- 论文题目:MOSS-Audio-Tokenizer: Scaling Audio Tokenizers for Future Audio Foundation Models
- 论文链接:https://arxiv.org/pdf/2602.10934
- 开源代码:https://github.com/OpenMOSS/MOSS-Audio-Tokenizer
- 模型地址:https://huggingface.co/OpenMOSS-Team/MOSS-Audio-Tokenizer
- 作者单位:上海创新研究院、复旦大学(邱锡鹏团队)
- 发表日期:2026年2月12日
- 主要工作:提出了 CAT(Causal Audio Tokenizer with Transformer)—— 参数量达 1.6B 的 MOSS‑Audio‑Tokenizer。基于纯 Transformer 架构,在 300 万小时多类型音频数据上完成预训练,可对语音(Speech)、音效(Sound)、音乐(Music)实现高保真重建,并支持可变比特率语音生成。进一步提出纯自回归 CAT‑TTS 模型,性能超越非自回归与自回归+非自回归级联的系统。
论文背景
当下大语言模型(LLM)统一了文本(自然语言处理与理解)领域,如何将 LLM 的自回归建模能力迁移到音频/语音模态,成为了语音、音乐、音效生成的重要课题。其中,离散音频 Tokenizer 是连接原始音频/语音信号与自回归语言模型的关键桥梁。现有音频 Tokenizer 的局限性为:一方面,大多依赖预训练的语音编码器(Speech/Audio Encoder),相当于还需要提前训练/获取可靠的语音编码器的表征;另一方面,CNN/Transformer混合架构,CNN 结构的归纳偏置/先验设计,限制了重建保真度和模型可扩展性。
在上述背景下,本文提出了一套全新解决方案:基于纯 Transformer 的因果(Causal)结构的音频 Tokenizer 架构 CAT,并在此基础上构建了 16 亿参数(1.6B)的大规模音频 Tokenizer,称为 MOSS-Audio-Tokenizer。
