TTS 范式变化与 LLM+RVQ 的回归
摘要:Qwen3‑TTS 用更强的低帧率多码本 Tokenizer + 纯自回归 Dual-AR LLM,把 TTS 从 “LLM+DiT 级联” 拉回 “大道至简” 的 LLM+RVQ 历史路线,实现 97ms 超低延迟、3 秒零样本克隆、10 语言跨语言合成与指令可控音色,与 MOSS-TTS/FishAudio S2 同期工作一起,宣告 TTS 正式回到 “Tokenizer 优化+强化学习后训练” 的关键时期。
回顾过去两年 TTS 技术的演进,可以清晰地看到三条主线:
- 2023年开始,以 VALL-E / SpearTTS 为代表的 AR 方案证明了「离散语音 token + 语言模型」的可行性,但受限于 token 的语义贫乏和级联误差,生成质量和稳定性始终存在瓶颈。
- 2024 年中至 2025 年初,CosyVoice / Minimax-Speech/ IndexTTS 系列方案转向「LLM 建模语义 token + Flow Matching/DiT 解码声学细节」的思路,用 DiT/Flow Matching 做声码器来补偿单码本的信息损失,在质量和说话人相似度上取得了显著进步;但 DiT 的引入也带来了延迟偏高、流式设计繁琐、核心能力来自 LLM 但无法独立评估等问题。
- 2025 年至今,随着语音 Tokenizer 技术的快速进化(Mimi / MOSS-Audio-Tokenizer / Qwen-TTS-Tokenizer-12Hz 等),多码本 RVQ Tokenizer 能在极低帧率(12.5Hz)下同时编码语义和声学信息,使得「纯 LLM 自回归 + 轻量级解码模块」的架构重新成为可能。LLM 通常对应的就是 Dual-AR 的范式,即:时间维度上使用全局的语义 LLM、层数维度上使用局部的 RVQ LLM。
Qwen3-TTS 正是在这一背景下诞生的——它并非简单地重复 VALL-E 时代的 AR+RVQ 旧路,而是在 Tokenizer 能力、训练数据规模和后训练对齐三个维度上实现了质的飞跃,将 TTS 的范式重新拉回 LLM + RVQ 这条路线,并以此证明:当 Tokenizer 足够强、数据足够多、对齐做得足够好时,纯自回归架构或许才是 TTS 的最优解。
与 Qwen3-TTS 不约而同的是,近期的 MOSS-TTS(复旦邱锡鹏团队)、Fish-Audio S2(FishSpeech 系列的技术方案) 等工作也基本采用了相似的技术路线。这或许不是巧合,而是整个社区对 TTS 技术范式「大道至简」的一次复盘——低帧率多码本 Tokenizer + 纯自回归 LLM 已成为当前最具共识的技术方向。
论文标题:Qwen3-TTS Technical Report
论文链接: https://arxiv.org/abs/2601.15621
官方宣传: https://qwen.ai/blog?id=qwen3tts-0115
关键词: 多语言、多码本 Tokenizer、低延迟流式
一、Qwen3-TTS 概述
Qwen3-TTS 的训练基于 500 万小时+ 的多语言语音数据(支持 10 种语言),其中 12.5Hz Tokenizer + LLM 变体是开源主推模型。Qwen3-TTS 12.5Hz 方案的核心特性为:
