最近几年的 TTS 模型,多数还依赖类似 text→semantic & semantic→acoustic/mel 的级联方案,存在模块繁多、误差累积的问题。小米 Daniel Povey 团队最新提出的 OmniVoice,基于 扩散语言模型(Diffusion Language Model) 这类单阶段离散 NAR 架构,重新将离散 Diffusion 拉回到 TTS 的赛场上,直接将文本映射到 multi-codebook 多层声学 token 上。近期测试了下,模型整体效果还不错,而且支持 600+ 语言的零样本语音合成,是目前覆盖语言范围最广的 TTS 模型。
- 论文:OmniVoice: Towards Omnilingual Zero-Shot Text-to-Speech with Diffusion Language Models
- 发表单位:小米(Daniel Povey 团队)
- arXiv: https://arxiv.org/abs/2604.00688
- 代码: https://github.com/k2-fsa/OmniVoice
- 语音样本: https://zhu-han.github.io/omnivoice
- 在线 Demo: https://huggingface.co/spaces/k2-fsa/OmniVoice
本文核心贡献(TL;DR)
单阶段离散 NAR 架构:抛弃传统 text→semantic→acoustic 的多阶段管线,基于离散扩散(Discrete Diffusion)目标及双向 Transformer 结构,直接从文本映射到多 codebook 声学 token,消除误差累积问题,本质上是将扩散语言模型的思路迁移至了语音生成领域。
Full-Codebook Random Masking:传统的 multi-codebook 方案(SoundStorm / MaskGCT)主要采用”逐层”mask 策略,每次仅对单个 codebook 层计算 loss,假设性较强且训练样本的使用效率较低。OmniVoice 改为对所有 codebook 的所有位置独立进行采样 Bernoulli mask,平均 50% token 参与 loss 计算,能够显著加速收敛、提升生成质量。
LLM 权重初始化:首次在 NAR 的 TTS 模型中利用预训练 AR LLM(Qwen3-0.6B)的权重初始化骨干网络,将 LLM 的基座能力迁移至双向模型,提升单阶段 NAR 模型的发音准确性(WER 从 ~2.5 降至 1.57)。
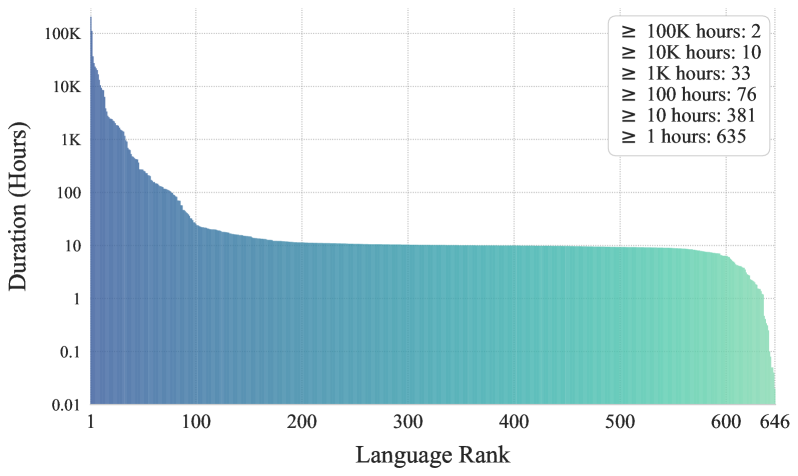
600+ 语言覆盖:基于 50 个开源数据集构建 581k 小时多语言训练数据,配合语言级重采样策略,实现目前最广泛的零样本 TTS 语言支持。
多维可控性:OmniVoice 模型也在这套架构下,支持了 prompt 去噪、基于说话人属性的音色设计、副语言控制和拼音/音素级语音纠正等多种功能。
关键技术细节
OmniVoice 模型结构
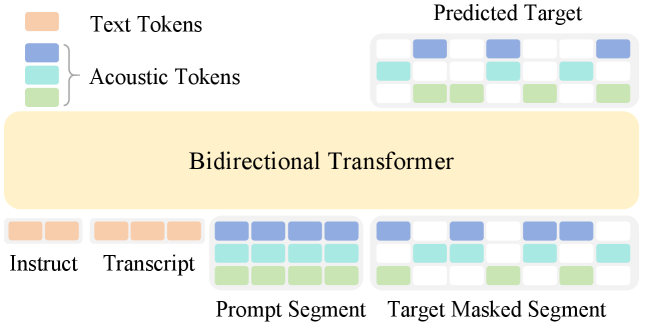
OmniVoice 整体架构:
- 输入:文本 token 序列
(指令 + 文本转录)+ 声学 token 矩阵 ( 为时间步, 为 codebook 数量,使用 Higgs-Audio 的 Tokenizer 提取 8 个 codebook) - prompt 和 target 设计:沿时间维度分为 prompt 段(前缀声学上下文)和 target masked 段(部分位置被随机替换为
token) - Embedding:文本通过文本嵌入层,声学 token 通过各 codebook 专用嵌入层,同一时间步的 C 个 codebook embedding 求和合并