该 Tokenizer 通过端到端训练 + 300 万小时多领域音频数据预训练,在语音、音乐通用的音频场景下实现了全码率的高保真重建,让基于 LLM 的 自回归 TTS 模型,超越了非自回归以及级联的 TTS 方案;Tokenizer 同时还具有竞争力的 ASR 性能(没有使用额外的预训练编码器模块)。
本文从核心痛点、核心设计、模型实现、实验效果、核心贡献这几个维度,重点解读这一个这个通用 Tokenizer 的主要设计。
一、音频 Tokenizer 核心痛点:难以适应应用需求
文档 Tokenizer 的成功,核心在于为 LLM 提供了统一的离散接口,让模型能直接对原始文本进行自回归建模,兼具压缩、理解、生成和上下文学习能力。
但音频与文本不同,它同时包含细粒度的声学细节和长距离的结构信息,离散化 tokenization 的难度远高于文本。
现有音频 Tokenizer 的设计存在三大核心问题,使其难以成为音频大模型的通用基础:
- 架构异构化,可扩展性差:多采用 CNN 或 CNN/Transformer 混合架构,引入 inductive bias,模型参数、训练数据、量化能力无法统一规模化;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
161. CNN 的 inductive bias 是什么?
CNN 在设计上假设"局部相关性"和"平移不变性"——即卷积核用固定大小的感受野在时序/频率上滑动提取特征。这种设计是"写死"在架构里的,无法通过增大数据或参数来消除。
2. 为什么论文把它称为"归一化偏移"或"归一化偏置"?
在音频 Tokenizer 领域,CNN 编解码器(如 Encodec、DAC)通常包含:
- 固定步长的下采样卷积:帧率(如 75Hz)由卷积步长硬编码决定,无法灵活改变
- 固定的感受野大小:捕获长距离依赖的能力受限,必须靠堆叠层数或加 Transformer 来补偿
- 层归一化/权重归一化的特定初始化偏置:CNN 在不同卷积层之间的归一化方式(如 WN、GN)会引入对特定信号分布的假设
这些因素合在一起,就是论文里说的"固定的归一化偏移"——架构层面对输入信号特性的强先验假设,固化在 CNN 的卷积结构里,无法随数据/参数规模化而自适应改变。
3. 对比纯 Transformer 架构
纯 Transformer(CAT)的自注意力机制没有这种硬编码的局部先验,序列中任意位置之间都可以建立依赖,归纳偏置极小,因此:
- 帧率、感受野范围随训练数据和参数量可以自适应
- 更容易做到 scaling(模型规模化 = 性能提升)
总结:这里的"归一化偏移"本质上是 CNN 架构的 inductive bias(归纳偏置),是 CNN 对局部感受野、固定下采样率等的结构性假设,限制了模型的可扩展性和灵活性。 - 多阶段训练流程,依赖外部预训练:多采用分阶段训练(Tokenizer Decoder 单独训练)、预训练编码器特征(依赖预训练模型)等方式,引入额外依赖,难以实现全组件联合优化;
- 功能单一,适应性弱:部分模型仅优化重建保真度,缺乏语义信息;部分模型针对特定场景(如语音);同时帧率、码率灵活性不足,难以满足自回归建模的低延迟、可变码率需求。
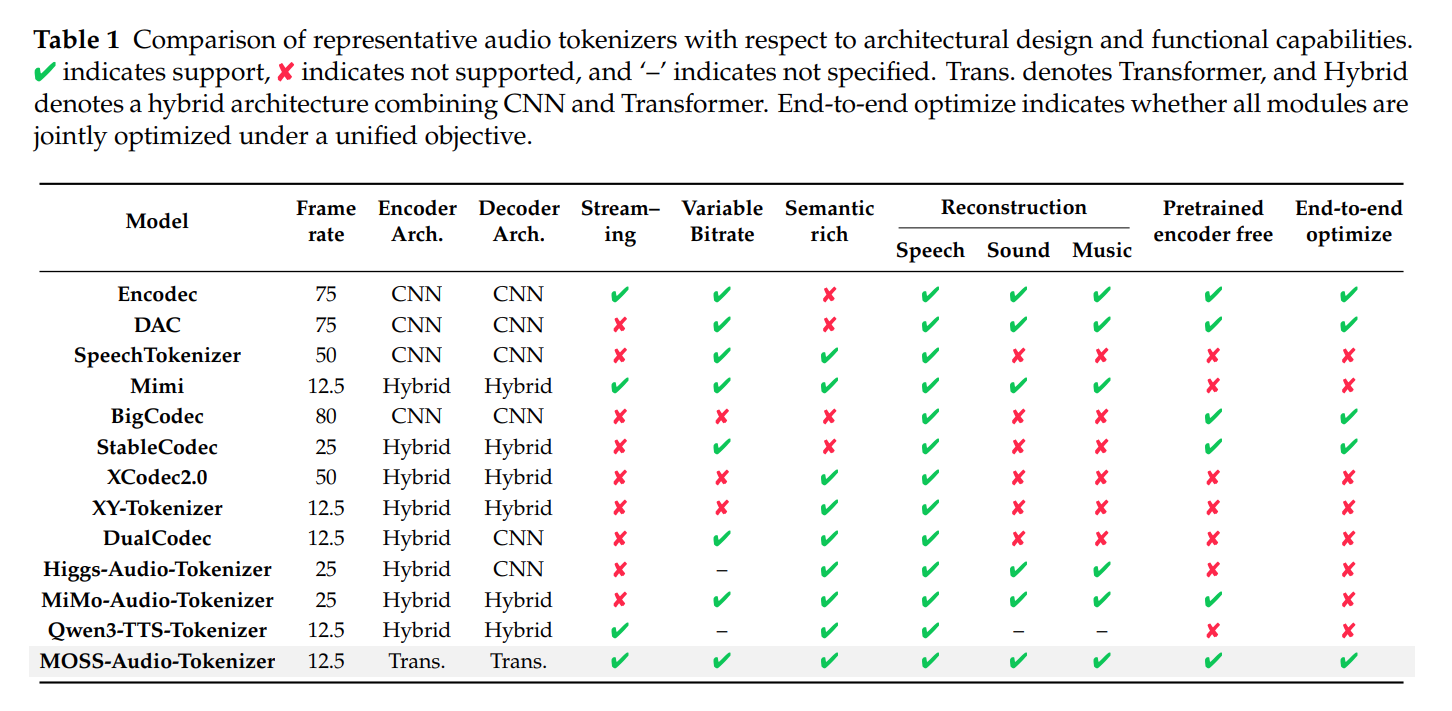
可以看出,MOSS-Audio-Tokenizer 是目前唯一集合所有优势的 Tokenizer 方案,每一个维度都是这个 Tokenizer 的优势:
| 核心特性 | MOSS-Audio-Tokenizer | 主流模型(Encodec/DAC/SpeechTokenizer) |
|---|---|---|
| 模型架构 | 纯 Transformer | CNN / 混合架构 |
| 端到端优化/不依赖预训练 | ✅ 全组件联合 | ❌ 分阶段 / 依赖预训练 |
| 通用音频重建能力 | ✅ 语音 / 音效 / 音乐 | ❌ 仅语音 / 部分支持 |
| 流式处理 | ✅ | ❌ 部分不支持 |
| 可变码率 | ✅ 0.125-4kbps | ✅ 码率限制性强 |
| 语义丰富 | ✅ 音频 - 文本对齐 | ❌ 仅优化重建 |
| 帧率 | 12.5Hz(低) | 25/50/75Hz(高) |
总结来说,论文提出了音频 Tokenizer 的四大设计原则,也是 CAT 架构的核心设计思想:
- 统一化的音频表征:能建模并重建语音、音效、音乐等多领域音频,同时保留声学细节和语义结构;
- 架构简单扩展性强:采用同质化的 Transformer 架构,去除对 CNN(异构)及归一化偏移的依赖,支持模型、数据、计算的联合规模化;
- 严格因果性支持流式:保证 token 计算不依赖未来音频上下文,适配自回归生成和低延迟处理;