- 强大的语音表征:基于自研 Qwen-TTS-Tokenizer-12Hz(实际帧率 12.5Hz,与 Moshi 的 Mimi、MOSS-Audio-Tokenizer 等设计思想一致),实现了语音信号的高效声学压缩与高维语义建模,能够完整保留副语言信息及声学特性,并可通过轻量级的 Detokenizer/Codec Decoder(非 DiT 架构)实现高效、高保真的语音还原。
- 通用的端到端架构:采用 RVQ 离散多码本 + LM 架构,实现语音生成任务的端到端建模,彻底规避传统 LM+DiT 方案的级联误差、LLM 无法单独评估等缺陷,显著提升模型的通用性、生成效率与效果上限。
- Dual-Track 双轨自回归:文本 token 和语音 token 沿通道轴拼接,主干网络预测语义码本、MTP 模块预测残差码本;这种快慢双轨架构结合更强大的 RVQ Tokenizer,成为新一代 TTS 架构的核心关注点。
- 极致的低延迟流式生成:基于 Dual-Track 混合流式架构,单模型同时兼容流式与非流式生成,最快可在输入单字后即刻输出音频首包,端到端合成延迟低至 97ms,满足实时交互场景的严苛需求;纯因果 ConvNet 解码器天然适配流式场景,延迟下限远低于 DiT 方案。
- 智能文本理解与语音控制:继承 Qwen3 LM 的文本理解能力,支持自然语言指令驱动的语音生成,灵活调控音色、情感、韵律等多维声学属性;训练中引入概率激活的 thinking pattern,提升复杂指令的遵循能力。
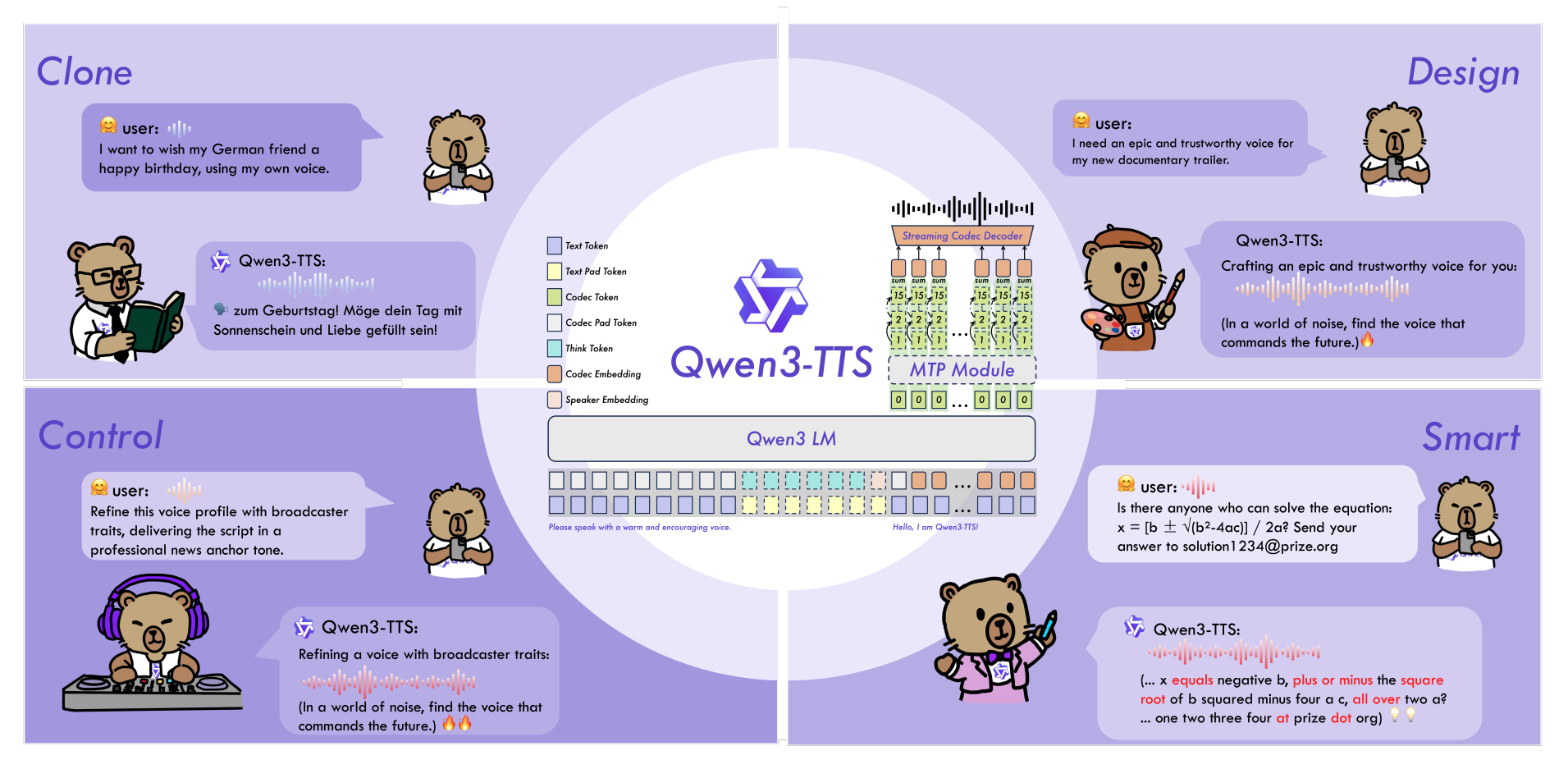
具体支持功能

- 高效语音克隆:支持 3 秒参考音频的零样本语音克隆,且能保持跨语言的说话人特征一致性;
- 精细化控制:通过自然语言描述生成全新语音 / 操控语音细粒度属性(韵律、风格等);
- 高自然度:1.7B 模型实现类人语音质量和自然度,兼顾感知质量与语义一致性;
- 超低延迟流式:12Hz 变体实现 97ms(0.6B) / 101ms(1.7B) 首包延迟,支持流式文本输入与音频输出;
- 长文本合成:稳定生成超 10 分钟流畅语音,无 block-wise 合成的边界伪影、重复 / 遗漏等问题;
- LLM 无缝集成:基于离散语音 token,可与 Qwen3 LM 系列模型高效协同,支持高并发推理;
- 音色设计功能:VD(Voice Design)模型支持自然文本描述来设计音色(抽卡可用的音色)。
二、核心技术架构
1. 两款语音 Tokenizer 设计
为平衡语义表达与低延迟流式需求,提出两款专用 Tokenizer,成为整个模型的基础:
(1) Qwen-TTS-Tokenizer-25Hz(未开源)
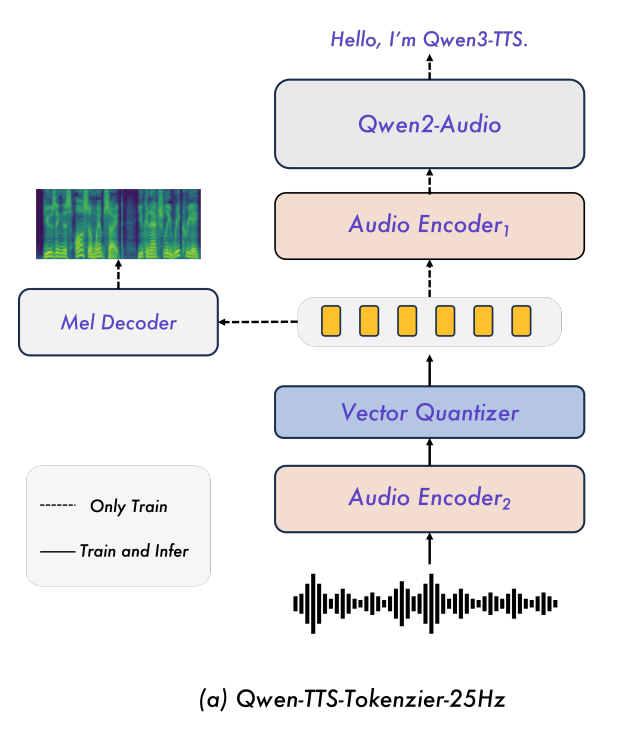
- 特性:25Hz 分词器,融合语义与声学线索,与 Qwen2-Audio 无缝集成;单码本。
- 训练:两阶段训练
① 第一阶段:先在 ASR 任务上继续预训练 Qwen2-Audio,模型中加入降采样(降低到 25Hz 帧率)和向量量化(VQ)层;
② 第二阶段:再通过卷积层微调 Mel 解码器,重建目标是梅尔特征,以此 token 注入声学信息(注意,此时应该还是保留了 ASR 的训练任务)。 - 流式解码:基于 Block 的流式 DiT,采用滑动窗口注意力(感受野为 4 个 Block),结合改进的 BigVGAN 声码器实现波形重建,适合高保真合成但延迟略高。
(2) Qwen-TTS-Tokenizer-12Hz
