的情景、情感和韵律信息。
- LLM 与 TTS 的协同优化
- LLM 负责复杂的指令理解和情景建模,并为每个字分配韵律信息;
- TTS 解码器则专注于语音 token 的建模和还原,无需处理复杂语义,从而有更多空间提升音质和表现力。
- 全双工语音生成
- 实时流式改造:将传统离线 TTS 的 attention 改为因果型,实现实时流式编解码,保证上下文一致性;
- 每秒同步生成:每秒接收文本 + 隐层表征,生成 1 秒语音,实现输入输出同步;
- Pre-look 机制:生成当前秒语音时,预读后续一小段文本 / 语音 token,基于未来信息调整当前语音的语气和韵律,避免断句生硬。
- 端到端语音克隆(多模态 System Prompt)
- 创新地将文本系统提示和参考音频片段结合,作为多模态系统提示注入模型;
- 模型在训练中学会模仿参考声音的音色和表达风格,支持语音角色扮演(如模仿特定人物的声音);
- 在语音克隆的同时,保持了极低的错字率,达到业界最优水平。
5.4 图中关键元素的含义
- Hidden States (h):LLM 输出的隐层表征,携带了丰富的语义和情景信息,用于细粒度控制语音生成;
- [silent] Token:LLM 输出的静默标记,表示当前无需说话,保持倾听;
- Text Token:LLM 输出的文本标记,驱动语音生成;
- Visual Embeddings (V):视频帧的编码表示;
- Audio Embeddings (A):音频片段的编码表示;
- Token + h → Decoder:表示文本 token 和对应的隐层表征一起传入语音解码器。
四、模型核心能力与评测
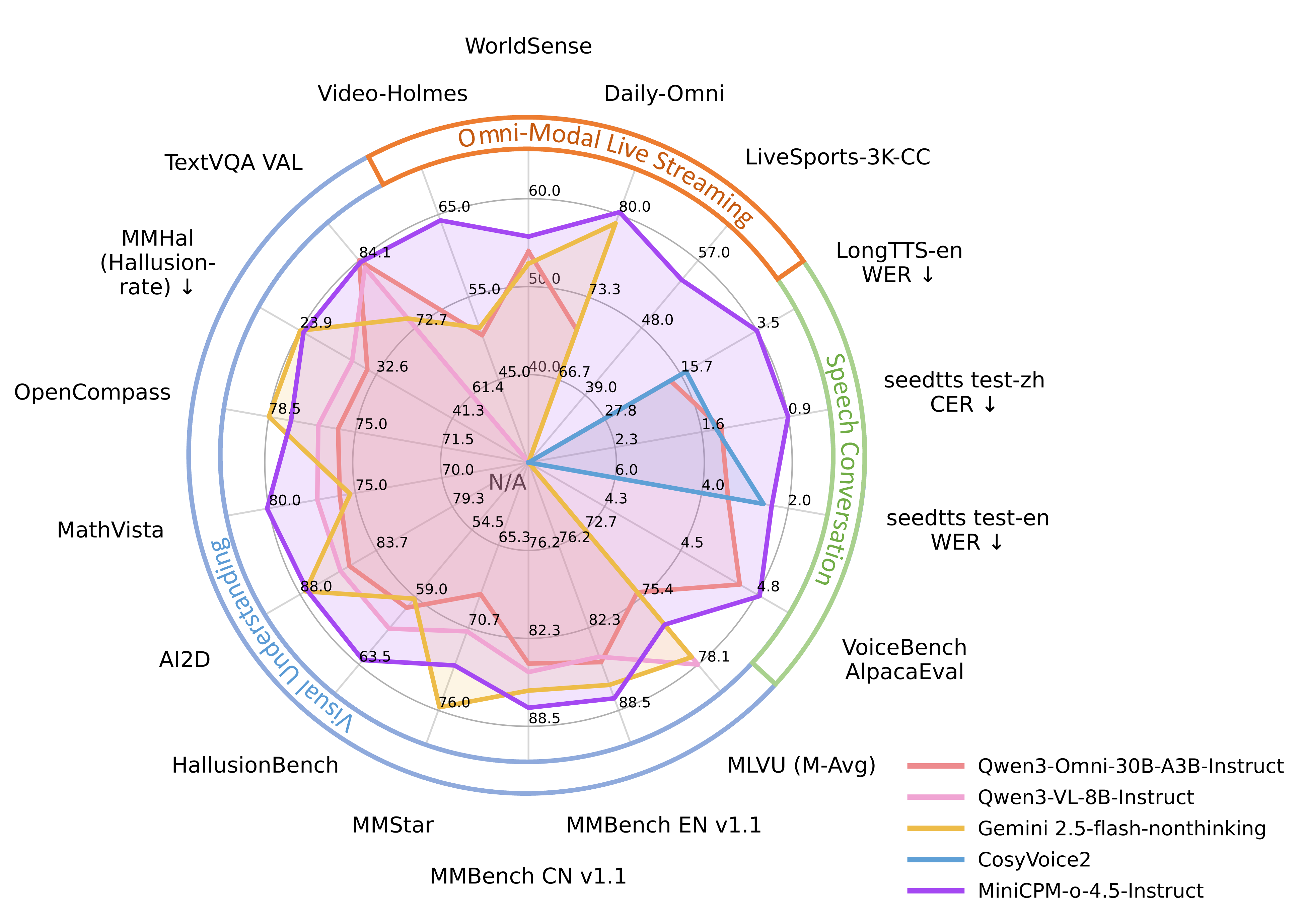
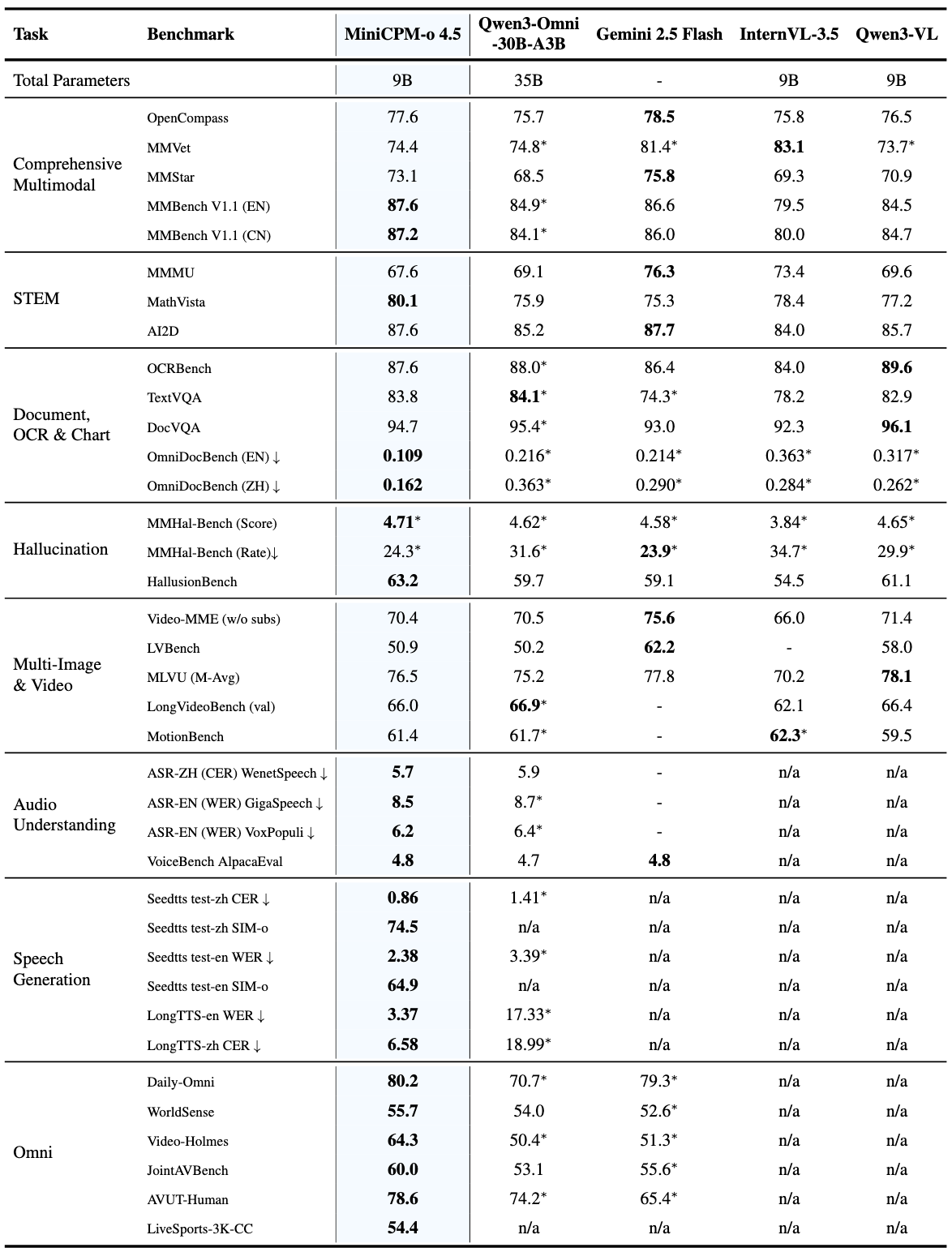
1. 基础能力:全模态能力均衡且领先
在 8B/9B 参数量下,各模态能力均实现同尺寸领先,核心包括:
- 视觉语言能力:端到端英文复杂文档解析达到端侧最好效果,超越部分专用工具模型;
- 多图 / 视频理解:继承并优化了 2.6 版本的原生记忆和推理能力;
- 音频理解:支持通用音频编码,可识别非语音音频(敲门声、微波炉叮声、水流声),区别于传统仅能处理语音的模型;
- 语音生成:低错字率、高拟人度、支持长语音和语音克隆;