- 低帧率 + 码率限制性:低帧率降低下采样序列建模复杂度,全码率限制性(可变码率)支持一个模型多种码率使用方式,针对不同场景多无需重新设计/训练。
二、核心设计:纯 Transformer 的因果 Tokenizer
CAT(Causal Audio Tokenizer,简称为 CAT)是纯 Transformer 架构的离散音频 Tokenizer,彻底摒弃了 CNN 组件。
以因果 Transformer 为核心构建架构,实现了编码器 encoder、量化器 quantizer、解码器 decoder、判别器 discriminator、semantic task LLM 的完全端到端优化,自然适配自回归建模和流式处理。
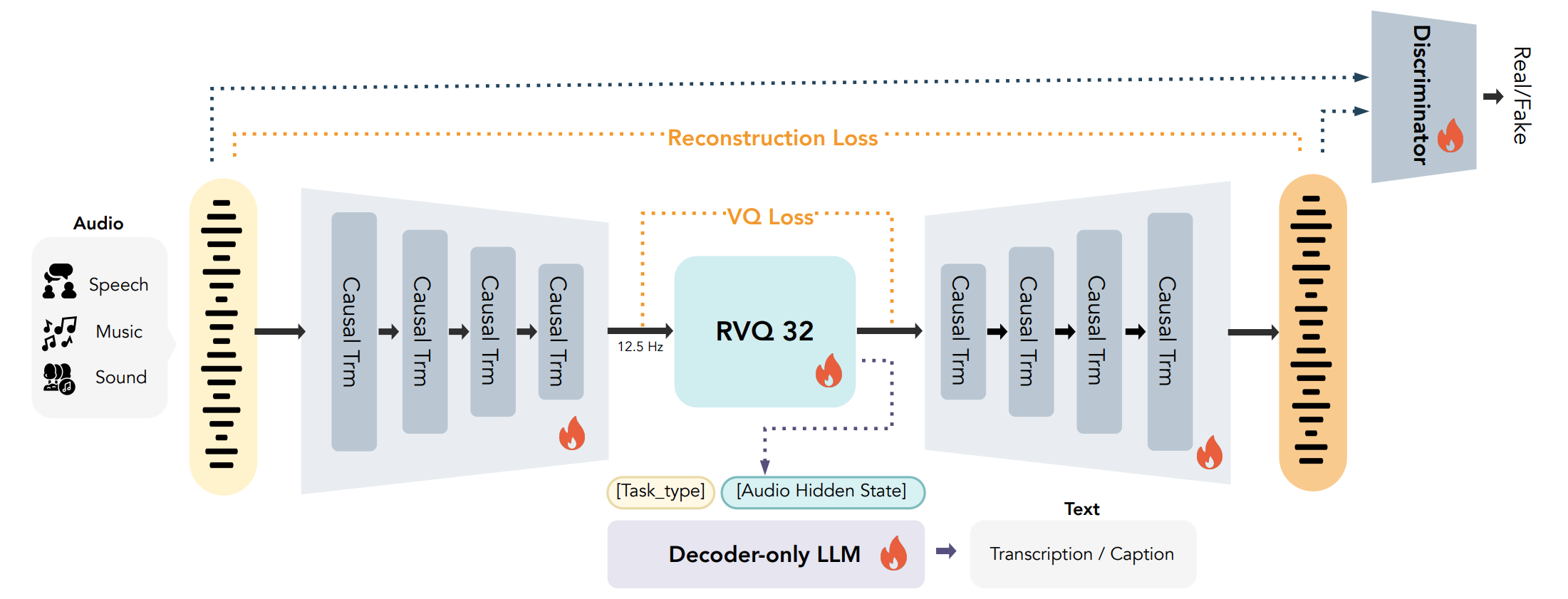
2.1 纯 Transformer 编解码器 + 因果流式
CAT 的编码器和解码器均由因果 Transformer 层堆叠而成,直接对 24kHz 的原始音频波形进行处理,无需梅尔频谱等中间表征,核心设计包含:
- 渐进式 Patchify(逐步下采样):编码器对输入波形进行分块,并在 Transformer 层之间进行下采样,最终帧率为 12.5Hz(低帧率能降低下采样建模复杂度);
- 对称解码(Encoder/Decoder 对称结构):解码器以完全对称的方式上采样恢复到 24kHz,从离散 token 中重建原始音频波形;
- 流式生成能力:全因果设计让编码器和解码器均支持帧级别流式编解码,实现低延迟处理,训练和处理完全一致。
2.2 可变码率的残差向量量化(RVQ)
CAT 采用 32 层残差向量量化(RVQ)实现音频的离散化,核心优化点:
- 向量量化:每层量化器的码本通过梯度下降直接优化,无需额外的码本更新机制(比如 EMA 之类),而是直接 codebook loss 和 commitment loss,简化训练并提升稳定性;
- 量化器 Dropout:训练时随机丢弃部分量化层,让模型自然支持 0.125kbps 到 4kbps 的可变码率,为下游可变码率生成提供基础(SoundStream 也使用了类似的结构化 Dropout 机制);
- VQ 码本设计:每层量化器采用 1024 大小的码本,latent 维度为 8,且码本进行了 L2 归一化,从而平衡量化精度和计算效率。