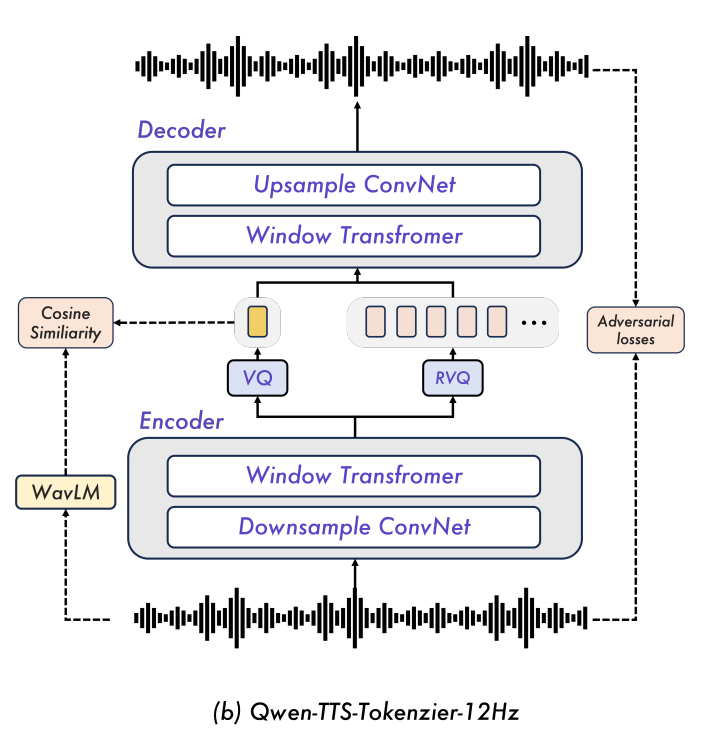
- 特性:12.5Hz 的16层多码本(RVQ)分词器,极致比特率压缩 + 超低延迟,是实现 97ms 首包的核心;
- 设计:基于语义 - 声学解耦的量化策略,第一层码本编码语义内容,后续 15 层捕捉声学细节 / 韵律;第一层语义内容是采用蒸馏 WavLM 的思想,让第一层 VQ 的 embedding 和 WavLM 输出的语义表征进行对齐(此处其实还是依赖于一个预训练的 WavLM 模型作为 teacher 模型);
- 训练:GAN 框架训练,生成器直接处理原始波形提取量化特征,判别器提升重建自然度,结合多尺度梅尔谱重建损失保证时频一致性;
- 流式解码:纯左上下文的因果编解码器结构,无 Look-ahead 的需求,生成 token 后可立即解码为音频;搭配轻量级因果 ConvNet 实现波形重建,无需说话人向量提取 / 复杂扩散模型。
2. Qwen3-TTS 主体架构
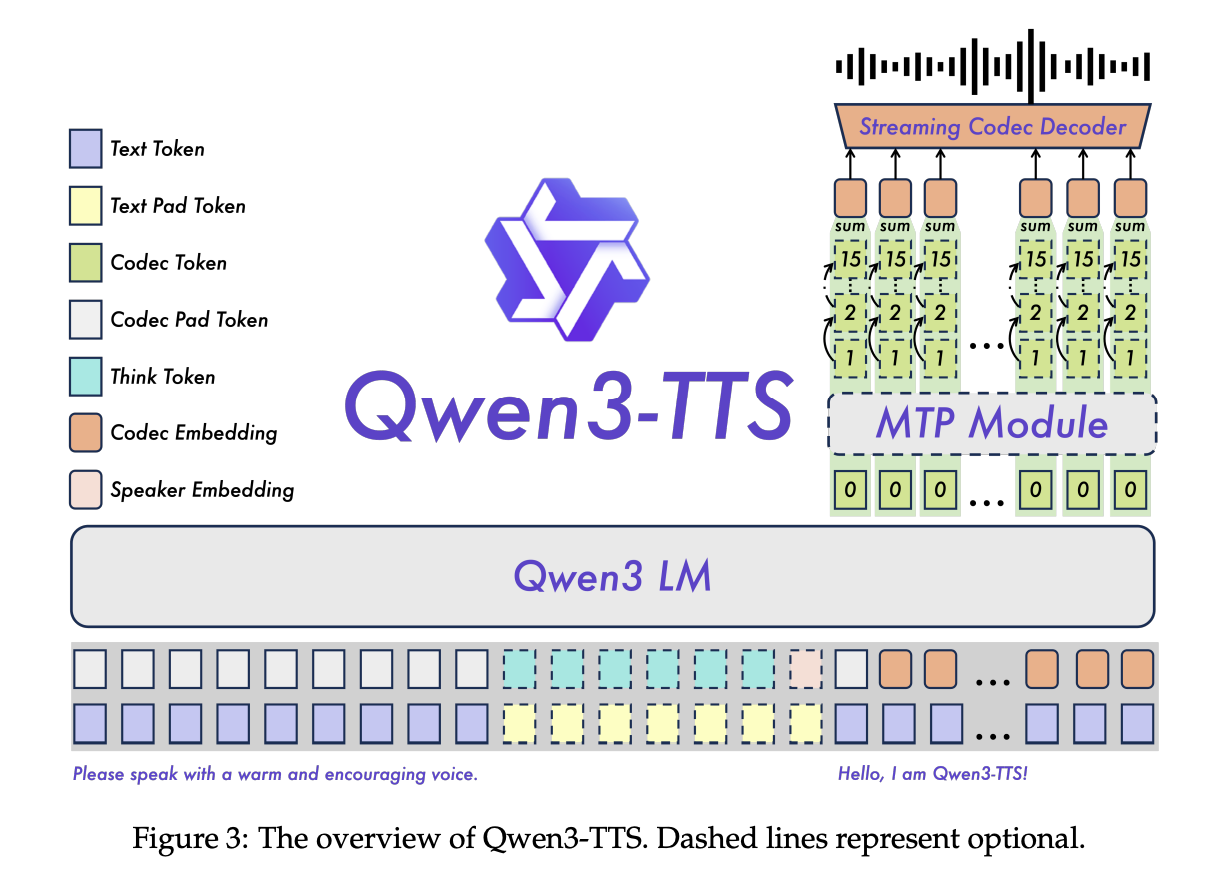
基于 Qwen3 LM 构建,将文本 token 与语音 token 沿时间轴拼接,分 25Hz 和 12Hz 两个变体:
- 25Hz 变体:提取单层的语音 token,主干网络融合文本特征与历史语音 token,自回归预测下一个 token,再经 block DiT 实现高质量语音合成;
- 12Hz 变体:处理 12Hz Tokenizer 的 RVQ 多码本 token,采用分层预测策略,主干网络聚合码本特征预测第 0 层码本,MTP(预测剩余 1-15 层的 token);支持单帧即时生成,最小化延迟。
说话人控制方式
- 联合训练可学习的说话人编码器(类似 Tortoise-TTS/Minimax-Speech),提供两种推理方式:
- 推理方式一:通过 speaker embedding 强化音色控制,属于 zero-shot;
- 推理方式二:直接使用 prompt 的文本和音频控制,属于 one-shot。
3. 分阶段训练策略 (预训练 + 后训练)
(1) 预训练(3 阶段)
- S1(通用阶段): 基于 500 万小时多语言数据训练,建立文本到语音的单调映射,具备基础的通用能力;
- S2(高质量阶段): 通过数据质量分层流水线,用高质量数据继续预训练,缓解噪声数据导致的”幻觉”,提升语音生成质量;
- S3(长上下文阶段): 将最大 token 长度从 8192 扩展至 32768,对训练集中的长语音进行数据上采样,增强长文本和感知上下文的能力。
(2) 后训练(3 阶段)
- 阶段 1 - DPO:直接偏好优化(DPO),基于人类反馈构建多语言的语音偏好对,对齐模型输出与人类偏好;
- 阶段 2 - GSPO:基于规则奖励结合 GSPO,提升模型的跨任务能力与稳定性;
- 阶段 3 - SFT:对基础模型进行轻量级说话人微调,提升语音自然度、表达性与可控性,适配特定的说话人特征。
4. 流式效率优化
不同Tokenizer在不同并发下的流式效率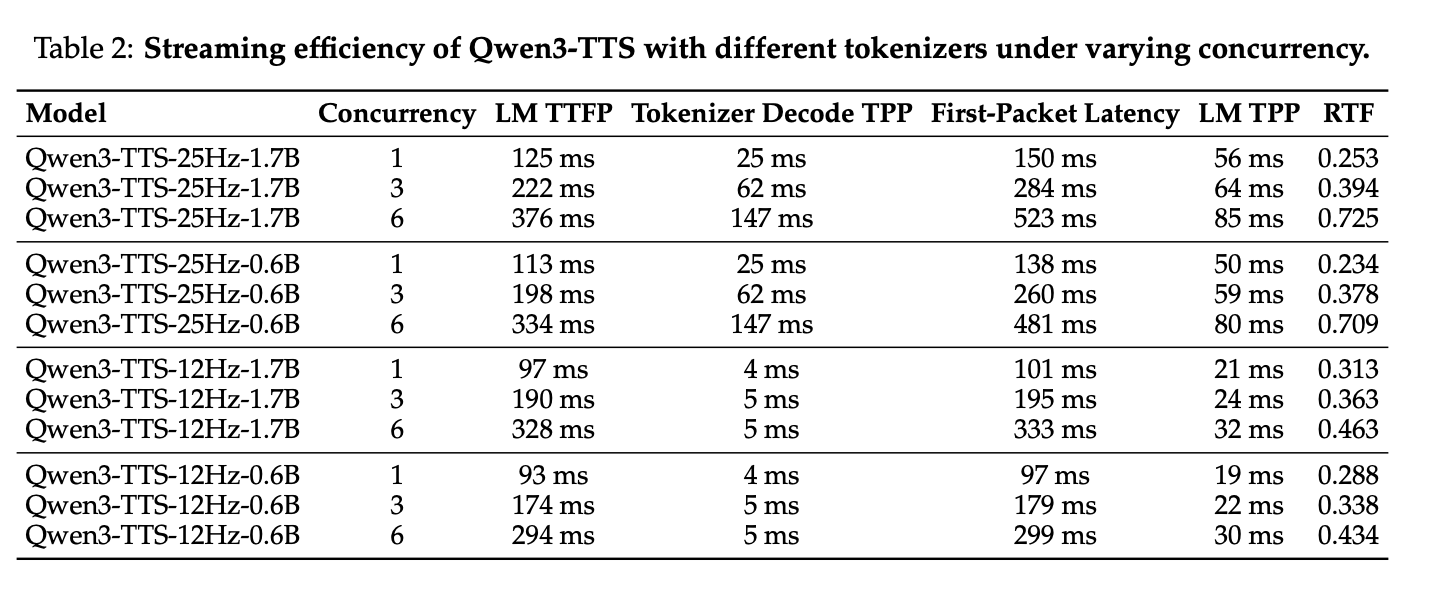
(1) 首包延迟核心影响因素
首包延迟由LLM 首 token生成时间和Tokenizer 解码时间共同决定,针对两款 Tokenizer 做针对性优化:
- 25Hz Tokenizer:按 8 个 token 分 chunk,需 LM 生成 16 个 token 后才启动解码,首包含 ~190ms 音频,稳态时每 8 个 token 生成 320ms 音频;