- Backbone:双向 Transformer(结构与标准 AR LLM 相同,但去除因果 mask),使用 Qwen3-0.6B 进行权重初始化
- 输出:
个独立的 codebook 预测头,每个头输出对应 codebook 词表上的概率分布
训练损失仅在被 mask 的声学 token 位置计算交叉熵:
全码本随机 mask
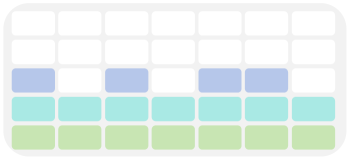

[左图] per-layer mask(每次选一个单层随机 mask) v.s. [右图] full-codebook (全部层随机 mask)
这是本文的核心训练创新:
| 策略 | 做法 |
|---|---|
| SoundStorm-style | 从均匀分布采样单个 codebook 层,cosine 函数决定 mask ratio |
| MaskGCT-style | 线性分布采样层(低层优先),mask ratio 同上 |
| Full-codebook random | 每个 |
关键结果:全 codebook 随机 mask 使得每个训练 step 有约 50% 的所有 token 参与梯度更新,比逐层策略多
消融实验(LibriSpeech-PC test-clean):
| 序号 | Masking 策略 | SIM-o↑ | WER↓ | UTMOS↑ |
|---|---|---|---|---|
| 1 | SoundStorm-style mask(逐层均匀采样 + cosine ratio) | 0.661 | 3.00 | 4.12 |
| 2 | MaskGCT-style mask(逐层线性采样,低层优先) | 0.660 | 2.04 | 4.17 |
| 3 | Full-codebook random mask | 0.697 | 1.57 | 4.23 |
| 4 | └─ 仅在单个 codebook 上计算 loss | 0.648 | 2.85 | 4.22 |
最后一行消融实验说明:即使采用全 codebook 随机 mask(输入侧),若预测任务的 loss 仍只在单个 codebook 上计算,性能也会显著下降(WER 1.57→2.85,SIM-o 0.697→0.648),从而验证了稠密 loss 计算(所有被 mask 位置均参与梯度更新)是该策略有效的关键。
LLM 初始化
使用 Qwen3-0.6B 的预训练权重初始化双向 Transformer 骨干。尽管 LLM 原本用因果 mask 训练,实验表明其预训练知识可以有效迁移到双向架构。
事实上,在 NLP 领域,已经有很多类似的工作,验证了 Decoder-Only Transformer 这种 Causal Mask 训练的模型能够有效用于双向 Transformer 的权重初始化,最典型的工作是 LLM2Vec。
这是 首个 成功在 NAR TTS 中利用 LLM 初始化获得显著可懂度提升的工作。消融实验显示,即使在大范围内调整学习率(1e-4 到 1e-3),随机初始化的模型 WER 仍始终高于 LLM 初始化版本:
| 初始化方式 | Learning Rate | WER↓ (Libri) | WER↓ (Seed-en) | WER↓ (Seed-zh) |
|---|---|---|---|---|
| LLM init | 1e-4 | 1.57 | 1.72 | 0.89 |
| Random init | 1e-4 | 2.79 | 2.34 | 1.11 |
| Random init | 2e-4 | 2.52 | 2.43 | 1.01 |
| Random init | 5e-4 | 2.56 | 2.07 | 1.01 |
| Random init | 1e-3 | 2.72 | 2.29 | 1.02 |
小讨论:Decoder-Only 的 LLM 用于双向 Transformer 初始化为什么有效?