VQ-补充信息
- 关于第三点 VQ 码本设计的优化,实际均是来源于论文:https://openreview.net/forum?id=pfNyExj7z2,参考代码实现:https://gitlab.com/lucidrains/vector-quantize-pytorch
- latent 维度为 8,采用了「Lower codebook dimension」策略,或者称为 Factorized VQ,DAC 也采用了相同方案;
- 码本进行 L2 归一化,采用了 L2 范数限制,等价于 cosine sim 的约束 → 简单理解,是为了让量化前后的 embedding,在方向上保持一致性。

2.3 多任务联合训练:声学重建 + 语义建模
CAT 通过多任务学习,同时优化声学重建和语义表征学习,避免了「声学 - 语义」的取舍问题,让 token 同时具备声学细节和语义信息。
核心损失函数包含五大类,最终以加权组合形式构成生成器总损失:
- 语义损失:输入 0.5B 参数的 Decoder-LLM,以语音和音频理解任务(ASR、多说话人 ASR、音频描述)为监督,让 VQ 输出的表征能与语义对齐;
- 量化损失:包含 commitment 和 codebook 两个 loss,联合优化编码器和码本;
- 重建损失:采用多尺度梅尔谱损失;
- 对抗损失:引入多周期判别器和多 STFT 判别器;
- 特征匹配损失:feature matching loss 让生成器的中间特征与真实音频的特征匹配。
2.4 训练策略:Progressive Sequence Dropout
目标:支持可变码率生成,核心思想是:训练时随机截断 RVQ 的量化层前缀(只选择前几层),让模型适应不同码率的 token,无需修改架构或增加参数。
该策略的关键设计:
- 随机截断:以概率 p 触发 Dropout,触发后随机采样前缀长度 K,丢弃 K+1 到 32 层的 RVQ token;未触发 Dropout 时保留所有 32 层;
- 输入融合:将保留的前 K 层 RVQ token 的 embedding 拼接之后,作为 TTS 自回归模型的输入;
- 损失计算:仅对保留的前 K 层计算损失,让模型学习在不同码率下的生成。