- 12Hz Tokenizer:纯左上下文的流式设计,1 组 token 对应 80ms 音频,为降低调度开销将 4 个 token 设为 1 个数据包(320ms 音频),解码时间仅 4ms,实现极致的首包延迟。
(2) 推理优化
基于内部 vLLM 引擎,结合 torch.compile 和 CUDA Graph 加速 Tokenizer 解码阶段,支持高并发下的低延迟流式生成。
关于流式推理和响应时间计算的明确,详见: https://www.doubao.com/thread/w962c9702f9667576
三、与其他方案的核心差异
Qwen3-TTS 并非凭空而来,而是在 CosyVoice 系列、MiniMax-Speech、Seed-TTS、MOSS-TTS 等工作的基础上发展而成。要准确理解 Qwen3-TTS 的贡献,需要将其置于同期工作的坐标系中审视:
1. 与 CosyVoice 系列的演进
CosyVoice 1/2/3 和 Qwen3-TTS 都出自阿里通义实验室,但两套方案之间有所差别:
| 维度 | CosyVoice 1/2/3 | Qwen3-TTS |
|---|---|---|
| Tokenizer | 单码本语义 token(S3 Tokenizer) | 双 Tokenizer 策略:25Hz 单码本 + 12Hz 多码本 |
| 声码器/解码器 | Flow Matching / DiT 解码声学细节 | 12.5Hz 变体仅需轻量因果 ConvNet |
| 流式首包延迟 | 受 DiT 块解码约束,延迟较高 | 12.5Hz 变体低至 97ms |
| 后训练 | 无 / 有限的后训练 | 完整的 DPO → GSPO → Speaker SFT 三阶段 |
| 可控性 | 基础语音克隆 | 克隆 + 设计 + 编辑 + 指令控制 |
关键演进:Qwen3-TTS 用更强的多码本 Tokenizer 取代了 DiT 的角色——声学细节不再由 DiT 负责恢复,而是直接编码在 RVQ 的残差码本中。这一转变从根本上简化了系统架构,消除了 LM 和声码器之间的级联瓶颈。
2. 与 MiniMax-Speech 的路线分歧
MiniMax-Speech 同样采用了「可学习说话人编码器 + LM」的架构,但两者在关键设计选择上存在分歧:
- Tokenizer 帧率:MiniMax-Speech 使用 50Hz(配合 FlowVAE 解码),Qwen3-TTS 12Hz 变体仅 12.5Hz——帧率差 4 倍,直接决定了自回归序列长度和推理效率的巨大差距。
- 声码器依赖:MiniMax-Speech 依赖 FlowVAE(本质仍是扩散类声码器),Qwen3-TTS 12Hz 仅需因果的轻量级 ConvNet,在流式友好性和部署复杂度上优势明显。
- 后训练策略:MiniMax-Speech 侧重 Speaker Encoder 的人工设计,无法天然适配 InstructTTS 类型的任务,而 Qwen3-TTS 更强调后训练对齐(DPO+GSPO),这一策略差异在可控性指标上体现显著,即:Qwen3-TTS 在 InstructTTSEval 上明显优于 MiniMax-Speech 未覆盖的场景。
3. 与 MOSS-Audio-Tokenizer 的差异