- 底层的架构一致性(差异仅在 Mask)
Decoder-only 模型和双向 Encoder 模型在核心架构(Transformer)上几乎完全一样。唯一的本质区别在于 注意力掩码(Attention Mask),这里只是运算层面的变化,模型结构是没有改变的。Decoder 在计算 Self-Attention 时,增加了一个下三角的“因果掩码(Causal Mask)”,强制模型不能看未来的 Token 信息;而双向模型则是左右侧信息都能看到。实际上,如果在代码中直接把这个 Causal Mask 去掉(将is_causal=False),Decoder 立刻相当于一个双向模型。 - 极丰富的预训练知识储备
像 LLaMA、GPT、Qwen 这些 Decoder 模型,使用了数以万亿计的 Token 进行了极其充分的预训练,模型的参数比如投影矩阵()和前馈神经网络(FFN)层已经学到了复杂深刻的语法、语义结构和逻辑推理能力。 - 模型“微调(Adaptation)”效率高
实际使用阶段,刚去掉 Causal Mask 时,模型一开始可能会有些“懵”,因为从未在训练中见过“未来”的词汇参与当前词汇的表征计算。但由于基模的语义能力比较强,只需要用极少量的数据进行掩码语言建模(如 BERT 的 MLM 任务)进行训练,模型就能迅速学会如何融合右侧的上下文,相比从头随机初始化(Random Initialization)来训练一个双向模型要更容易并且效果好很多。
多语言扩展
- 数据规模:聚合 50 个开源数据集,总计 581k 小时、600+ 语言
- 数据清洗:使用语音修复模型增强音频 + 规则过滤无效的转录音频
- 语言重采样:对低资源语言上采样,重复因子
, 是控制各语种数据量均衡程度的平滑参数, 能保持高资源语言性能的同时确保低资源语言曝光。 - 文本处理:直接使用 LLM 的 subword tokenizer,避免 G2P 和语言特定文本归一化
推理策略
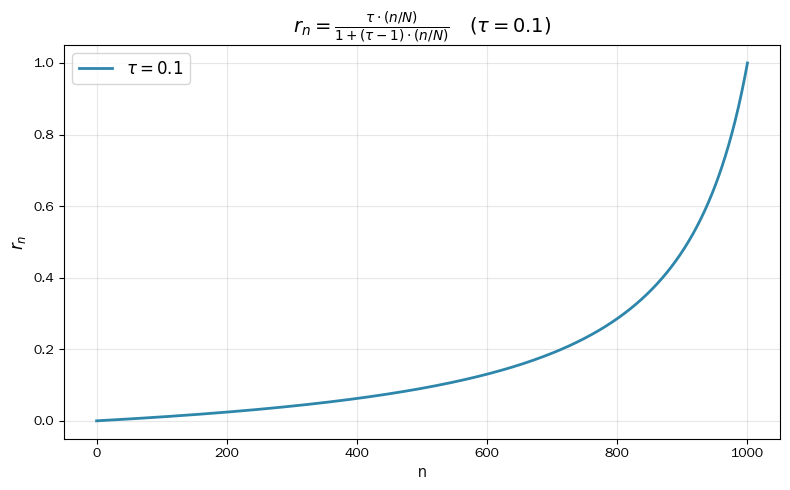
采用
- 调度函数:定义累积 unmask 比例
(即前 步结束后已解码得到的 token 占比),其中 , :
第步新增解码的 token 比例为 。 的曲线呈先慢后快的形态(如下图所示),前期每步只解码确定下来少量 token(相当于初期要更谨慎做决策),后续已经解码的信息更多之后,保留的 token 更多(利用已有上下文加速填充)。
- 解码位置选择:基于 log-softmax 置信度进行采样(温度
),引入一些随机性避免局部最优 - Token 生成:选定位置后选择 argmax 概率最大的 token 作为生成结果
- 层优先级:虽然训练时 mask 对于所有层一视同仁,但推理阶段论文还是需要“低层优先”,对置信度施加“层惩罚”(层越高惩罚越大),相当于鼓励先解码低层 codebook
- CFG:在 log-softmax 空间使用 CFG(classifier-free guidance)
推理速度(H20 GPU,RTF):
- 16 步 / batch=1:0.0319(优于 ZipVoice 的 0.0557)
- 32 步 / batch=8:0.0414
不同推理步数对生成质量的影响:
| Steps | Libri SIM-o↑ | Libri WER↓ | Libri UTMOS↑ | Seed-EN SIM-o↑ | Seed-EN WER↓ | Seed-EN UTMOS↑ | Seed-ZH SIM-o↑ | Seed-ZH CER↓ | Seed-ZH UTMOS↑ |
|---|---|---|---|---|---|---|---|---|---|
| 64 | 0.729 | 1.28 | 4.30 | 0.742 | 1.60 | 3.92 | 0.777 | 0.81 | 3.13 |
| 32 | 0.729 | 1.30 | 4.28 | 0.741 | 1.53 | 3.91 | 0.777 | 0.84 | 3.11 |
| 16 | 0.728 | 1.50 | 4.23 | 0.735 | 1.72 | 3.92 | 0.773 | 0.99 | 3.00 |
