专题分享 | UltraTTSData:语音合成数据分层管理体系 (II)
参考清华大学与面壁智能提出的 UltraData(详见解读)——文本 LLM 数据分层管理体系,类比到 TTS 语音合成场景下,可以作为语音合成的「训练数据管理」指南。基于分层数据管理思想,构建 T0-T4 共五层级体系,主要出发点:
- 数据与模型协同进化
- 质量梯度分层
- 适配不同训练阶段
- 注重成本与收益平衡
为区别于 UltraData( 中采用的 L0-L4 层级体系,本文中的 T0-T4 中 T 可以简单理解为 Tier(层级) 或者 TTS 的缩写。
提示
- 参考论文:Data Science and Technology Towards AGI Part I: Tiered Data Management
- 论文链接:https://arxiv.org/pdf/2602.09003
- 项目地址:https://ultradata.openbmb.cn/
- 其他资料:https://mp.weixin.qq.com/s/zw0_6yMQc6om-M2qLdd6yg
一、TTS 语音数据核心划分
- 质量梯度分层:按「原始→可用→优质精细→多维度高阶→对话交互」构建数据,匹配不同层级的模型能力
- 训练阶段适配:
- 低层级(T0-T1)支持预训练
- 中层级(T2-T3)支持精调/功能强化
- 高层级(T4)支持更高阶的自然对话能力
- 信息维度扩展:从简单「语音+文本」数据,逐步新增补充属性、副语言、控制指令等更多「元信息」,实现从「能合成」到「会表达、可编辑、强交互」
- 工程可用性:明确各层级的数据标准与处理方法,区分基础与高阶数据,平衡成本与收益问题
- 模型深度参与:全流程大量应用「语音理解大/小模型」来辅助数据清洗、标注,实现数据管理的深度优化
二、五层级数据管理体系
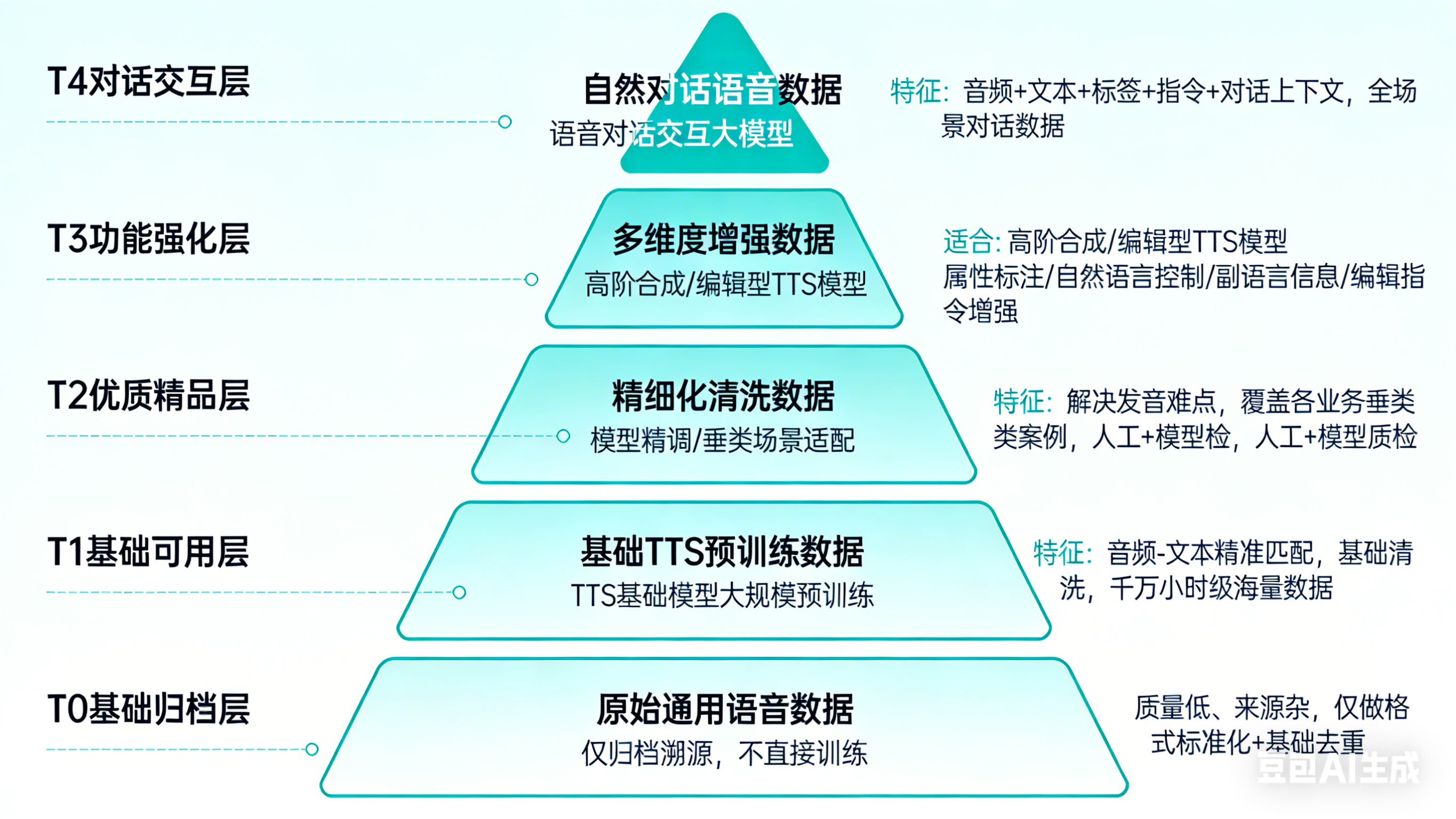
- 各层级由 owner 负责人细化工作细节,并且能落实数据质量,做好数据积累
- 每个层级都还有很多优化点,包括数据处理方法、使用的模型、效果的评估等
T0 - 基础归档层:原始通用语音数据
- 核心定位:原始数据备份,仅作为归档和溯源,不能直接用于训练
- 数据特征:开源数据或自主爬取网络/APP应用端数据,数据质量低(噪音多、来源杂、发声不标准、有效数据密度低)
- 核心处理:音频格式标准化、基础去重、长音频数据库构建(保留数据源/分区/语种/作者等信息,方便后续高阶使用与筛选)
T1 - 基础可用层:基础TTS预训练数据
- 核心定位:TTS专属基础开源数据,「音频-文本」精准匹配,支持大规模模型预训练
- 数据特征:已基础清洗,发声准确清晰、无明显噪音,语种/性别等基础维度分布较均匀,无过多精细化筛选
- 质控标准:音频采样率≥24kHz、文本准确、分割后的短音频长短适中
- 核心处理:VAD+说话人聚类、多模型ASR、DNSMOS等方式控制音质
- 数据量级:通用基础数据,量级在数百万到千万小时量级
- 训练场景:TTS基础模型大规模预训练
T2 - 优质精品层:精细化清洗数据
- 核心定位:T1基础上定制化清洗和扩充,解决 T1 仍然存在的数据缺陷,支持模型 CPT 与精调
- 数据特征:
- 覆盖生活用词/多音词/超短句/长难句(重复文本、口头禅)等难点问题
- 关注语气词、语调(疑问/感叹…)、儿童化声/轻声等细节发声问题
- 停顿不自然(专有名词、引发犹豫的停顿)