MOSS-Audio-Tokenizer(复旦邱锡鹏团队)和 Qwen-TTS-Tokenizer-12Hz 在设计理念上高度相似(12.5Hz、多码本、语义-声学解耦),但实现路径不同:
| 维度 | MOSS-Audio-Tokenizer | Qwen-TTS-Tokenizer-12Hz |
|---|---|---|
| 架构 | 纯 Transformer(1.6B 参数) | CNN 编解码器 + RVQ(基于 Mimi 架构) |
| 语义监督 | 端到端联合训练 Decoder-LLM,无外部 teacher | 蒸馏 WavLM 作为语义 teacher |
| 通用性 | 语音/音效/音乐通用 | 专注语音 |
| 可变码率 | 支持(Progressive Sequence Dropout) | 固定码率 |
| RVQ 层数 | 32 层 | 16 层 |
MOSS-Audio-Tokenizer 追求的是通用音频 Tokenizer 的扩展性极限,而 Qwen-TTS-Tokenizer-12Hz 则是为 TTS 场景深度优化的专用方案。两者代表了 Tokenizer 设计的两个正交方向:通用 vs. 专用,但在实测重建质量上(LibriSpeech test-clean),Qwen-TTS-Tokenizer-12Hz 的 PESQ/STOI/SIM 指标均显著领先,说明在语音场景下专用优化仍有明确优势。
4. 后训练:TTS 领域的「RLHF 时刻」
Qwen3-TTS 最值得关注的差异化设计之一,是其完整的后训练流程(DPO → GSPO → Speaker SFT)。这在 TTS 领域是一个重要的范式突破:
- DPO 对齐:基于人类反馈构建多语言偏好对,让模型输出对齐人类主观感知,而非单纯优化 ASR-WER 等客观指标;
- GSPO(基于规则奖励的强化学习):通过规则化奖励信号提升跨任务稳定性,避免了纯 DPO 可能导致的偏好过拟合;
- 训练中的 thinking pattern:在可控合成任务中概率性地激活 thinking 模式,让模型在执行复杂指令时”先思考再生成”,显著提升了 Voice Design 场景的遵循能力。
对比来看,CosyVoice3 也引入了后训练(DiffRO)但实际可以理解成是另一种思路:最大化多个辅助任务的奖励(比如最小化 token2text 的 WER 指标)。Qwen3-TTS 的实验结果表明,后训练对 TTS 系统质量的提升幅度甚至比模型架构的调整更重要——这对把「语音合成」视为纯粹的 LLM 大模型是一个非常积极的信号,是否还需要 DiT 这种结构值得进一步审视,对于多模态的建模也指明了更加简洁清晰的技术路线。
四、全面实验评估与 SOTA 成果
论文在语音 Tokenizer 性能、零样本合成、多语言 / 跨语言合成、可控合成、目标说话人合成、长文本合成六大维度开展实验,对比了 CosyVoice3、ElevenLabs、GPT-4o-mini-tts 等主流基线,核心成果如下:
1. Tokenizer 效果
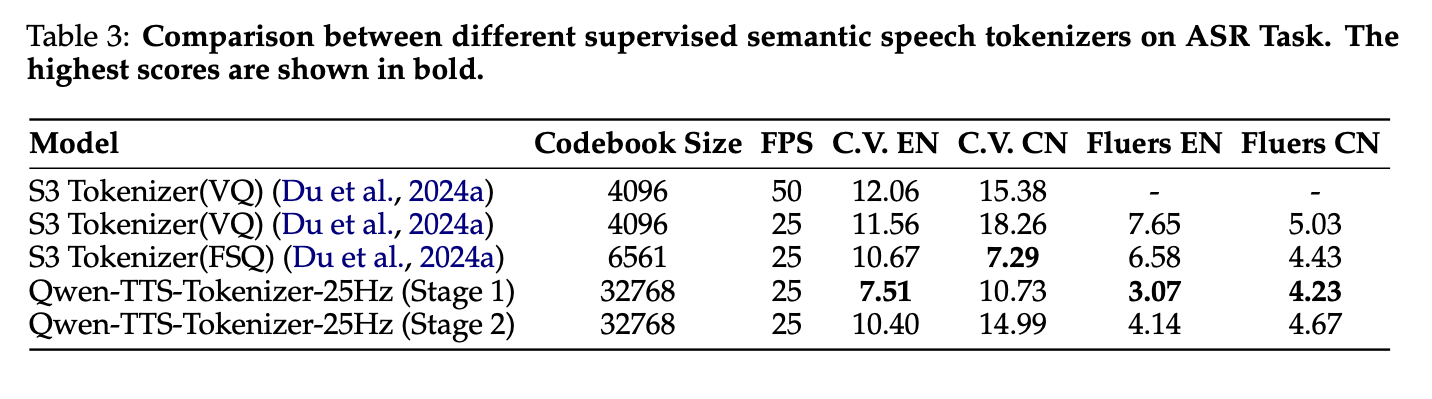
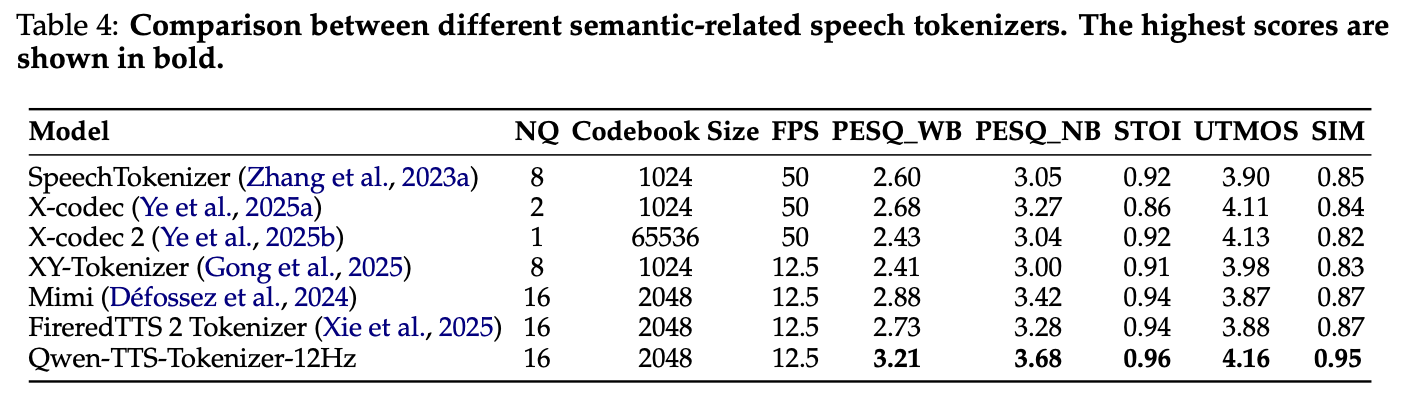
(1) 25Hz Tokenizer
- S1 阶段在 ASR 任务上实现最低 WER(Common Voice 英文 7.51、Fleurs 中文 4.23),优于 S3 Tokenizer 系列;