| 8 | 0.713 | 2.02 | 4.02 | 0.716 | 1.94 | 3.59 | 0.756 | 1.58 | 2.72 |
- 32 步与 64 步的差异极小(Libri WER 1.30 vs 1.28),64 步几乎没有额外收益
- 16→32 步有明显质量提升(Seed-ZH CER 从 0.99 降至 0.84),32 步是性价比最高的配置
- 8 步质量显著下降(WER/CER 接近翻倍)
关键实验
中英文评测
LibriSpeech-PC test-clean(客观):
| 模型 | 参数量 | 数据量 | SIM-o↑ | WER↓ | UTMOS↑ |
|---|---|---|---|---|---|
| Ground-truth | - | - | 0.690 | 1.87 | 4.10 |
| IndexTTS2 (AR) | 1.7B | 55K Multi. | 0.700 | 2.35 | 4.06 |
| CosyVoice3 (AR) | 1.1B | 1000K Multi. | 0.694 | 1.59 | 4.28 |
| VoxCPM (AR) | 0.7B | 1800K Multi. | 0.717 | 1.74 | 4.18 |
| Qwen3-TTS (AR) | 1.1B | 5000K Multi. | 0.704 | 1.60 | 4.41 |
| F5-TTS (NAR) | 0.4B | 100K Emilia | 0.655 | 1.89 | 3.89 |
| ZipVoice (NAR) | 0.1B | 100K Emilia | 0.668 | 1.64 | 3.98 |
| MaskGCT (NAR) | 2.2B | 100K Emilia | 0.691 | 2.26 | 3.91 |
| OmniVoice-Emilia | 0.8B | 100K Emilia | 0.697 | 1.57 | 4.23 |
| OmniVoice | 0.8B | 581K Multi. | 0.729 | 1.30 | 4.28 |
- 同数据(Emilia 100K)条件下,OmniVoice 全面超越所有 NAR 基线
- 多语言版本 OmniVoice 在 SIM-o(0.729)和 WER(1.30)上超越所有 AR/NAR 模型
Seed-TTS test-en / test-zh(客观):
| 模型 | Seed-EN SIM-o↑ | Seed-EN WER↓ | Seed-EN UTMOS↑ | Seed-ZH SIM-o↑ | Seed-ZH CER↓ | Seed-ZH UTMOS↑ |
|---|---|---|---|---|---|---|
| Ground-truth | 0.734 | 2.14 | 3.52 | 0.755 | 1.25 | 2.78 |
| IndexTTS2 (AR) | 0.706 | 2.33 | 3.65 | 0.764 | 1.05 | 3.00 |
| CosyVoice3 (AR) | 0.696 | 2.17 | 3.96 | 0.778 | 1.14 | 3.32 |
| VoxCPM (AR) | 0.731 | 1.92 | 3.77 | 0.772 | 0.99 | 2.94 |
| Qwen3-TTS (AR) | 0.708 | 1.54 | 4.16 | 0.766 | 1.15 | 3.46 |
| F5-TTS (NAR) | 0.664 | 1.85 | 3.72 | 0.750 | 1.53 | 2.93 |
| ZipVoice (NAR) | 0.697 | 1.70 | 3.82 | 0.751 | 1.40 | 3.15 |
| MaskGCT (NAR) | 0.713 | 2.88 | 3.55 | 0.773 | 2.40 | 2.63 |
| OmniVoice-Emilia | 0.717 | 1.72 | 3.88 | 0.765 | 0.89 | 3.05 |
| OmniVoice | 0.741 | 1.60 | 3.91 | 0.777 | 0.84 | 3.11 |