推理时,只需指定推理深度 K_infer,即可控制组合的码率。
三、模型配置与实验结果
3.1 模型规模与架构
- 总参数:1.6B,其中编码器和解码器各约 0.8B,均由 68 个因果 Transformer 层构成;
- 编码器分 4 个阶段,隐藏维度依次为 768、768、768、1280,采用旋转位置编码(RoPE)和 FlashAttention-2 加速;
- 量化器:32 层 RVQ,每层码本大小 1024;
- 语义输出:0.5B 参数的 Decoder-Only LLM,用于语音/音频理解任务。
3.2 训练数据与配置
- 训练数据:300 万小时的多样化音频数据,覆盖语音(中英双语)、音效、音乐,包括纯音频和音频+文本配对数据;
- 训练方式:全端到端的训练,无预训练编码器、无语义教师模型、无分阶段训练;
- 训练策略:两阶段训练,先 52 万步无 adv loss 的预训练,再 50 万步加入 GAN 的 adv loss 进行微调;采用 AdamW 优化器,bf16 精度训练,全局批次大小最高达 1536;
- 硬件友好:支持流式处理,训练时采用滑动窗口注意力(10s),降低显存占用。
3.3 音频重建实验结果
在低(750-1500bps)、中(1500-2500bps)、高(2500-4000bps)不同的码率区间内,MOSS-Audio-Tokenizer 在语音、音效、音乐三大领域的重建质量均显著超越主流模型: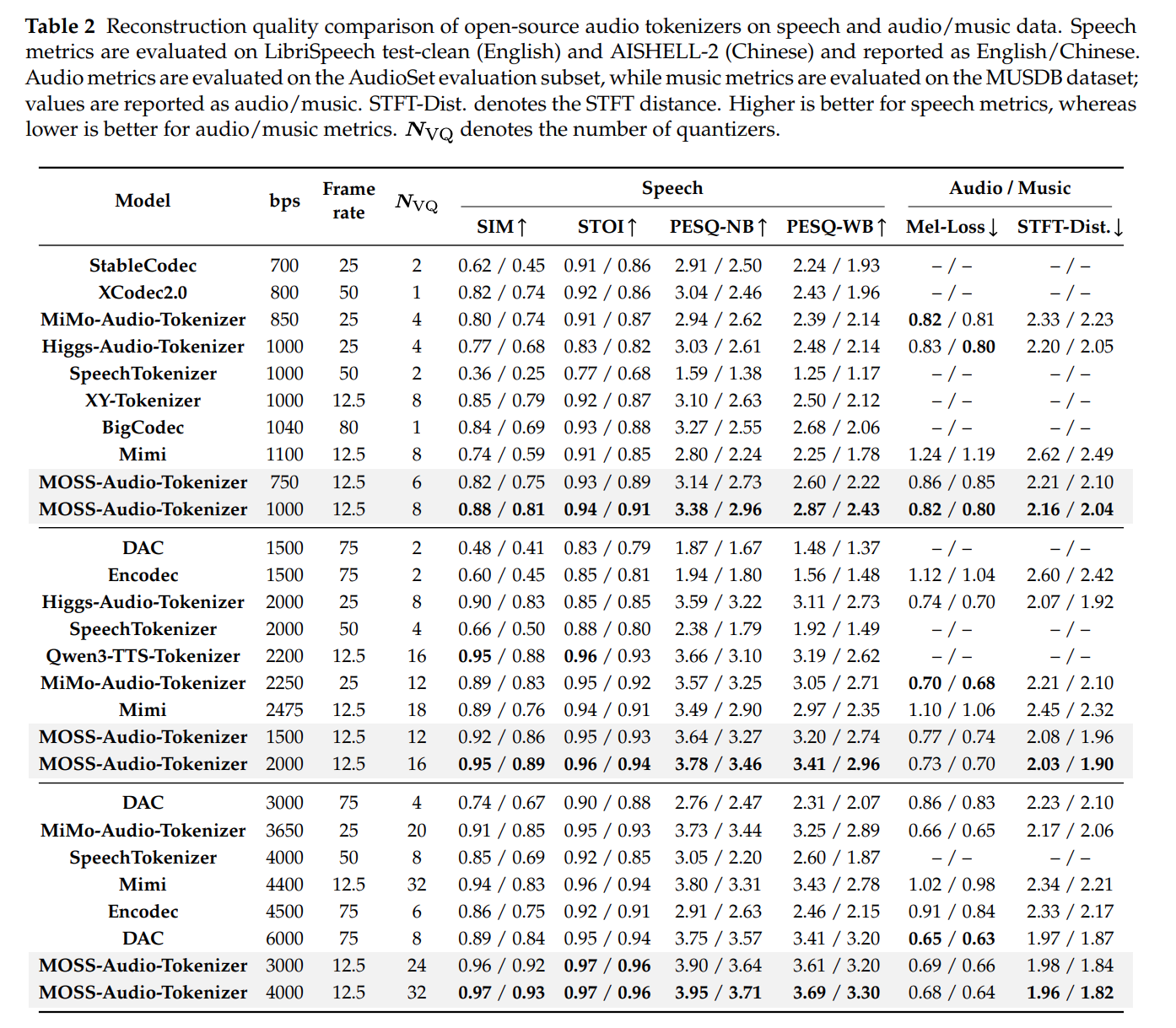

- 语音重建:在 LibriSpeech(英文)和 AISHELL-2(中文)数据集上,SIM(说话人相似度)、STOI(语音可懂度)、PESQ(语音质量)均为 SOTA;
- 音效 / 音乐重建:在 AudioSet(音效)和 MUSDB(音乐)数据集上,梅尔谱损失和 STFT 损失均显著低于竞品,且码率越高,性能提升越明显,体现了良好的扩展性;
- 主观评价:基于 MUSHRA 协议的人工打分显示,MOSS-Audio-Tokenizer 在 600-4200bps 全码率区间内的主观得分均为最高,且低码率下性能下降远慢于 Encodec、DAC 等模型。
3.4 CAT 基础上的 CAT-TTS