- S2 阶段为声学表达性牺牲少量 ASR 性能,是语义 - 声学之间的 trade-off。
(2) 12Hz Tokenizer
在 LibriSpeech 测试集上实现 SOTA 语音重建性能,PESQ_WB=3.21、STOI=0.96、UTMOS=4.16、说话人相似度 SIM=0.95,显著优于 SpeechTokenizer、Mimi 等基线。
2. zero-shot 语音克隆 (Seed-TTS 测试集)
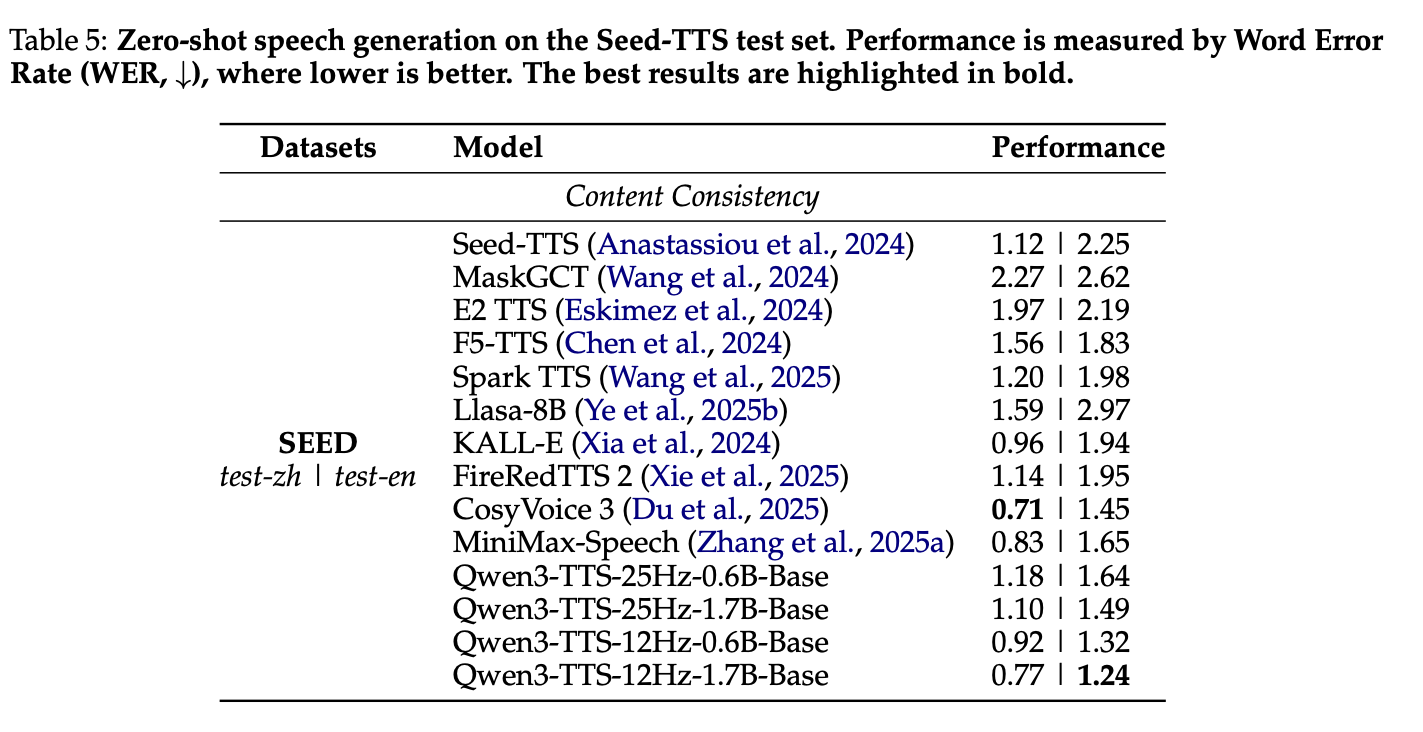
12Hz-1.7B 变体实现 SOTA,英文 WER=1.24、中文 WER=0.77,优于 CosyVoice3、FireRedTTS2 等;12Hz 变体整体优于 25Hz,因粗时间分辨率更利于自回归模型建模长程依赖。
3. 多语言合成(10 种语言)
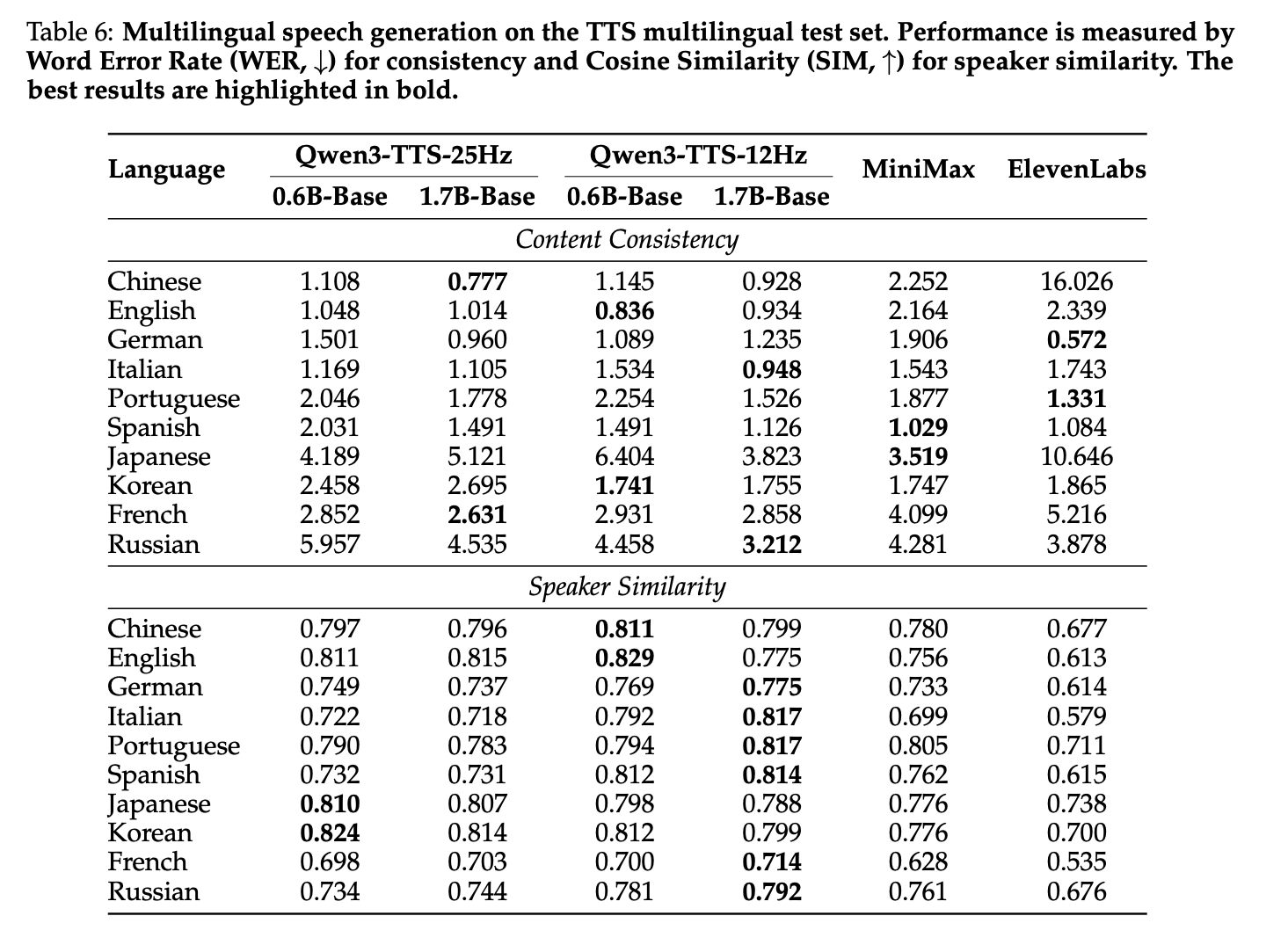
- **内容一致性 (WER)**:实现最低 WER,其余 4 种语言与 SOTA 持平;
- **说话人相似度 (余弦相似度)**:在所有 10 种语言上均优于 MiniMax-Speech 和 ElevenLabs,完美保持跨语言说话人特征。
4. 跨语言语音克隆 (CV3-Eval)
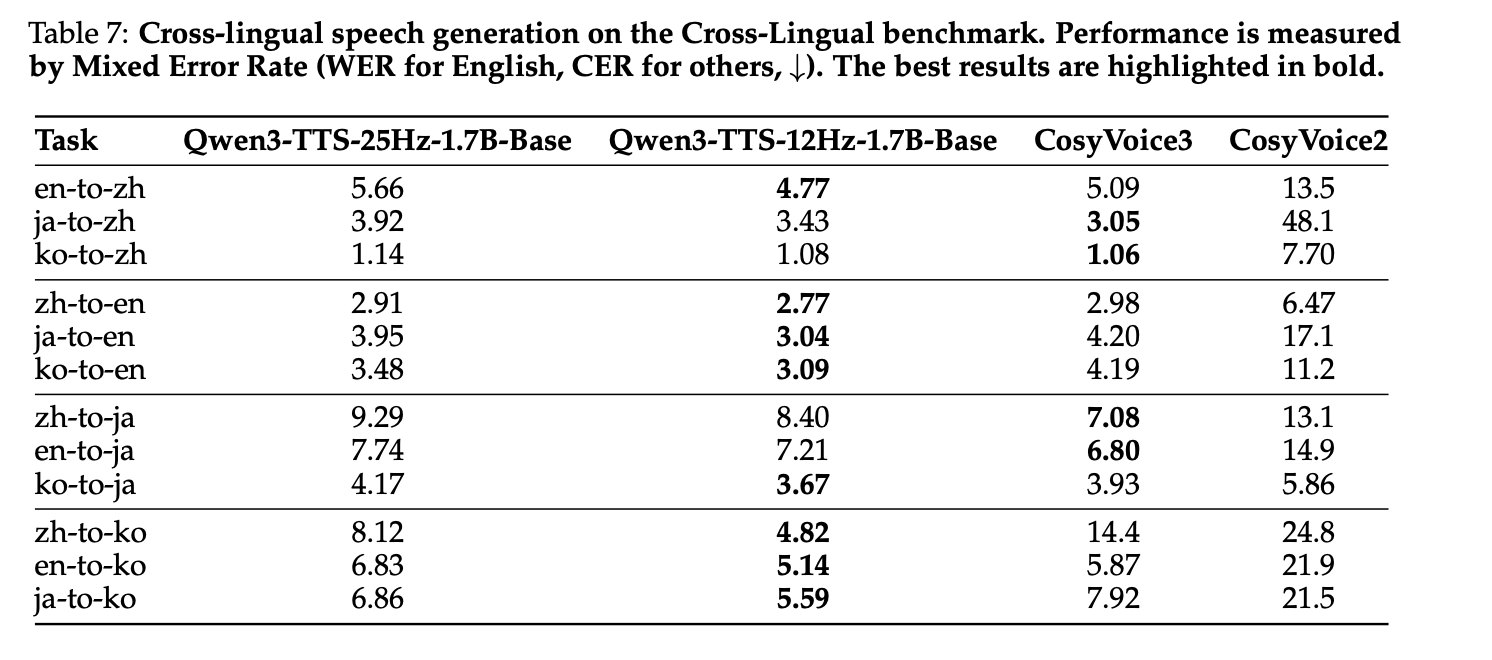
实现 SOTA,尤其是中译韩场景将错误率降低 66%(WER=4.82 vs CosyVoice3 的 14.4);中英/英中常用对均优于基线,且所有语言对保持低错误率,无基线的不稳定性问题。
5. 可控(指令)语音合成 (InstructTTSEval)
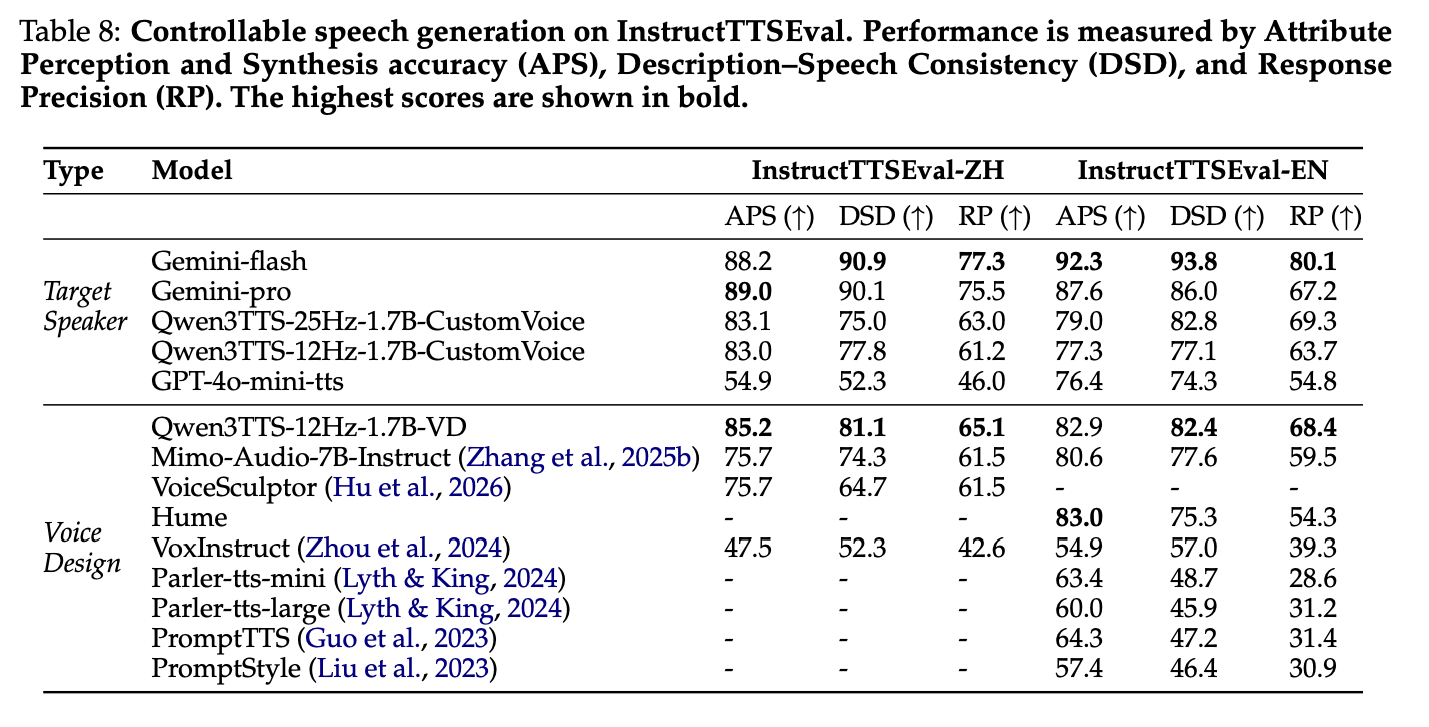
- 语音设计:12Hz-1.7B-VD 在开源模型中实现 SOTA,语音描述一致性(DSD)、响应精度(RP)优于 Hume、VoiceSculptor;
- 目标说话人编辑:中文 APS 指标比 GPT-4o-mini-tts 提升 28%,接近 Gemini 系列,能在修改风格的同时保持说话人身份。
6. 目标音色多语言合成
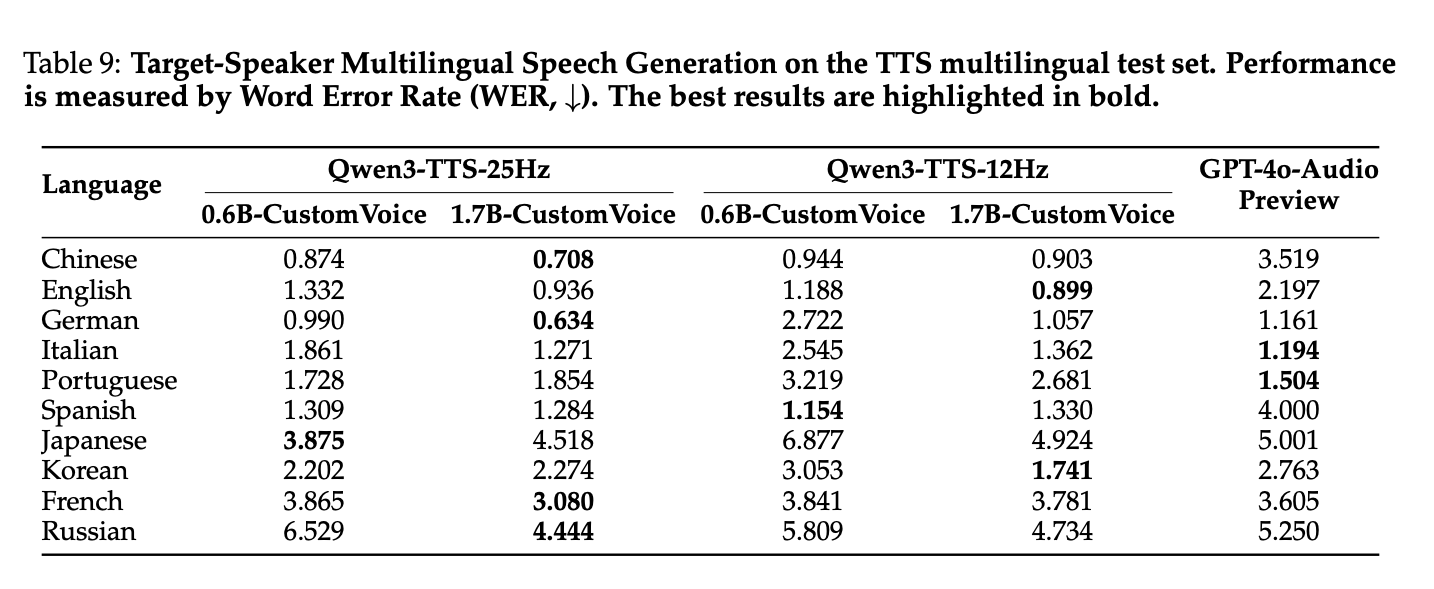 对单语说话人(Aiden Voice)微调后,在 10 种语言上均实现跨语言特征迁移,7 种语言 (中/英/德/日/韩 等) WER 低于 GPT-4o-Audio Preview,尤其在日语(3.88 vs 5.00)、韩语(1.74 vs 2.76)等难语言上优势显著。
对单语说话人(Aiden Voice)微调后,在 10 种语言上均实现跨语言特征迁移,7 种语言 (中/英/德/日/韩 等) WER 低于 GPT-4o-Audio Preview,尤其在日语(3.88 vs 5.00)、韩语(1.74 vs 2.76)等难语言上优势显著。
7. 长文本合成能力(200- 2000 词)
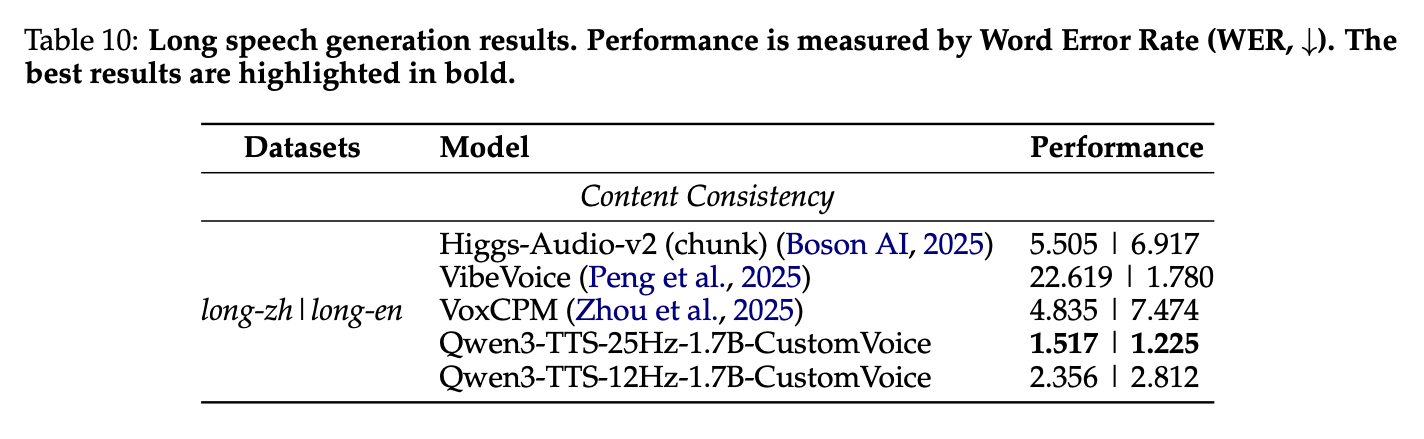
25Hz-1.7B-Custom Voice 实现 SOTA,中文 WER=1.517、英文 WER=1.225,远优于 VibeVoice(中文 WER>22)、Higgs-Audio-v2,且没有 block-wise 合成的边界伪影,韵律全程一致。
五、对 TTS 技术选型的指导意义