- OmniVoice 在 Seed-TTS 中文测试集上 CER 低至 0.84%,断层领先所有模型(第二名 VoxCPM 为 0.99%)
- 英文 SIM-o 达到 0.741,超越真实语音基线(0.734),说明音色克隆能力极强
- 中英双语均衡无偏科,统一架构能适配不同语系的发音规律
主观评测(Seed-TTS 测试集):
| 模型 | CMOS↑ | SMOS↑ |
|---|---|---|
| Ground-truth | 0.00 | 3.02±0.20 |
| Qwen3-TTS | +0.40±0.16 | 3.65±0.18 |
| ZipVoice | -0.30±0.16 | 3.35±0.19 |
| MaskGCT | -0.38±0.17 | 3.20±0.18 |
| OmniVoice-Emilia | +0.42±0.15 | 3.58±0.18 |
| OmniVoice | +0.44±0.16 | 3.80±0.17 |
- OmniVoice 在主观质量和说话人相似度上均达到最优
- 传统 NAR 模型(ZipVoice、MaskGCT)CMOS 均为负,而 OmniVoice 实现正向评分,架构创新有效解决了 NAR 模型音质生硬的问题
- OmniVoice-Emilia 同数据条件下也达到了接近最优的主观表现(CMOS +0.42)
多语言评测
24 语言(MiniMax-Multilingual-24,Table 3):
- OmniVoice 平均 WER 2.85 vs MiniMax 3.77 vs ElevenLabs 10.95
- OmniVoice 平均 SIM-o 0.830 vs MiniMax 0.766 vs ElevenLabs 0.655
- 完全基于开源数据训练,性能超越领先商业系统
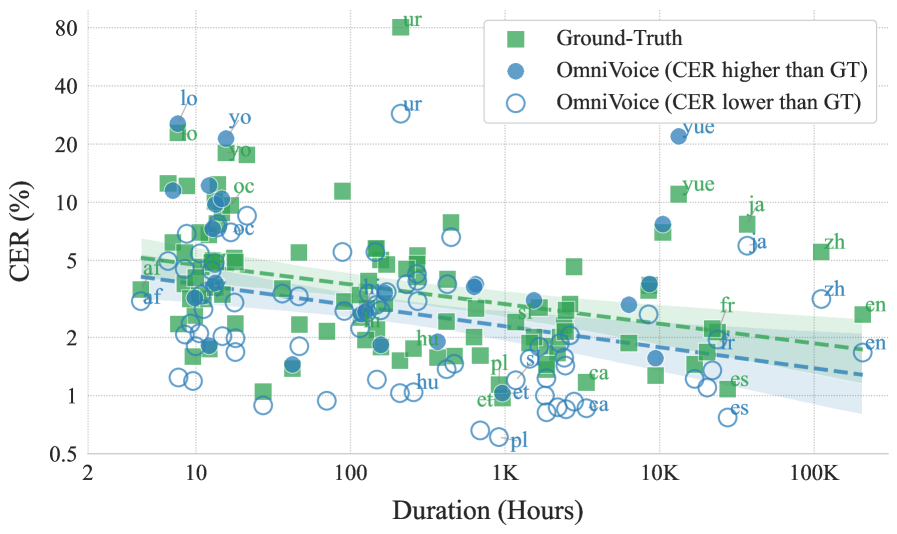
102 语言(FLEURS-Multilingual-102,Table 4):
- 平均 CER 4.00%,与 ground truth 的 5.11% 相当
- 82 个语言 CER ≤ 5%(ground truth 为 75 个)
- 即使训练数据不足 10 小时的语言也能保持高可懂度
模型多维可控性
OmniVoice 在基础零样本 TTS 之上,通过指令设计和数据增强实现了三个维度的可控性:
1. 声学控制:Prompt 去噪
实际场景中,用户提供的参考音频往往含有环境噪声或混响。为了让模型能从退化的 prompt 中提取干净的说话人特征:
- 训练策略:对训练数据的一部分 prompt 段注入合成噪声和混响,但是 target 音频仍然是干净的,这样进行数据增强
- 指令机制:这些增强样本配对特殊指令 token
<|denoise|>,模型学会将说话人内在音色与声学环境解耦 - 具体效果:启用去噪后 UTMOS 从 4.23 提升至 4.32(生成语音更干净);但 SIM-o 从 0.697 降至 0.668,因为生成语音比噪声 prompt 更干净,SIM-o 无法刨掉噪声带来的干扰(这里实际应该和不带噪的 prompt 也计算音色相似度更有代表性一些)
2. 身份控制:基于说话人属性的音色设计
在没有参考音频的场景下,OmniVoice 支持通过说话人属性描述来生成定制化音色:
- 属性维度:性别、年龄、音高、口音/方言等
- 实现方式:将说话人属性编码到训练指令序列中,模型学习属性→音色的映射
- 应用场景:虚拟角色配音、无需录音即可定制音色等场景
3. 语言控制:副语言与语音纠正
- 副语言控制:在包含情感线索的数据集上训练,使模型支持笑声等副语言表达,弥合基本可懂性与类人表现力之间的差距
- 拼音/音素级语音纠正:针对中文多音字、英文专业术语等发音边缘情况,采用混合文本输入格式。训练时随机将字符替换为对应的语音转写(中文→拼音,英文→CMU 音素),推理时用户可通过显式标注拼音/音素来确定性地控制发音,实现高精度的语音覆盖
| 维度 | 能力 | 核心机制 | 关键效果 |
|---|---|---|---|
| 声学控制 | Prompt 去噪 | 噪声注入增强 + `< | denoise |
| 身份控制 | 属性音色设计 | 属性编码到指令序列 | 无需参考音频即可定制音色 |