- 业务场景类 case:
- 英语教学:中英文混合、自然朗读/音标音节
- 适配各学科场景的文本(数学公式/化学方程式/古诗/文言文…)
- 数据来源:T1优质数据为基础、定向采集/处理的数据、基础业务case数据
- 质控标准:T1优质数据升级,人工抽检比例≥x%、模型质检准确率≥9x%
- 训练场景:基础模型质量精调、特殊场景适配、轻量级领域模型预训练
SFT 数据,可以合并到 T2 层级(带有业务属性的精品数据)
T3 - 功能强化层:多维度增强数据
- 通用特征:继承T2优质特征,新增结构化多维度的 meta 信息/控制指令,支持模型实现更高阶的合成能力
- 细分类型:
- T3-1:属性标注增强——拟人化表达
- 核心特征:新增性别、年龄、情绪标签、风格标签、重读标签
- 核心数据:各种属性标签、多情绪/多风格数据
- 训练场景:拟人化TTS模型训练(情绪/风格可控)
- T3-2:自然语言描述控制——自由文本控制
- 核心特征:新增自然语言描述指令,实现「文字描述即合成效果」
- 核心数据:多指令匹配数据、跨风格描述数据、情感精细化描述数据
- 训练场景:自然语言控制TTS模型训练(自由控制风格/情绪)
- T3-3:副语言信息增强——提高真实感
- 核心特征:新增字/词级副语言或语气标注
- 核心数据:副语言类型(笑声/感叹/咳嗽)
- 训练场景:高自然度TTS模型训练(接近人类自然表达)
- T3-4:编辑指令增强——高阶编辑能力
- 核心特征:新增音色/风格/局部修改精细指令,实现精细化定制
- 核心数据:音色设计&编辑数据、风格编辑数据、局部修改数据
- 训练场景:高阶编辑TTS模型训练(音色/风格编辑、局部修改)
- T3-1:属性标注增强——拟人化表达
T4 - 对话交互层:自然对话语音数据
- 核心定位:最高阶数据,支持语音对话交互大模型,实现更自然真实感的对话效果
- 数据特征:多维度全场景,音频+文本(+标签+指令) + 对话上下文,核心为对话类数据
- 质控标准:继承 T1&T2 数据,强调连贯对话、交互自然、场景适配
- 核心数据:通用对话数据、教育场景教学对话数据(一对一讲课交互)、通过大模型合成对话数据…
- 训练场景:语音对话交互大模型训练
三、实施阶段补充事项
- 语音理解模型(专项小模型或通用大模型)用于数据处理:
- 低阶模型(VAD/ASR/强制对齐…)负责完成 T0-T2
- 高阶模型(语音理解/Caption/端到端大模型…)处理/评估 T3-T4
- 分层实施:先可靠地实现T0-T2,再扩展T3和T4
- T2 和 T3 在现阶段业务需求下较为重要
- T4 在上下文感知、尤其是语音对话/端到端语音大模型更加关键
- 数据复用:低层级的优质数据作为更高层级的数据基础,复用减少重复获取和处理
- 强化学习:从 T2 到 T1 层级之后,做强化学习还需要一些后续训练的偏好数据,用来优化 RM 或者直接用于 RL
- 人机协同:对于 T2-T4 等高阶数据,模型处理后可能需要人工抽检,平衡效率与质量
- 数据合成:利用已训练的模型或者第三方优质模型,持续合成高阶稀缺数据并做筛选。
- 本文标题:专题分享 | UltraTTSData:语音合成数据分层管理体系 (II)
- 创建时间:2026-02-15
- 本文链接:2026/2026-02-15-UltraTTSData/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!