Qwen3-TTS 的发布,连同近期 MOSS-TTS、Fish-Audio S2 等工作的趋同,为 TTS 系统的技术选型提供了以下关键参考:
1. Tokenizer 是整个系统的天花板
Qwen3-TTS 的实验结果说明:Tokenizer 的质量直接决定了 TTS 系统的效果上限。对比 25Hz(单码本、需 DiT 解码)和 12Hz(多码本、轻量 ConvNet 解码)两个变体,12Hz 变体在零样本克隆 WER 上全面胜出(英文 1.24 vs 1.49,中文 0.77 vs 1.10),且流式延迟低一个数量级。
选型建议:在选型 TTS 方案时,Tokenizer 的设计/训练/优化/Scaling 验证,有可能需要作为第一优先级,也是目前 LLM 统一架构下「语音生成」任务有别于 NLP/CV 的最大难点。12.5Hz、16 层 RVQ 的配置已经被多项工作验证为当前的性价比最优解;更低帧率(如 6.25Hz)或更多层码本(如 32 层)能否落地还需要进一步探索和明确。
2. 纯自回归 vs. 级联:大道至简/端到端
Qwen3-TTS 12Hz 变体的成功进一步确认:当 Tokenizer 能够在离散 token 中充分编码声学细节时,DiT/Flow Matching 等非自回归声码器不再是必需品。 纯自回归架构的优势在于:
- 系统复杂度大幅降低(一个 LM + 一个轻量 ConvNet,无需 DiT);
- LLM 可以直接独立评估和调优,不再受到 DiT 的耦合约束;
- 流式友好性支持更加自然 native,不存在 DiT 块解码的 look-ahead 延迟;
- 后训练(DPO/GSPO/RL)的实施更加直接作用于 LLM,奖励直接反馈给 LLM,之前一般需要通过耦合 DiT 计算 WER/音色相似度/韵律等信号再传导给 LLM(缺点是:计算成本高&反馈奖励不够准确)
选型建议:需要根据实际场景的首包延迟、音频质量等需要来定。除非存在特殊的高保真度需求(如录音棚级音质),目前这种需求多层 RVQ 是否能够完全支撑,目前看是比较乐观的;但对于高品质场景,可能还需要进一步验证(比如 DiT 重建能力可能上限更高、AR-DiT 这种基于 WaveVAE 连续表征的方案信息损失也可能更少)。对于一般的业务场景,建议新系统优先采用纯粹的自回归 Dual-AR 路线,将复杂度预算投入到 Tokenizer 和后训练上。
3. 后训练对齐是一直被低估的增量
Qwen3-TTS 的后训练流程(DPO → GSPO → Speaker SFT)在多个维度上贡献了显著增量:在可控合成场景中,后训练后的模型在 InstructTTSEval 上指标远超未对齐的基线。这一实践表明,TTS 已经进入了和 LLM 类似的”后训练决定功能体验”阶段——预训练确定能力上限,后训练决定用户感知的质量。
选型建议:TTS 系统的训练 pipeline 应从一开始就规划后训练阶段,包括偏好数据的收集、奖励模型的设计和 RL 策略的选择。纯监督训练的 TTS 系统在产品级场景中可能是不够用的。包括 Instruct-TTS / Voice-Design,但凡是语音生成任务 + 需要偏好反馈,都应该更多关注强化学习后训练的作用。从实践中来看,强化学习也是「数据效率」最高的优化方案。
4. 流式架构的设计选择
Qwen3-TTS 提供了两种流式方案的直接对比参考:
| 方案 | 首包延迟 | 系统复杂度 | 长文本稳定性 |
|---|---|---|---|