| 语言控制 | 副语言 + 发音纠正 | 情感数据训练 + 拼音/音素随机替换 | 支持笑声等表达 + 确定性发音控制 |
OmniVoice 优缺点
优势:
- 架构极简但强效:单阶段直接 text→acoustic token,避免了 MaskGCT 等两阶段系统的误差累积和信息瓶颈,同时在 0.8B 参数量下达到 SOTA 性能
- 训练效率突破:Full-codebook random masking 使每步有效监督信号提升 8 倍(C=8),大幅加速收敛。多语言版本 8 卡 H800 仅需 9.66 天完成 2M 步训练
- 语言覆盖空前:600+ 语言的零样本 TTS 是一个重要里程碑,且完全基于开源数据构建,可复现性强
- NAR 模型 LLM 初始化的首次成功:证明了 AR LLM 的语言知识可以迁移到双向 NAR 架构,打开了 NAR TTS 利用大模型预训练的新路径
- 推理高效:NAR 并行解码,16 步 RTF 0.032,显著优于同类方法
局限性:
- 离散 NAR 推理加速困难:不像连续空间 NAR 模型可以通过 flow distillation 大幅减少推理步数,离散空间 NAR 目前缺乏类似的加速手段,32 步仍然是较多的
- Prompt 去噪的 trade-off:启用 prompt 去噪后 SIM-o 从 0.697 降至 0.668(Table 7),说明去噪与音色保真之间存在矛盾
- UTMOS 与 AR SOTA 有差距:与 Qwen3-TTS(5000K 数据、UTMOS 4.41)相比,OmniVoice 的自然度仍有差距(4.28),NAR 在韵律多样性方面可能仍不如 AR 模型
- 低资源语言质量存疑:虽然 CER 数字好看,但部分低资源语言的 ASR 评测模型本身能力有限(如论文承认粤语 WER 高是因为 Whisper 的问题),实际合成质量难以完全通过 CER 衡量
- 数据质量限制:完全依赖开源数据,论文自己承认标注质量不一致、声学质量参差不齐,与使用内部高质量数据训练的商业系统相比仍有提升空间
- 文本归一化缺失:未针对复杂数字序列、数学表达式等做优化,依赖外部 TN 前端
重要 Insights
扩散语言模型重回语音合成:OmniVoice 成功将 Diffusion LLM(离散 Diffusion)等文本领域的离散扩散模型思路迁移到语音领域,和之前 SoundStorm/MaskGCT/NaturalSpeech3 等系列论文技术架构一致,但直接从文本通过离散 Diffusion 预测 RVQ token,验证了这一范式在多 codebook 声学 token 预测上的可行性和有效性。
NAR + LLM 初始化的新范式:此前 LLM 初始化仅在 AR TTS(CosyVoice2 等)中验证有效,OmniVoice 首次证明 NAR 架构也能受益于 LLM 权重,且因果 Attention → 双向 Attention 的知识迁移是可行的。意味着 NAR TTS 也可以站在预训练 LLM 的肩膀上,享受语言模型预训练的成果。
全 codebook 随机 mask 是更优的训练范式:相比 SoundStorm/MaskGCT 的逐层 mask,全随机 mask 在概念上更简单但效果更好。这个发现对所有基于 multi-codebook 的离散 token 预测任务都有参考价值。
大规模多语言 TTS 的可行路径:完全基于开源数据就能构建 600+ 语言的高质量 TTS 系统,其中语言重采样策略(
)为处理极端数据不平衡提供了实用参考。 落地层面:多维可控性(prompt 去噪、属性音色设计、拼音纠错)使模型更贴近实际生产需求。但离散 NAR 推理加速是需要后续突破的关键瓶颈。另外,如何确定待合成语音的时间长度?以及如何在离散 Diffusion 基础上解决流式合成?都还是需要解决的重要问题。
延伸问题与浅析
延伸讨论一:离散 Diffusion 的总长度预测
OmniVoice 作为基于离散 Diffusion 的 NAR 模型,在推理时有一个不可忽视的问题就是需要预先确定目标语音的时间长度。这引出了离散 Diffusion LLM 的一个核心问题:Canvas Initialization——如何确定待生成序列的长度?