基于 CAT 的 token 实现了纯自回归离散 TTS 模型性能超越非自回归(NAR)和级联(AR+NAR)系统。CAT-TTS 结构示意图: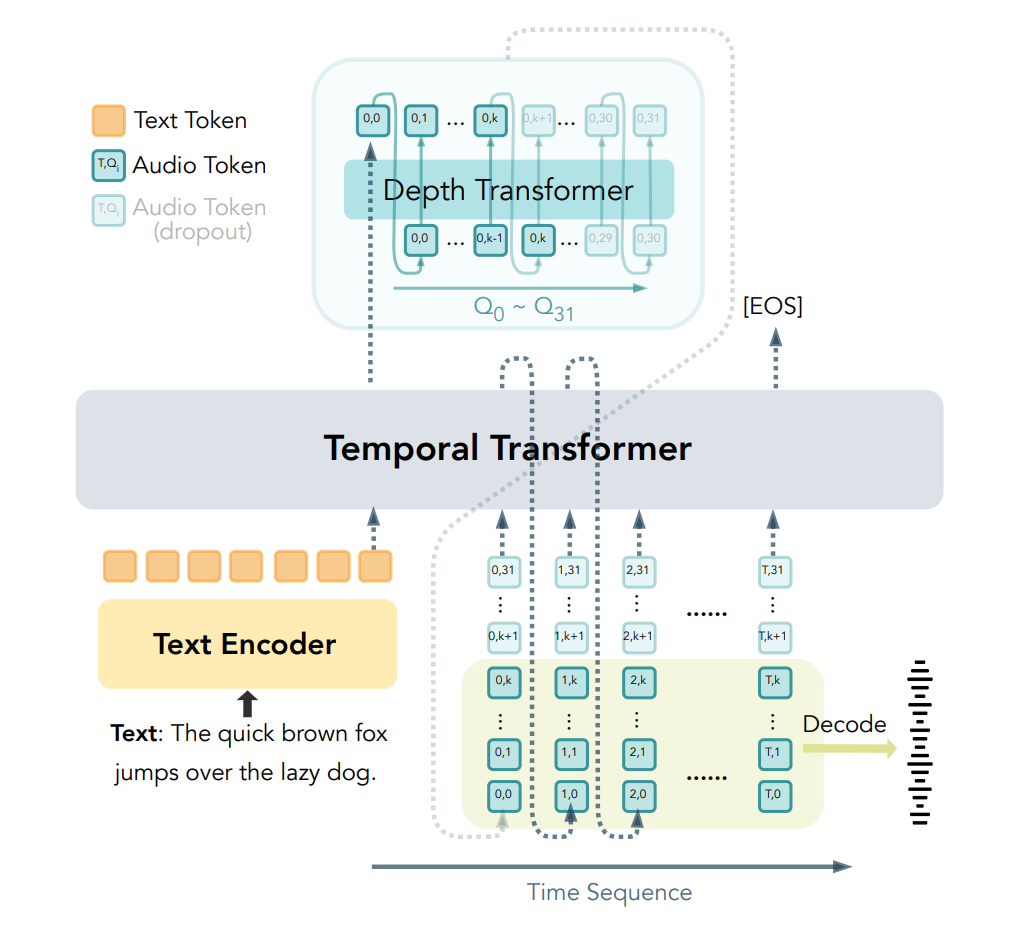
核心实验结果:
Progressive Sequence Dropout 的有效性:采用该策略的模型在低码率下的性能下降幅度大幅降低,且 dropout 概率 p=10 时训练效率最高;
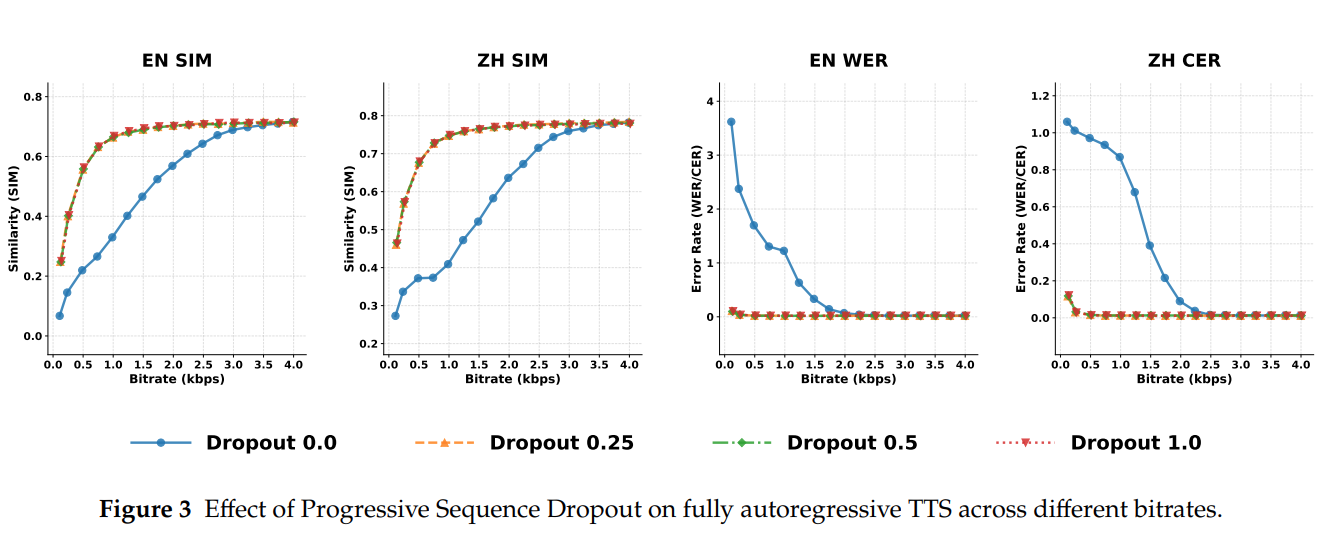
Seed-TTS-Eval 基准测试:在英文和中文字符错误率(WER/CER)接近 SOTA 的前提下,说话人相似度(SIM)达到 0.731(英文)/0.785(中文),为所有开源模型最高;
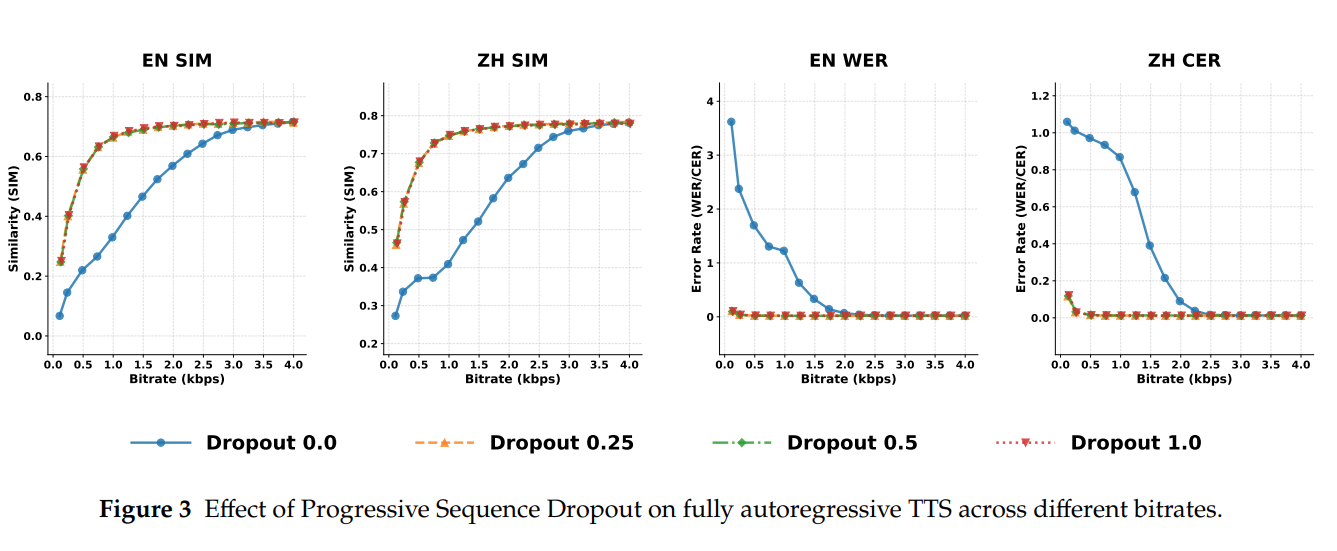
支持可变码率的 TTS:单模型支持 0.125-4kbps 的可变码率组合,且不同码率下的生成质量均保持稳定,而其他模型大多需要切换模型 / 帧率才能实现可变码率。
3.5 语音理解能力
将 CAT 的离散 token 直接输入 Qwen3-1.7B LLM,构建 CAT-ASR,无需额外的预训练语音编码器或对齐/特征监督,仅通过 200 万小时音频&文本配对数据训练,即可实现有竞争力的 ASR 性能: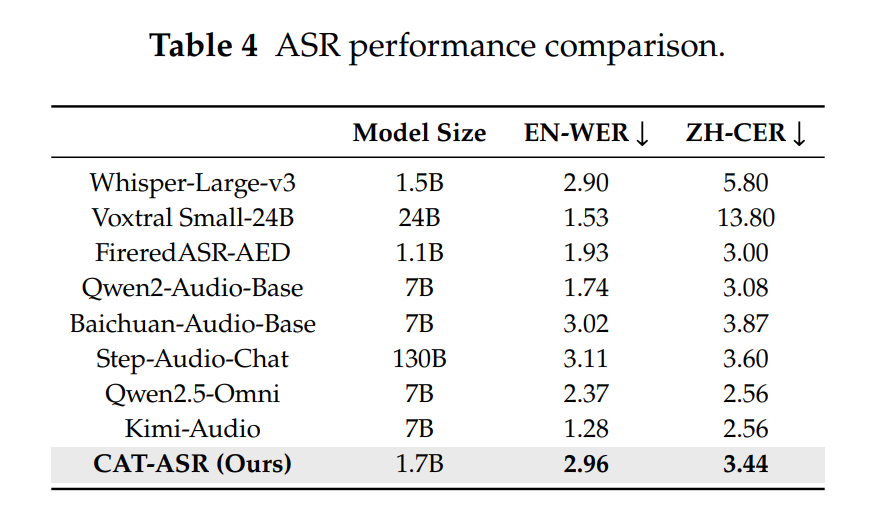
- 英文 LibriSpeech test-clean:WER=2.96%,接近 Whisper-Large-v3(2.90%);
- 中文 AISHELL-2:CER=3.44%,优于 Baichuan-Audio-Base(3.87%)和 Step-Audio-Chat(3.60%);
- 核心意义:证明 CAT 的 token 不仅保留了声学细节,还包含足够的语义信息,与文本表现良好对齐,可直接作为音频大模型的输入接口。
3.6 不同因素消融实验
论文重点验证了 CAT 架构的规模化特性,这是其成为下一代音频基础模型的关键:
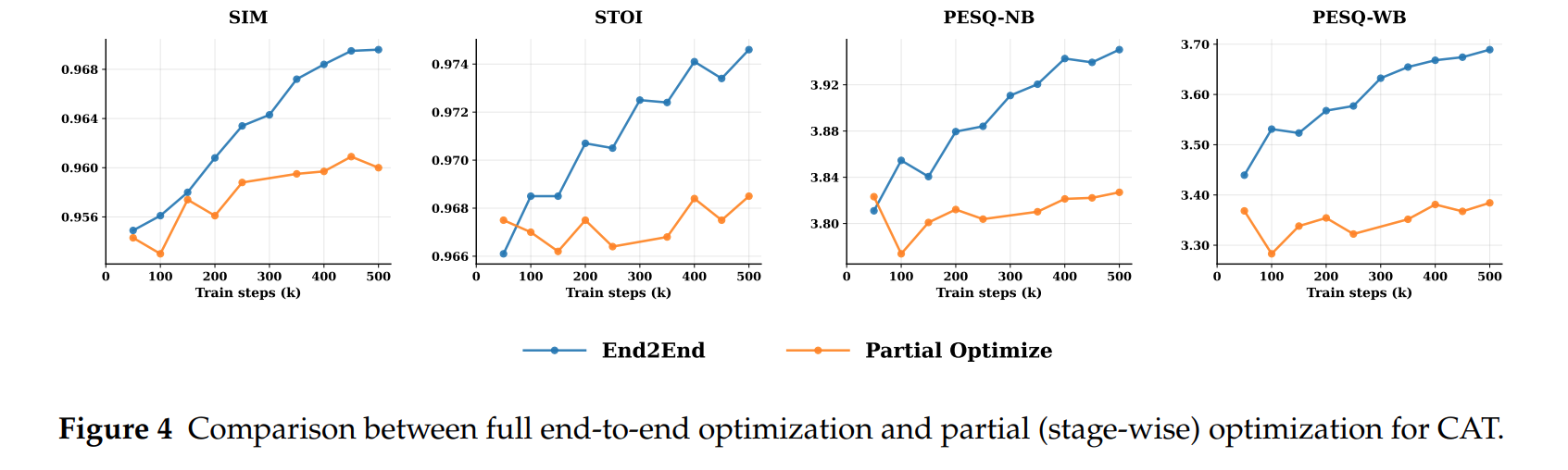
端到端优化的重要性:全端到端训练的模型性能随训练步数持续提升,无早期饱和;而分阶段训练(冻结编码器 / 量化器)的模型性能快速收敛,难以进一步提升;