| 25Hz 单码本 + block DiT | ~150ms | 高(需 DiT + BigVGAN) | ✅ 更优(语义 token 建模稳定性更高) |
| 12Hz 多码本 + 因果 ConvNet | ~97ms | 低(仅需轻量 ConvNet) | ✅ 良好(但长文本 WER 略高于 25Hz) |
选型建议:对于实时对话 / 语音助手等对首包延迟极度敏感的场景,12Hz 方案是明确的最优选择;对于有声书 / 播客等对质量要求高但可以容忍 100-200ms 延迟的场景,25Hz 方案可能在韵律连贯性上更有优势。
5. 数据规模的不可替代性
500 万小时的训练数据是 Qwen3-TTS 跨语言泛化能力的根基。从实验结果看,在中文、英文之外的 8 种语言上,Qwen3-TTS 与竞品的差距主要体现在数据覆盖带来的泛化优势上。
选型建议:对于需要支持多语言的 TTS 产品,数据的获取和清洗应作为核心竞争力来建设,不宜寄希望于小数据量 + 大模型的涌现能力。Qwen3-TTS 的三阶段预训练策略(通用 → 高质量 → 长上下文)也为数据使用的优先级提供了明确参考。
6. Dual-AR 双轨架构的启发
Qwen3-TTS 的 Dual-AR 设计:主干 LM 预测时序的语义码本、MTP 模块预测层数深度上的残差码本——本质上是对 Multi-Token Prediction 在 TTS 场景下的一种工程化实现。这种设计兼顾了:
- 生成效率:每步 LM forward 只需预测一个语义 token,MTP 模块以极低成本补全声学细节;
- 质量上限:残差码本由专用的 MTP 模块处理,不增加主干 LM 的建模负担。
选型建议:对于使用 RVQ 多码本的 TTS 系统,Dual-AR / MTP 的分层预测策略值得作为默认架构选择。这一点在 Moshi/CSM/FireRedTTS2 等语音对话&生成方向上也是使用最多的技术方案之一。
六、结论与未来方向
1. 核心贡献
- 基于 Qwen3 LM 构建的双轨自回归(Dual-AR)架构,实现了 LLM 与 TTS 的自然兼容,支持高并发低延迟推理;
- 分阶段训练 + 微调/后训练策略,解决了自回归模型长文本合成的稳定性问题,实现超10分钟流畅合成;
- 统一了零样本克隆、跨语言迁移、精细化指令控制、音色设计等多任务于单一自回归架构。
2. 未来方向
- 扩展音频生成能力至更多场景(如歌唱、对话);
- 将多语言支持从 10 种扩展至更多语种;
- 探索更细粒度的语音风格控制;
- 持续优化模型效率,进一步降低延迟与参数量。
七、开源信息
Qwen3-TTS 12.5Hz 的模型、tokenizer 均已开源,可在 Hugging Face、ModelScope、GitHub 获取:
- Hugging Face: https://huggingface.co/collections/Qwen/qwen3-tts
- ModelScope: https://modelscope.cn/collections/Qwen/Qwen3-TTS
- GitHub: https://github.com/QwenLM/Qwen3-TTS
- 本文标题:语音合成 | Qwen3-TTS:当 TTS 重新回到 LLM+RVQ
- 创建时间:2026-03-10
- 本文链接:2026/2026-03-04-qwen3-tts/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!