与 AR 模型可以通过生成 EOS token 预测终止不同,NAR Diffusion LLM 需要在生成开始前就确定输出长度。先看一下现有模型是怎么做的:
现有做法
目前离散 Diffusion 模型中常见的长度确定方案,各有明显局限:
| 方案 | 做法 | 代表工作 | 局限性 |
|---|---|---|---|
| 外部时长预测器 | 训练一个独立的小模型,根据文本和 prompt 预测目标帧数 | MaskGCT / SoundStorm | 引入额外模块,增加系统复杂度;时长预测误差会直接影响合成质量 |
| 固定比例估算 | 按文本 token 数乘以固定系数粗略估算 | LLaDA-TTS / OmniVoice | 忽略了语速变化、停顿、语言差异等因素,灵活性差 |
| 用户指定 | 由用户或上层应用直接传入目标时长 | — | 使用门槛高,不适合端到端的自动化生成 |
OmniVoice 的具体做法
详见:https://github.com/k2-fsa/OmniVoice/blob/master/omnivoice/utils/duration.py,实现了一个基于规则的 RuleDurationEstimator,纯规则驱动,思路是:
① 字符音素权重表(Phonetic Weights):为不同书写系统的字符赋予不同的”发音时长权重”,基准为 1 个拉丁字母 ≈ 40-50ms:
| 类别 | 权重 | 示例 |
|---|---|---|
| CJK 表意文字 | 3.0 | 中文汉字、日文汉字 |
| 韩文 Hangul | 2.5 | 한글 |
| 日文假名 | 2.2 | ひらがな / カタカナ |
| 印度系文字(Abugida) | 1.8 | 印地语、孟加拉语、泰米尔语等 |
| 阿拉伯/希伯来(Abjad) | 1.5 | العربية |
| 拉丁/西里尔/希腊字母 | 1.0 | 基准 |
| 数字 | 3.5 | 需要展开读出 |
| 标点 / 空格 / 变音符号 | 0.5 / 0.2 / 0.0 | 停顿 / 词界 / 不占时长 |
② Unicode 区间快速映射:通过预排序的 Unicode 码点区间表 + 二分查找(bisect),快速判断每个字符属于哪种书写系统,覆盖 600+ 种语言。
③ 时长估计公式:先用参考文本和参考时长算出”语速因子”(总权重 / 时长),再用目标文本的总权重除以该语速因子得到预估时长。
这个设计比较轻量实用,在 OmniVoice.generate() 中当用户没有显式指定输出音频时长时,用该估计器根据输入文本自动推算应该生成多长的音频。
改进方向
Canvas Initialization 在 NLP 领域的离散 Diffusion LM 中有不少工作,目前尚无完美的解决方案,但是已经探索了一些更”原生”的长度处理策略,有些可以在语音生成场景中借鉴:
方案一:固定最大长度 + EOS 自终止
LLaDA 提出了一种简洁的做法:始终分配一个固定的最大长度作为 canvas,让模型在并行去噪过程中自行学会生成 EOS token,EOS 之后的位置自然成为 padding 被丢弃。这个方案的优点是完全不需要外部长度预测,模型端到端学习”何时停止”;缺点是计算资源浪费严重,因为无论实际输出多短,都需要在最大长度上做完整前向计算。对于语音合成而言,声学 token 序列通常很长(几百到几千帧),尤其是前向推理次数需要 16 甚至 32 次,所以这种固定最大长度方案带来的冗余计算开销不可忽视。
方案二:模型联合预测长度
Difformer 提出了更高效的方案:在主干 Transformer 对条件输入进行编码之后,接入一个轻量的线性层,联合训练来直接预测目标序列的长度,再按照预测长度动态初始化 canvas。这种做法避免了独立时长预测器带来的模块割裂问题,长度预测与生成模型共享表征,理论上能学到更准确的长度估计。最新的 Diffusion Language Models Are Natively Length-Aware 延续了类似思想,也进一步验证了离散 Diffusion 模型具备”原生”的长度感知能力。
延伸讨论二:离散 Diffusion 流式生成能力
OmniVoice 实际是一个 NAR 的非流式模型,在推理时需要一次性生成完整的目标序列,先初始化全 mask 的 canvas,再经过 16-32 步迭代去噪才能输出最终结果。这意味着用户必须等待整个序列生成完毕后才能听到第一帧语音,首包延迟(first-packet latency)过高,这对于实时对话、语音助手等交互场景是不可接受的。
相比之下,AR 模型天然具备流式能力,每生成一个 token 就可以立即送入声码器输出。如何让离散 Diffusion 也具备类似的增量式/流式生成能力,是该范式在语音生成领域走向实用化的关键瓶颈。
思路一:分块自回归 + 块内并行扩散