- 幻觉控制:在全双工模式下仍能有效控制幻觉,保证回答准确性。
| 能力维度 | 评测指标 | 行业定位 |
|---|---|---|
| 视觉语言 | 英文复杂文档解析准确率 | 端侧最优,超越部分专用工具模型 |
| 多图 / 视频理解 | 原生记忆推理准确率 | 同参数量级端侧领先 |
| 通用音频识别 | 非语音音频(敲门声 / 水流声)识别率 | 覆盖真实场景,突破语音模态限制 |
| 语音生成 | 字级别韵律还原度、错字率 | 8B 级模型端侧最优 |
| 语音克隆 | 音色相似度、内容准确率 | 开源社区首个端侧端到端实现 |
2. 推理效率:端侧友好,适配性强
- 硬件支持:在 4090 显卡上可实现 BF16 精度推理,INT4 量化后显存占用更低、推理速度更快;
- 端侧部署:基于 C++ 开发的 llama.cpp-omni 推理框架,可在 Mac 上运行,全双工全模态能力运行时显存占用约 10G。
3. 评测特点
- 传统能力(图文、语音):有完善的定量评测,结果在 GitHub 开源;
- 全双工能力:目前行业无统一评测标准,主要通过体感测试和内部自动评测验证,开启全双工后对单双工能力无明显掉点。
五、部署与开源支持
1. 常规框架适配
全面适配端侧 / 大模型常用推理框架:Llama.cpp、ollama、vLLM、SGLang、FlagOS 等,部分已合入官方仓库,开发者可直接使用。
2. 全模态能力专属部署支持
- 高效端侧推理框架:自研 llama.cpp-omni,基于 Llama.cpp 改造,全流程 C++ 实现,支持端侧全双工全模态推理;
- 演示系统:
- 网页端:基于 WebRTC 搭建的全双工演示交互系统(持续优化卡顿问题);
- 本地端:轻量级 Mac 端演示交互系统(未来几天开源),实现端侧推理与交互的闭环。
六、应用场景与端侧部署的必要性
1. 核心应用场景
模型的全双工、全模态、自主交互能力适用于传统模型无法覆盖的类人陪伴 / 实时辅助场景,核心包括:
- 智能伴随助手:手机、智能眼镜、智能家居等端侧设备,实现日常陪伴、生活记录、实时反馈(如 “记录拿取的商品价格”);
- 无障碍辅助:为盲人提供实时环境感知(如 “绿灯亮了”“前方有台阶”),解决传统图文模型体验差的问题;
- 车载智能交互:实时监控车位、路况,语音主动提醒(如 “左侧有停车位”),适配开车时的无手操作场景;
