论文信息:Data Science and Technology Towards AGI Part I: Tiered Data Management,清华大学 & 面壁智能
大模型时代,自从数据和模型参数的 Scaling Law 验证了有效性,关于数据始终有一个问题无法回避:训练数据,到底应该怎么管理?
从 GPT-4 到 DeepSeek 到各类 LLM 公司推出的大模型,大家应该都已经知道数据规模和数据质量的重要性,但各家具体数据的是如何运作/如何管理,以及是否有一套系统化可遵循的数据管理方案,是不得而知的。很多公司可能知道数据的重要性,但是落到实处,往往还是一套老办法——爬取更多的数据、根据一些直觉进行数据的清洗、然后采用一些策略扔进模型训练里。事实上,这条路已经基本走到了瓶颈:互联网上的高质量文本在快速消耗,大模型产出的文本占比越来越高,训练的模型参数越来越大,但对数据质量的要求却没有对应的系统性方案。
清华大学和面壁智能在 UltraData 这个项目里尝试回答这个核心问题。他们的主张其实很简单但更加系统化:数据不应该只是训练的原材料,而应该像代码一样被分层管理、精细运营。这个项目提出了一套 L0-L4 的数据分层体系,并在 MiniCPM 这一模型基础上,进行了完整的实验验证。
一、AI 数据的四个时代
在正式介绍方案之前,论文先梳理了 AI 发展中数据角色的演变。简单说,有四个阶段:
- 符号学习时代:数据 = 专家手工整理的规则与知识库,静态、封闭;
- 监督学习时代:数据 = 人工标注样本,模型性能直接取决于标注规模和质量;
- 自监督学习时代:数据 = 海量无标注语料,模型从中自己学习世界知识;
- 反馈学习时代:数据 = 人类或环境的奖励信号,驱动模型在复杂任务中持续优化,这也是目前 LLM 对齐训练的核心范式。
每个阶段对数据的需求都不一样,但现在的问题是:大多数团队的数据管理思路还停留在”自监督学习”的逻辑——把尽可能多的数据喂给模型就行了。
这套逻辑正在失效,主要体现在三点:
- 互联网高质量公开数据越来越稀缺,规模扩张的边际效益在下降;
- 预训练、中训练、对齐微调等不同阶段,对数据的需求差异很大,一刀切的处理方式很浪费;
- 高价值数据(比如教科书级内容、高质量推理链)没有被系统识别和优先利用。

二、现有方案哪里不够用?
目前业界的数据管理方案大体上分两类:
第一类:按训练阶段拆分,预训练用一套、中训练用一套、后训练再用一套。各阶段目标不同,但没有统一的质量标准,数据在各阶段之间流动时,缺乏系统的价值评估和优化机制。