最直接的思路是将全序列离散 Diffusion 分解为块级自回归 + 块内并行扩散的混合范式:
Block Diffusion 提出了这一方向的奠基性工作:将 token 序列划分为固定大小的 block,block 之间按自回归顺序依次生成,而每个 block 内部通过离散扩散并行去噪。通过调节 block size,可以在纯 AR(block size=1)和纯 Diffusion(block size=全序列)之间平滑过渡。这一框架类似 AR,天然支持:
- 流式输出:每完成一个 block 的去噪即可输出对应音频片段
- KV Cache:已完成的 block 可以缓存 KV,后续 block 生成时直接复用
- 任意长度生成:不需要预先确定全序列长度,逐 block 生成直到满足终止条件
思路二:异步噪声调度
另一个思路不依赖显式的 block 划分,而是让序列中不同位置处于不同的噪声水平:
Diffusion Forcing 提出了这一关键范式:训练时为每个 token 独立采样噪声水平,使模型学会在”左侧几乎干净、右侧高度噪声”的混合状态下工作。推理时,可以实现滚动式生成(rolling generation),左侧较早生成的 token 已经充分去噪并可输出,同时右侧新的 token 正在逐步去噪,整个过程像一个”移动的去噪窗口”不断向前推进。
该思路在视频生成领域已验证有效(如 AR-Diffusion 对视频帧施加非递减噪声约束),在离散文本/语音场景中同样有巨大的探索空间。
思路三:流式 Flow Matching
StreamFlow(NeurIPS 2025)从另一个角度切入:在连续空间的 Flow Matching 框架下实现流式音频生成。核心做法是沿时间轴引入因果噪声训练框架(causal noising),每个 stream 同时预测多个时间步的向量场,从而实现逐 token 级别的流式推理,按照 StreamFlow 论文所述,该模型已成功集成到 Moshi 的全双工流式语音对话系统中。
虽然 StreamFlow 作用于连续空间而非离散 token,但其因果噪声调度的核心思想让时间轴上较早的位置比较晚的位置更”干净”——与 Diffusion Forcing 异曲同工,可以作为离散 Diffusion TTS 流式化的重要参考。
讨论小结
对于 OmniVoice 而言,将 Block Diffusion 与其现有的 full-codebook random masking 训练策略结合,可能是最值得探索的技术路径(在 block 内保留全 codebook 并行去噪,block 间按自回归顺序流式输出)。另外,结合延伸讨论一中的 Canvas Initialization 问题,Block Diffusion 实际上是同时给出了两个问题的答案:不需要预知全序列长度(逐 block 生成,按需终止),也不需要等待全序列完成(逐 block 输出,实现流式),这使得 Block Diffusion 可能算是离散 Diffusion TTS 这个方向上从”能用”走向”落地”的比较有前景的技术方案之一。
参考文献
- LLM2Vec: Large Language Models Are Secretly Powerful Text Encoders. arXiv:2404.05961
- LLaDA: Large Language Diffusion with mAsking. arXiv:2502.09992
- Difformer: Empowering Diffusion Models on the Embedding Space for Text Generation. arXiv:2212.09412
- Diffusion Language Models Are Natively Length-Aware. arXiv:2603.06123
- Block Diffusion: Interpolating Between Autoregressive and Diffusion Language Models. arXiv:2503.09573
- Diffusion Forcing: Next-token Prediction Meets Full-Sequence Diffusion. arXiv:2407.01392
- StreamFlow: Streaming Latent Flow Matching for Audio Generation. OpenReview
- 本文标题:语音合成 | OmniVoice:基于离散 Diffusion LLM 的 TTS
- 创建时间:2026-04-03
- 本文链接:2026/2026-04-03-omnivoice/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!