- 沉浸式场景交互:元宇宙、智能座舱、机器人等,实现多模态实时互动,模拟人类交流方式。
2. 端侧部署的核心必要性
全双工全模态模型与端侧深度绑定,核心原因有三:
- 数据安全与隐私保护:模型持续陪伴用户,记录海量实时多模态信息,端侧部署可实现数据不上云,避免隐私泄露,这是云端部署无法解决的核心问题;
- 低延迟与稳定性:全双工交互对延迟要求极高,端侧部署可实现本地低延迟推理,适配无网 / 弱网场景(如野外、隧道、会议现场);
- 算力负载均衡:若海量用户的多模态流均上传云端,会造成云端算力中心巨大负担,端侧部署可利用用户本地算力实现自闭环,降低服务提供方的算力成本。
七、研发挑战与解决思路
1. 多模态能力融合的冲突问题
- 挑战:将视觉、音频、语音、文本等能力融合在一个模型中,各模态数据易 “互相打架”,有限参数下训练难度高;
- 解决:深入理解不同模态数据的学习特性,精准选择数据加入的时机和位置,精细化训练,解决 99% 正确后 1% 的细节问题。
2. 全双工技术的 “无人区” 探索
- 挑战:行业无成熟参考,模型结构、数据构造、训练方法、评测体系、推理框架、交互 demo 均需从零搭建;
- 解决:体系化探索,模型与 demo迭代打磨,模型调整后同步优化推理和交互系统,验证了细粒度时间切片下模型的学习能力。
3. 全双工下的连贯性与实时性平衡
- 挑战:每秒切分处理信息,易导致文本 / 语音生成不连贯,且模型需具备几十毫秒级的时间感知能力;
- 解决:通过 Pre-look 机制、时分复用、逐 token 紧密连接,在保证实时性的同时实现上下文连贯性。
4. 端侧部署的资源限制
- 挑战:端侧显存、算力有限,需在保证能力的前提下优化推理效率;
- 解决:采用轻量级编解码器、INT4 量化、自研高效 C++ 推理框架,实现端侧低显存占用运行。
研发挑战与解决思路深度解析
MiniCPM-o 4.5 四大研发挑战是端侧全双工全模态模型的底层共性难题,本质为多模态融合的参数效率矛盾、全新技术范式的工程化空白、实时性与连贯性的技术权衡、端侧硬件的资源约束适配,解决思路贴合大模型研发规律且针对三重特性精准创新,核心逻辑为以端侧落地为核心,技术创新围绕轻量、实时、类人展开,同时为行业提供了可复制的研发经验:
- 多模态融合:有限参数下的模态差异化融合是核心,而非参数量堆料;