第二类:按处理流程拆分,从解析、过滤、选择到编辑、融合,每个环节各自为政。但流程碎片化,处理过一遍的数据很难追溯来源,也没有闭环反馈,不知道哪些数据真正有效、哪些在浪费算力。
两类方案的共同问题是:缺乏一套统一的、贯穿全局的数据质量分层标准。结果就是高价值数据被埋在噪声里,训练阶段和数据质量之间的匹配全靠经验和运气。
三、L0-L4:用”等级”给数据定价
论文提出的解决方案,核心思路很直白:给数据打等级,越高级的数据越干净、越贵、也越有用。
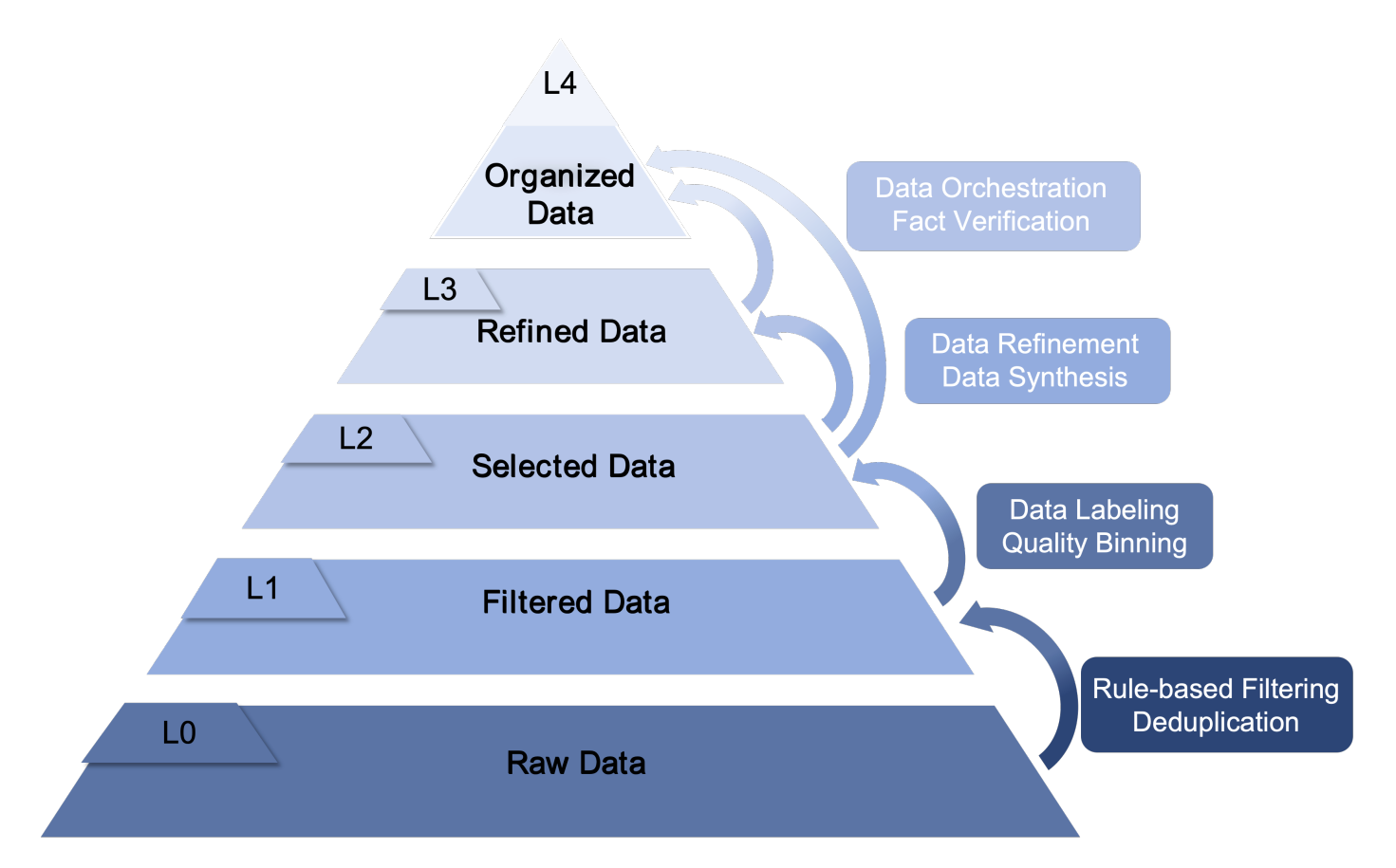
具体分五级(L0 到 L4),从原始状态一步步精炼:
| 层级 | 名称 | 是什么样的数据 | 怎么得到 | 用在哪里 |
|---|---|---|---|---|
| L0 | 原始数据 | PB 级原始爬取,含广告、乱码、重复内容,什么都有 | 网页爬取、批量下载,不做深度处理 | 只作数据仓库,不直接训练 |
| L1 | 过滤后数据 | 格式统一、可读,去掉了明显噪声 | URL 过滤、语言识别、规则去重(MinHash) | 大规模预训练,打通用知识基础 |
| L2 | 选择后数据 | 主题集中、信息密度高、领域相关性强 | 模型驱动的领域分类器、质量评分 | 预训练后期和中训练,提升领域能力 |
| L3 | 精修后数据 | 逻辑清晰、教科书级质量,有明确的教学意图 | LLM 辅助编辑与生成、人工精修 | 中训练、SFT、RL,突破推理和逻辑能力 |
| L4 | 组织化数据 | 可验证的结构化知识,无事实错误 | 知识图谱构建、严格事实核查 | RAG 检索增强,解决幻觉问题 |
这套分层的设计逻辑有几个值得关注的点:
1. 数据等级和训练阶段要匹配:早期预训练用 L1 数据打宽度,中后期训练用 L2/L3 打深度,下游应用用 L4 保可靠性。高质量数据用在最需要的地方,而不是全程混在一起。
2. 用模型来管数据:从 L2 开始,数据质量评估和处理都引入了模型参与——用 LLM 做质量打分、内容改写、合成生成等。这形成了”模型优化数据,数据提升模型”的飞轮。
3. 成本和收益要算清楚:L1 用低成本自动化处理(几乎不花什么钱),L3/L4 用精细化方法(LLM 标注、人工精修,成本高),但只在最关键的训练节点上用,整体性价比合理。
4. 数据可追溯:从 L0 到 L4 的每一步都有明确的处理记录,出了问题知道根因在哪。
四、实验验证:分层到底有没有用?