模型参数规模化:从 319M 到 1169M 参数,重建质量在全码率区间持续提升,高码率下提升更显著;
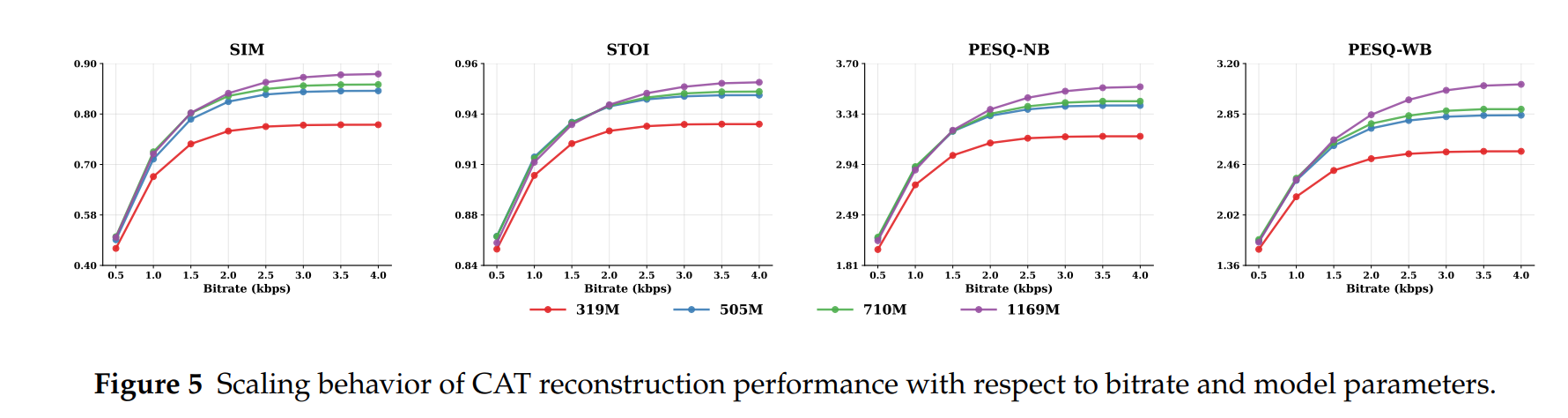
训练数据规模化:训练批次大小从 1 提升到 256,所有语音重建指标(SIM/STOI/PESQ)均持续提升,且大批次在相同训练步数下能实现更高的性能;
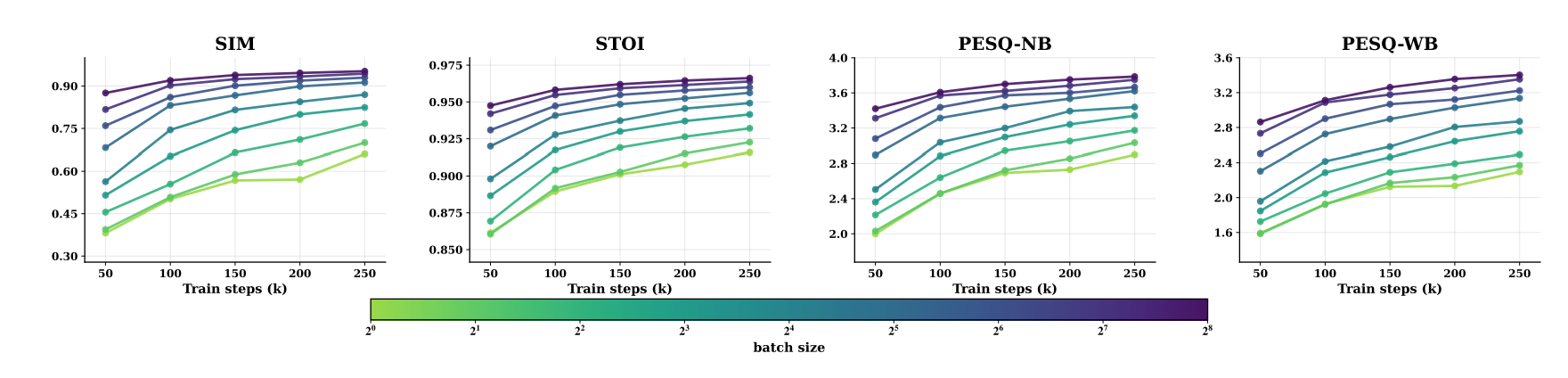
VQ 能力与模型参数协同规模化:模型参数和 RVQ 量化层数需同步扩展,单一维度的规模化会形成性能瓶颈,而 CAT 的端到端架构支持二者的协同优化。
四、总结与展望
| 核心贡献内容 | 关键细节 |
|---|---|
| 提出首个纯 Transformer 的音频 Tokenizer 架构 | CAT 架构摒弃 CNN 组件,以因果 Transformer 层为核心;实现架构简洁性与扩展性统一,最小化归一化偏移;为音频 Tokenizer 规模化提供全新范式 |
| 构建 1.6B 参数的大规模通用音频 Tokenizer | 基于 CAT 架构构建 MOSS-Audio-Tokenizer,经 300 万小时多领域音频全端到端预训练;实现语音、音效、音乐的统一表征;支持 0.125-4kbps 可变码率、流式低延迟处理;属于目前功能最全面的开源音频 Tokenizer 之一 |
| 实现纯自回归音频生成的突破 | CAT-TTS 提出 Progressive Sequence Dropout 训练策略;让纯自回归 TTS 模型性能超越非自回归和级联系统;实现单模型可变码率生成,简化音频生成系统设计、降低错误传播 |
| 验证了音频 Tokenizer 的规模化规律 | 系统验证了模型参数、训练数据、计算量、量化能力的协同规模化规律;证明端到端优化的 CAT 架构可将计算资源直接转化为重建质量和语义表征能力;为后续更大规模音频基础模型研究提供指导 |
- 本文标题:语音合成 | MOSS-Audio-Tokenizer:大数据驱动的通用音频 Tokenizer
- 创建时间:2026-02-28
- 本文链接:2026/2026-02-25-MOSS-Audio-Tokenizer/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!