- 新范式研发:算法与工程协同迭代是关键,需搭建全链路工程化体系;
- 实时交互:实时性与连贯性的技术协同是核心,需针对人类体验做定制化设计;
- 端侧优化:分层优化 + 定制化设计是最优解,需兼顾通用适配与场景需求。
八、模型局限性与未来发展方向
1. 现阶段局限性
- 上下文长度有限:建议在1 分钟内使用,3 分钟内表现尚可,超出后性能会下降,受端侧内存限制;
- 全模态微调难度大:单一模态 / 能力微调可通过开放脚本实现,但全模态(尤其是全双工流式)微调的数据构造尚无成熟方法,远超当前主流的 ChatGPT 造数模式;
- 全双工评测体系缺失:行业无统一的全双工能力评测标准,主要依赖体感和内部测试。
2. 未来发展方向
- 提升上下文长度:通过训练原生更长的上下文、探索内存优化方法(如硬盘缓存),实现上下文长度的几倍甚至 10 倍提升;
- 完善全模态微调生态:推动社区建设,开发全双工数据构造、微调工具,让全模态微调像图文 / 文本微调一样便捷;
- 优化端侧部署体验:进一步降低显存占用、提升推理速度,适配更多端侧设备(如手机、嵌入式设备);
- 丰富拟人交互能力:提升模型的情商、语音表达的个性化,实现更自然的类人交流;
- 工具调用与全模态能力融合:探索模型在全双工状态下的工具调用能力,拓展实际应用边界。
九、关键见解与行业思考
- 多模态大模型的核心发展方向:从 “更小更强” 的密度提升,转向更类人的交互逻辑,真正模拟人类的多模态感知和交互方式,这是实现 AGI 的重要一步;
- 全模态与全双工的本质价值:不同模态是独立的信息传输通道,物理上本就不应互相阻塞,全双工全模态建模才是符合现实世界的方式,能解锁大量传统模型无法实现的场景;
- 端侧是全双工全模态模型的最终归宿:全双工全模态的交互特性对隐私、延迟的要求,决定了模型无法依赖云端部署,端侧智能是未来的核心方向;
- 工程与算法的协同创新:全双工全模态模型的落地,不仅需要算法创新,还需要推理框架、交互系统、数据构造等全链路工程能力的支撑,单一算法突破无法实现实际应用。
- 本文标题:语音对话 | MiniCPM-o 4.5 全双工全模态大模型-技术分享(Part I)
- 创建时间:2026-02-08
- 本文链接:2026/2026-02-08-minicpm-o-4.5-A/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!