论文用 MiniCPM-1.2B 做了三类实验,评估框架是 OpenCompass,覆盖英文网页、中文网页、数学、代码四个领域。
实验一:数据质量越高,模型越强
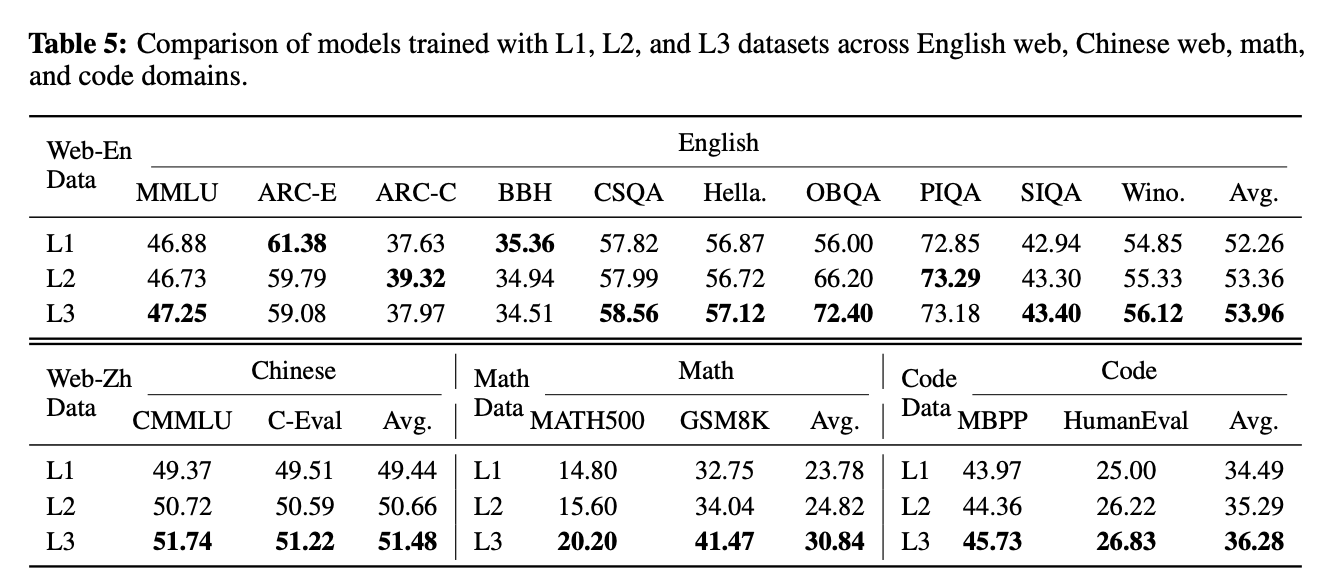
最基础的验证——同样的数据量(10B token),分别用 L1、L2、L3 数据训练,看效果有没有梯度差异。
结论很明确:L3 > L2 > L1,每个领域都成立。
- 英文网页:L1(52.26) → L2(53.36) → L3(53.96)
- 中文网页:L1(49.44) → L2(50.66) → L3(51.48)
- 代码:L1(34.49) → L2(35.29) → L3(36.28)
- 数学:提升最明显,L1 到 L3 整整涨了 7.06pp
实验二:高质量数学数据,还能带飞其他能力
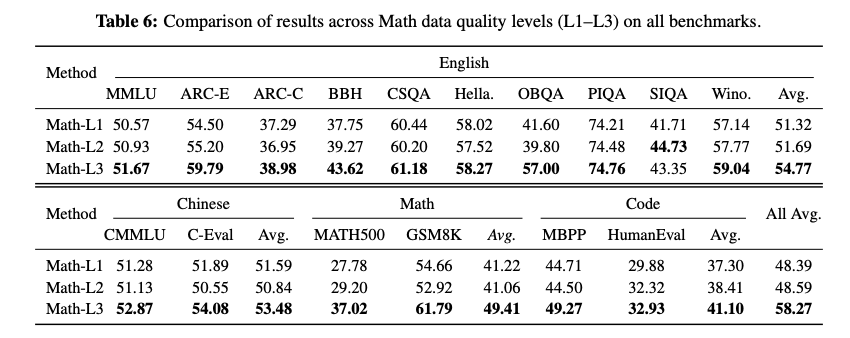
用 100B token 的数学数据(L1 vs L3)做大规模缩减阶段(cooldown)训练,不只看数学分,还看其他领域有没有变化。
Math-L3 不只是数学变强了(MATH500/GSM8K 显著提升),还带动了:
- 英文通用理解 +3.45pp
- 中文通用理解 +1.89pp
- 代码生成 +3.8pp
这说明高质量领域数据有溢出效应——数学推理练好了,模型的整体逻辑能力也跟着涨。
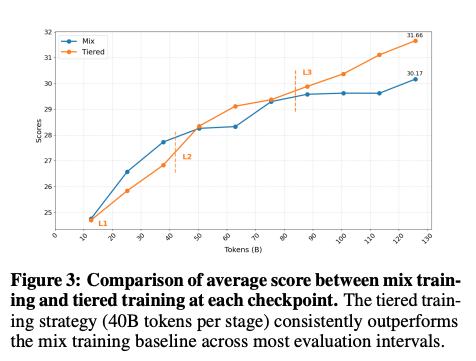
实验三:先低后高的分层训练,比混合训练更有效
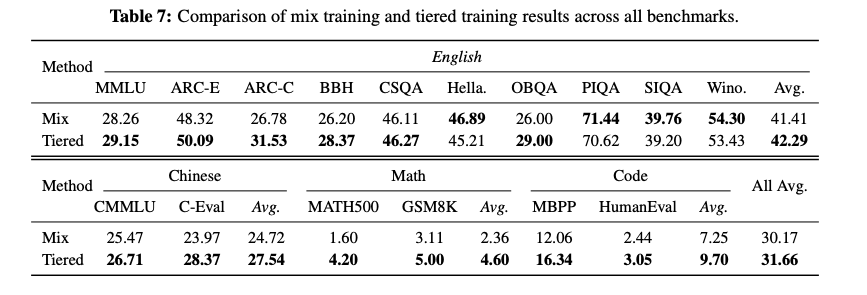
总数据量一样(120B token),两种策略对比:
- 混合训练:L1/L2/L3 等比混合,一起训;
- 分层训练:先用 L1 训 40B,再 L2 训 40B,最后 L3 训 40B。
结果:分层训练最终得分 31.66pp,混合训练 30.17pp,差了 1.5pp——而且数据量完全一样。
更有意思的是训练曲线:分层训练后期涨幅更大(+3.31pp),混合训练后期涨幅收窄(+1.91pp)。原因不难理解:低质量数据混在一起,会干扰模型在后期学习高阶能力。先用 L1 打底,再逐步提升数据质量,让模型按节奏成长,效率更高。
当然也有一个小代价:HellaSwag、PIQA 这类依赖大规模常识覆盖的任务,分层训练略有下降——因为这类任务更需要 L1 数据的宽度,而不是 L3 的深度。
五、开放资源
论文配套开放了 UltraData 系列数据集和工具,可以直接用:
数据集:
- UltraData-Math(L1/170B、L2/33B、L3/88B)
- Ultra-Fineweb-en(L2/1800B、L3/200B)
- Ultra-Fineweb-zh(L2/120B、L3/200B)
工具:
- UltraData-Math-Parser:数学内容 HTML 解析器
- UltraData-Math-Generator:数学题融合生成器
- 英/中文网页数据分类器
L0-L4 各层级的处理方法也都有对应的开源工具和参考数据集,入门门槛不高。
六、几点看法
这篇论文最大的价值不在于某个具体技术,而在于把”数据分层”这件事系统化了。L0-L4 框架本身并不复杂,但把它变成一套有明确定义、可操作、可验证的工程体系,是很扎实的工作。
从论文中和个人实践中,有下面的观察:
- “数据-模型协同进化”是真命题:用 LLM 来管理和提升数据质量,再用高质量数据训练更好的 LLM,这个飞轮在实验里跑通了,有一定说服力;
- 分层训练的顺序效应值得深挖:课程学习(curriculum learning)的思路其实早就有了,但这篇论文在数据质量维度上做了清晰的量化验证,给了一些新的实践依据;
- L4 是最难落地的一层:结构化知识、事实验证、知识图谱——这些在实际工程中成本极高,论文对这一层的描述相对薄弱,未来可能是最有挑战也最有价值的方向;
- 音频/语音数据同样适用:UltraData 主要讨论了文本数据,但这套分层思路对语音、多模态数据同样有参考价值,这个会专门整理到一篇博客中。
- 本文标题:专题分享 | UltraData:大模型时代数据分层管理体系 (I)
- 创建时间:2026-02-13
- 本文链接:2026/2026-02-13-UltraData/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!